







 本文深入探讨神经网络中的梯度计算,包括交叉熵损失函数、总损失的计算以及梯度下降。介绍了前向传播(Forwardpass)和反向传播(Backwardpass)的概念,解释了如何通过链式法则计算损失函数对权重的偏导数。在输出层,使用softmax激活函数和交叉熵损失;在非输出层,继续沿用反向传播计算隐藏层的梯度。整个过程是梯度从输出层向输入层反向传播,用于权重更新和模型优化。
本文深入探讨神经网络中的梯度计算,包括交叉熵损失函数、总损失的计算以及梯度下降。介绍了前向传播(Forwardpass)和反向传播(Backwardpass)的概念,解释了如何通过链式法则计算损失函数对权重的偏导数。在输出层,使用softmax激活函数和交叉熵损失;在非输出层,继续沿用反向传播计算隐藏层的梯度。整个过程是梯度从输出层向输入层反向传播,用于权重更新和模型优化。
Review
cross entropy
l
(
y
,
y
^
)
=
−
∑
i
=
1
n
y
^
i
l
n
y
i
l(y,\hat{y})=-\sum\limits_{i=1}^{n}\hat{y}_i lny_i
l(y,y^)=−i=1∑ny^ilnyi
- y y y: 目标分类结果
- y ^ \hat{y} y^:预测分类结果
- n n n:表示分类类别数
Multi-class classification问题中,常采用cross entropy,判断分类的好坏,我们把training data里任意一个样本点 x n x^n xn送到neural network里面,输出一个预测标签 y n y^n yn,我们把这个output跟样本点本身的label标注的target y ^ n \hat{y}^n y^n作cross entropy,这个交叉熵定义了output y n y^n yn和target y ^ n \hat{y}^n y^n之间的距离 l n ( θ ) l^n(\theta) ln(θ),如果cross entropy比较大的话,说明output和target之间距离很远,以parameter为参数的network预测该样本的loss是比较大的。
total loss
L
(
θ
)
=
∑
n
=
1
N
l
n
(
θ
)
L(\theta)=\sum\limits_{n=1}^N l^n(\theta)
L(θ)=n=1∑Nln(θ)
- θ \theta θ:该network的参数,包括所有的 w w w和 b b b
- l n ( θ ) l^n(\theta ) ln(θ):以 θ \theta θ为参数的network预测值与目标值的cross entropy
- N N N:通常定义的 b a t c h s i z e batch\ size batch size,即更新一次参数所考虑的样本数量
- L ( θ ) L(\theta ) L(θ):对N个样本的cross entropy加和
通常一次考虑一个样本集合batch,对集合样本预测后求cross entropy加和后求得total loss,以total loss为标准求梯度对参数进行更新。这个样本集合大小batch size可以是一,这样就是随机梯度下降,batch size越大,考虑的样本越多,更新也就越稳定,速度也就越慢。
total loss的梯度
L
(
θ
)
L(\theta)
L(θ)对参数
w
w
w做偏微分,表达式如下:
∂
L
(
θ
)
∂
w
=
∑
n
=
1
N
∂
l
n
(
θ
)
∂
w
\frac{\partial L(\theta)}{\partial w}=\sum\limits_{n=1}^N\frac{\partial l^n(\theta)}{\partial w}
∂w∂L(θ)=n=1∑N∂w∂ln(θ)
每一次参数的更新的梯度,是对一个batch中的各个数据的损失梯度
∂
l
n
(
θ
)
∂
w
\frac{\partial l^n(\theta)}{\partial w}
∂w∂ln(θ)的加和,即预测模型对一个batch中个数据预测的cross entropy对参数
w
w
w的偏微分累计求和,作为total loss对某一个参数
w
w
w的梯度。
Gradient
loss funcation对neuron参数
w
w
w的偏导:
∂
l
∂
w
=
∂
z
∂
w
∂
l
∂
z
\frac{\partial l}{\partial w}=\frac{\partial z}{\partial w} \frac{\partial l}{\partial z}
∂w∂l=∂w∂z∂z∂l
- l l l:某一样本预测值的cross entropy
- ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z:称之为Forward pass
