




文章目录
Reconstruction Component
可以把手写数字识别中的数字看做是由类似于笔画的basic component组成的,这个basic component set包含了能够构成所有数字的基本笔画。也就是说,basic component集合代表着数字所具有的所有基本特征,每个数字由这些基本特征组成,具有或不具有某个特征。
已知basic component set
[
u
1
u
2
u
3
.
.
.
u
k
]
\left [\begin{matrix}u^1\ u^2\ u^3...u^k\end{matrix} \right]
[u1 u2 u3...uk],则手写数字图片
x
x
x的表达式:
x
≈
c
1
u
1
+
c
2
u
2
+
.
.
.
+
c
k
u
k
+
x
ˉ
x≈c_1u^1+c_2u^2+...+c_ku^k+\bar x
x≈c1u1+c2u2+...+ckuk+xˉ
- [ c 1 c 2 c 3 . . . c k ] \left [\begin{matrix}c_1\ c_2\ c_3...c_k \end{matrix} \right] [c1 c2 c3...ck]表示图像 x x x在每个basic component上的权值
- x ˉ \bar x xˉ表示所有image的平均值
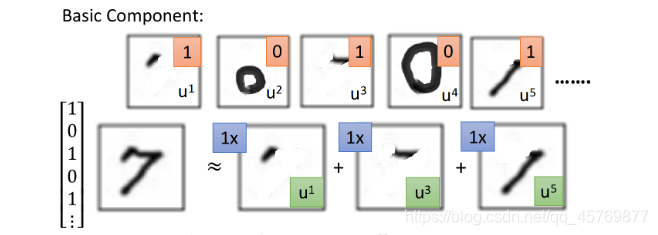
例如假设手写数字识别的basic component set是
[
u
1
u
2
u
3
u
4
u
5
]
\left [\begin{matrix}u^1\ u^2\ u^3\ u^4\ u^5\end{matrix} \right]
[u1 u2 u3 u4 u5],对于手写数字7来说它可以用
u
1
、
u
3
、
u
5
u^1、u^3、u^5
u1、u3、u5组合而成,那
[
c
1
c
2
c
3
c
4
c
5
]
=
[
1
0
1
0
1
]
\left [\begin{matrix}c_1\ c_2\ c_3\ c_4\ c_5 \end{matrix} \right]=\left [\begin{matrix}1\ 0\ 1\ 0\ 1 \end{matrix} \right]
[c1 c2 c3 c4 c5]=[1 0 1 0 1],最终表达式
x
=
u
1
+
u
3
+
u
5
x=u^1+u^3+u^5
x=u1+u3+u5。
Reconstruction error
- 经basic component重构后的图片与实际图片存在误差。假设经basic component重构得到图像
x
^
\hat x
x^:
x ^ = c 1 u 1 + c 2 u 2 + . . . + c k u k \hat x=c_1u^1+c_2u^2+...+c_ku^k x^=c1u1+c2u2+...+ckuk - 重构图片
x
^
\hat x
x^与实际图片
x
x
x的关系:
x − x ˉ ≈ c 1 u 1 + c 2 u 2 + . . . + c k u k = x ^ x-\bar x≈c_1u^1+c_2u^2+...+c_ku^k=\hat x x−xˉ≈c1u1+c2u2+...+ckuk=x^ - Reconstruction error:
∣ ∣ ( x − x ˉ ) − x ^ ∣ ∣ 2 ||(x-\bar x)-\hat x||_2 ∣∣(x−xˉ)−x^∣∣2
Reconstruction Component
如果basic component已知,以basic component为model,对 [ c 1 c 2 c 3 . . . c k ] \left [\begin{matrix}c_1\ c_2\ c_3...c_k \end{matrix} \right] [c1 c2 c3...ck]的每个element进行梯度下降或直接计算总可以找到最贴近于真实图片的重构图像。但实际上这些basic component并不已知,我们目的是找到basic component。
- 目标函数:
x ˉ = ∑ i = 1 k c i u i arg min u 1 , u 2 . . . , u k ∑ ∣ ∣ ( x − x ˉ ) − x ^ ∣ ∣ 2 \bar x=\sum\limits_{i=1}^k c_i u^i\\ {\underset {u^1,u^2...,u^k}{\operatorname {arg\ min} }}\sum||(x-\bar x)-\hat x||_2 xˉ=i=1∑kciuiu1,u2...,ukarg min∑∣∣(x−xˉ)−x^∣∣2
Reconstruction Component矩阵表示
x − x ˉ ≈ [ u 1 u 2 . . . u k ] [ c 1 c 2 . . . c k ] \begin{aligned} &x-\bar x≈ \left [ \begin{matrix} u_1\ u_2\ ...\ u_k \end{matrix} \right ] \left [ \begin{matrix} c_1\\ c_2\\ ...\\ c_k \end{matrix} \right ] \end{aligned} x−xˉ≈[u1 u2 ... uk]⎣⎢⎢⎡c1c2...ck⎦⎥⎥⎤
- component u i u_i ui为列向量,其维度与原始图像 x x x维度相同
- weight
c
i
c_i
ci为标量
x − x ˉ ≈ [ u 1 1 u 2 1 . . . u k 1 u 1 2 u 2 2 . . . u k 2 . . . u 1 n u 2 n . . . u k n ] [ c 1 c 2 . . . c k ] \begin{aligned} &x-\bar x≈ \left [ \begin{matrix} u_1^1\ u_2^1\ ... u_k^1 \\ u_1^2\ u_2^2\ ... u_k^2 \\ ...\\ u_1^n\ u_2^n\ ... u_k^n \end{matrix} \right ] \left [ \begin{matrix} c_1\\ c_2\\ ...\\ c_k \end{matrix} \right ] \end{aligned} x−xˉ≈⎣⎢⎢⎡u11 u21 ...uk1u12 u22 ...uk2...u1n u2n ...ukn⎦⎥⎥⎤⎣⎢⎢⎡c1c2...ck⎦⎥⎥⎤ - 将component展开,上标标识不同vector,下标表示vector中的element
[ x 1 − x ˉ x 2 − x ˉ . . . x n − x ˉ ] ≈ [ u 1 1 u 2 1 . . . u k 1 u 1 2 u 2 2 . . . u k 2 . . . u 1 n u 2 n . . . u k n ] [ c 1 1 c 1 2 . . . c 1 n c 2 1 c 2 2 . . . c 2 n . . . c k 1 c k 2 . . . c k n ] \begin{aligned} &\left [ \begin{matrix} x_1-\bar x\\ x_2-\bar x\\ ...\\ x_n-\bar x \end{matrix} \right ]≈\left [ \begin{matrix} u_1^1\ u_2^1\ ... u_k^1 \\ u_1^2\ u_2^2\ ... u_k^2 \\ ...\\ u_1^n\ u_2^n\ ... u_k^n \end{matrix} \right ] \left [ \begin{matrix} c_1^1\ c_1^2\ ... c_1^n\\ c_2^1\ c_2^2\ ... c_2^n\\ ...\\ c_k^1\ c_k^2\ ... c_k^n \end{matrix} \right ] \end{aligned} ⎣⎢⎢⎡x1−xˉx2−xˉ...xn−xˉ⎦⎥⎥⎤≈⎣⎢⎢⎡u11 u21 ...uk1u12 u22 ...uk2...u1n u2n ...ukn⎦⎥⎥⎤⎣⎢⎢⎡c11 c12 ...c1nc21 c22 ...c2n...ck1 ck2 ...ckn⎦⎥⎥⎤
- 多数据重构表示,共有 n n n个object,用 k k k个component表示
SVD(奇异值分解)
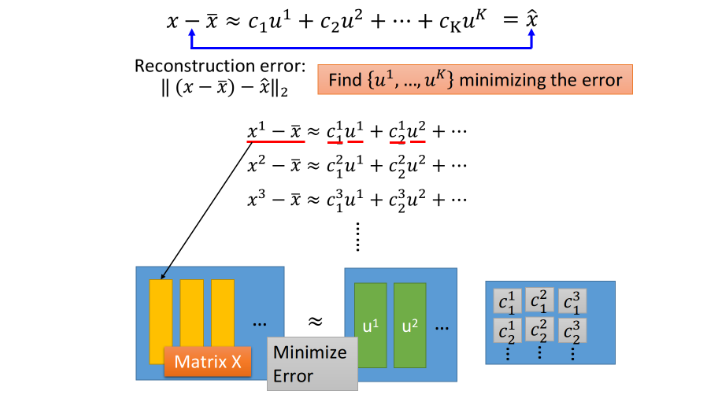 Reconstruction Component矩阵 Reconstruction Component矩阵
|
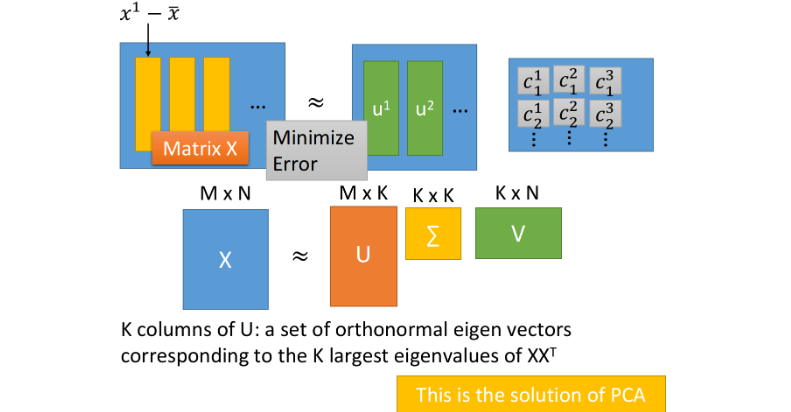 SVD SVD
|
- 可以使用SVD将每个matrix X m × n X_{m×n} Xm×n都拆成matrix U m × k U_{m×k} Um×k、 Σ k × k \Sigma_{k×k} Σk×k、 V k × n V_{k×n} Vk×n的乘积,其中k为component的数目
- 使用SVD拆解后的三个矩阵相乘,是跟等号左边的矩阵 X X X最接近的,此时 U U U就对应着 u i u^i ui那部分的矩阵, Σ ⋅ V \Sigma\cdot V Σ⋅V就对应着 c k i c_k^i cki那部分的矩阵
- 根据SVD的结论,组成矩阵 U U U的k个列向量(标准正交向量, orthonormal vector)就是 X X T XX^T XXT最大的k个特征值(eignvalue)所对应的特征向量(eigenvector),而 X X T XX^T XXT实际上就是 x x x的covariance matrix,因此 U U U就是PCA的k个解
- 因此我们可以发现,通过PCA找出来的Dimension Reduction的transform,实际上就是把 X X X拆解成能够最小化Reconstruction error的component的过程,通过PCA所得到的 w i w^i wi就是component u i u^i ui,而Dimension Reduction的结果就是参数 c i c_i ci
- 简单来说就是,用PCA对 x x x进行降维的过程中,我们要找的投影方式 w i w^i wi就相当于恰当的组件 u i u^i ui,投影结果 z i z^i zi就相当于这些组件各自所占的比例 c i c_i ci
结论:用PCA找出来的投影方向 { w 1 , w 2 , . . . , w k } \{w^1,w^2,...,w^k\} {w1,w2,...,wk}就是Reconstruction Component { u 1 , u 2 , . . . , u k } \{u^1,u^2,...,u^k\} {u1,u2,...,uk}
PCA in Neuron Network
假设用PCA或SVD找到了
k
k
k个最优投影方向
{
w
1
,
w
2
,
.
.
.
,
w
k
}
\{w^1,w^2,...,w^k\}
{w1,w2,...,wk},由
x
−
x
ˉ
=
[
u
1
u
2
.
.
.
u
k
]
[
c
1
c
2
.
.
.
c
k
]
\begin{aligned} &x-\bar x= \left [ \begin{matrix} u_1\ u_2\ ...\ u_k \end{matrix} \right ] \left [ \begin{matrix} c_1\\ c_2\\ ...\\ c_k \end{matrix} \right ] \end{aligned}
x−xˉ=[u1 u2 ... uk]⎣⎢⎢⎡c1c2...ck⎦⎥⎥⎤
得到object在新空间上的投影(或者说在component上的权值)
[
c
1
c
2
.
.
.
c
k
]
=
(
x
−
x
ˉ
)
[
u
1
u
2
.
.
.
u
k
]
\begin{aligned} &\left [ \begin{matrix} c_1\\ c_2\\ ...\\ c_k \end{matrix} \right ]= (x-\bar x) \left [ \begin{matrix} u_1\ u_2\ ...\ u_k \end{matrix} \right ] \end{aligned}
⎣⎢⎢⎡c1c2...ck⎦⎥⎥⎤=(x−xˉ)[u1 u2 ... uk]
上述矩阵计算过程可以被表示成NN,其形式如下图。
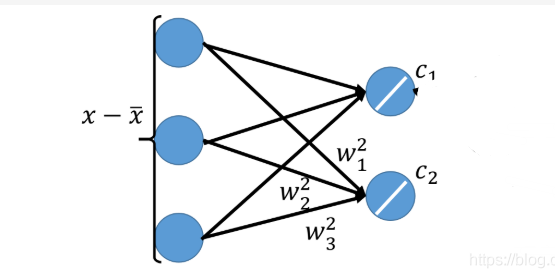 矩阵计算的NN表示 矩阵计算的NN表示
|
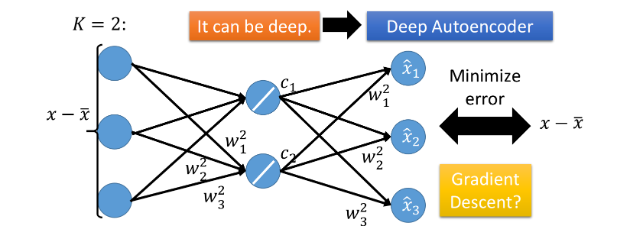 training method—Autoencoder training method—Autoencoder
|
此时,PCA就被表示成了只含一层hidden layer的神经网络,hidden layer是线性的激活函数,hidden layer的输入权值是投影方向,hidden layer的输出相当于对object进行编码,训练目标是让这个NN的input x − x ˉ x-\bar x x−xˉ与output x ^ \hat x x^越接近越好,这件事就叫做Autoencoder(训练一个model,让它的输入等于输出,取出中间的某个隐藏层作为降维的结果)。
PCA与RNN的区别
通过PCA求解出的 w i w^i wi与直接对上述的神经网络做梯度下降所解得的 w i w^i wi是会不一样的,因为PCA解出的 w i w^i wi是相互垂直的(orgonormal),而用NN的方式得到的解无法保证 w i w^i wi相互垂直,NN无法做到Reconstruction error比PCA小,因此:
- 在linear的情况下,直接用PCA找 W W W远比用神经网络的方式更快速方便
- 用NN的好处是,它可以使用不止一层hidden layer,它可以做deep autoencoder
Weakness of PCA
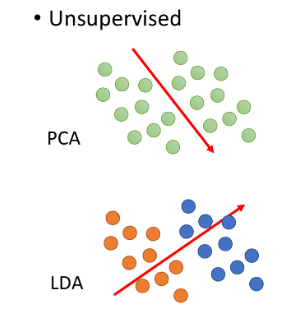
PCA有很明显的弱点:
|

|
-
PCA属于unsupervised,它单纯依据数据分布找出特征(LDA是考虑了labeled data后进行降维,但属于supervised)。
-
PCA是linear的,对于图中的彩色曲面,PCA只能做到把这个曲面打扁压在平面上,我们期望把它平铺拉直进行降维,但这是一个non-linear的投影转换,对类似曲面空间的降维投影,需要用到non-linear transformation。
PCA Example
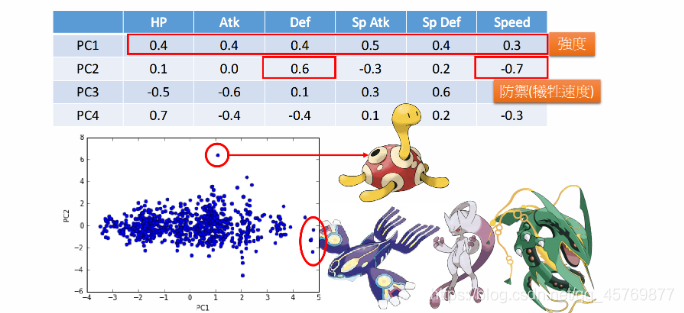
PCA—Pokemon
假设总共有800只宝可梦,每只都是一个六维度的样本点,即vector={HP, Atk, Def, Sp Atk, Sp Def, Speed}。宝可梦样本数据的 C o v ( x ) Cov(x) Cov(x)是6维,最多可以投影到6维空间,可以先找出6个特征向量和对应的特征值 λ i \lambda_i λi,其中 λ i \lambda_i λi表示第i个投影维度的variance有多大,然后我们就可以计算出每个 λ i \lambda_i λi的比重ratio= λ i ∑ i = 1 6 λ i \frac{\lambda_i}{\sum\limits_{i=1}^6 \lambda_i} i=1∑6λiλi。

从上图的ratio可以看出
λ
5
\lambda_5
λ5、
λ
6
\lambda_6
λ6所占比例不高,即第5和第6个principle component(可以理解为维度)的影响比较小,用这两个dimension做投影所得到的variance很小,投影在这两个方向上的点比较集中,无法对区分宝可梦的特性做出太大的贡献,所以我们只需要利用前4个principle component即可。
新的维度上就是旧的维度的加权矢量和,从PC1到PC4这4个principle component都是6维度加权的vector,它们代表某种特性。
-
PC1来说,每个值都是正的,因此这个组件在某种程度上代表了宝可梦的强度
-
PC2来说,防御力Def很大而速度Speed很小,这个组件可以增加宝可梦的防御力但同时会牺牲一部分的速度
PCA—MNIST
对28×28的
C
o
v
(
x
)
=
1
N
∑
(
x
−
x
ˉ
)
(
x
−
x
ˉ
)
T
Cov(x)=\frac{1}{N}\sum (x-\bar x)(x-\bar x)^T
Cov(x)=N1∑(x−xˉ)(x−xˉ)T取前30个最大的特征值对应的特征向量。

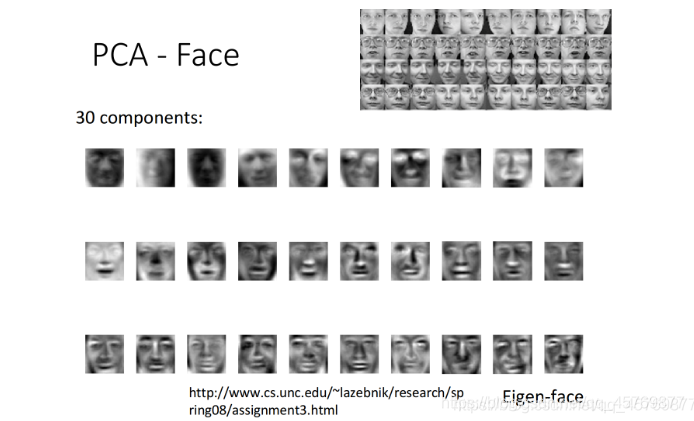
PCA—Face
对 C o v ( x ) Cov(x) Cov(x)取前30个最大的特征值对应的特征向量。
NMF
NMF(non-negative matrix factorization),非负矩阵分解。PCA可以看成对原始矩阵 X X X做SVD进行矩阵分解,但并不保证分解后矩阵的正负,实际上当进行图像处理时,如果部分组件的matrix包含一些负值的话,如何处理负的像素值也会成为一个问题(归一化处理比较麻烦)。
 NMF on MINST NMF on MINST
|
 NMF on Face NMF on Face
|
More Related Approaches
降维的方法有很多,这里列举一些与PCA有关的方法:
-
Multidimensional Scaling (MDS) [Alpaydin, Chapter 6.7]
MDS不需要把每个data都表示成feature vector,只需要知道特征向量之间的distance,就可以做降维,PCA保留了原来在高维空间中的距离,在某种情况下MDS就是特殊的PCA
-
Probabilistic PCA [Bishop, Chapter 12.2]
PCA概率版本
-
Kernel PCA [Bishop, Chapter 12.3]
PCA非线性版本
-
Canonical Correlation Analysis (CCA) [Alpaydin, Chapter 6.9]
CCA常用于两种不同的data source的情况,比如同时对声音信号和唇形的图像进行降维
-
Independent Component Analysis (ICA)
ICA常用于source separation,PCA找的是正交的组件,而ICA则只需要找“独立”的组件即可
-
Linear Discriminant Analysis (LDA) [Alpaydin, Chapter 6.8]
LDA是supervised的方式


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