- ∂ l ∂ z \frac{\partial l}{\partial z} ∂z∂l:称之为Backward pass
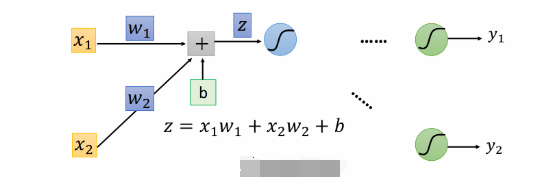
假设前一层有两个input x 1 , x 2 x_1,x_2 x1,x2,这个neuron的计算过程:
- 经过连接权值 w w w和偏置 b b b处理后的结果 z = b + w 1 x 1 + w 2 x 2 z=b+w_1 x_1+w_2 x_2 z=b+w1x1+w2x2
- z z z经过激励函数得到输出 a = f ( z ) a=f(z) a=f(z),作为neuron的output
∂
l
∂
w
\frac{\partial l}{\partial w}
∂w∂l作为loss funcation对neuron上
w
w
w的偏导,按照chain rule,可以把它拆分成两项,
∂
l
∂
w
=
∂
z
∂
w
∂
l
∂
z
\frac{\partial l}{\partial w}=\frac{\partial z}{\partial w} \frac{\partial l}{\partial z}
∂w∂l=∂w∂z∂z∂l,前一项
∂
z
∂
w
\frac{\partial z}{\partial w}
∂w∂z的过程称为Forward pass;后一项
∂
l
∂
z
\frac{\partial l}{\partial z}
∂z∂l的过程称为Backward pass。
Forward pass
z = b + w 1 x 1 + w 2 x 2 z=b+w_1 x_1+w_2 x_2 z=b+w1x1+w2x2,那么 ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z这一项,可以直接看出来, ∂ z ∂ w 1 = x 1 , ∂ z ∂ w 2 = x 2 \frac{\partial z}{\partial w_1}=x_1 ,\ \frac{\partial z}{\partial w_2}=x_2 ∂w1∂z=x1, ∂w2∂z=x2
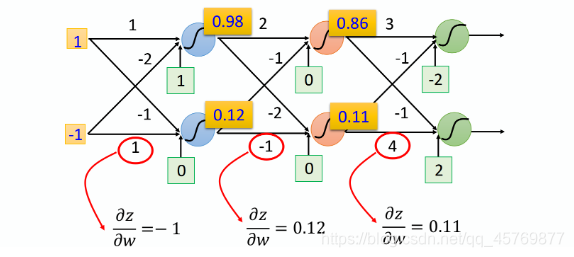
它的规律是:求
∂
z
∂
w
\frac{\partial z}{\partial w}
∂w∂z,就是看
w
w
w前面连接的input是什么,那微分后的
∂
z
∂
w
\frac{\partial z}{\partial w}
∂w∂z就是什么,因此只要计算出neural network里面每一层的outpu就可以作为下一层neuron中
z
z
z对
w
w
w的偏微分,因此在network前向计算的时候,
∂
z
∂
w
\frac{\partial z}{\partial w}
∂w∂z就已经被求出来。
Backward pass
计算
∂
l
∂
z
\frac{\partial l}{\partial z}
∂z∂l这一项,考虑
z
z
z对loss funcation
l
l
l的影响:首先,
z
z
z通过激励函数后的output;其次,output作为下一层的neuron的input,参与到下一层的neuron的计算中,以此递推,直到output layer。
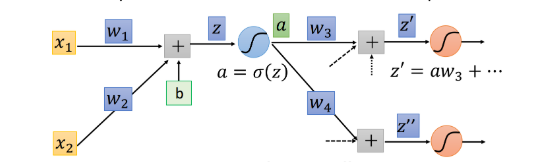
考虑1:假设激励函数为sigmoid函数,这个neuron的output
a
=
σ
(
z
)
a=\sigma(z)
a=σ(z),那么链式法则分解后:
∂
l
∂
z
=
∂
a
∂
z
∂
l
∂
a
=
σ
′
(
z
)
∂
l
∂
a
\frac{\partial l}{\partial z}=\frac{\partial a}{\partial z} \frac{\partial l}{\partial a}=\sigma'(z)\frac{\partial l}{\partial a}
∂z∂l=∂z∂a∂a∂l=σ′(z)∂a∂l
- ∂ a ∂ z \frac{\partial a}{\partial z} ∂z∂a:激励函数对 z z z的偏微分,可直接计算 σ ′ ( z ) \sigma'(z) σ′(z)
- ∂ l ∂ a \frac{\partial l}{\partial a} ∂a∂l:损失函数对output a a a的偏微分
考虑2:假设下一层只有两个neuron与本neuron相连,那么本neuron也就是通过这两个neuron传播它的影响,方式是将本neuron的output
a
a
a作为下一层两个neuron的输入,即以下两个公式(两条路径):
z
′
=
w
3
a
+
.
.
.
z
′
′
=
w
4
a
+
.
.
.
z'=w_3a+...\\ z''=w_4a+...
z′=w3a+...z′′=w4a+...
- z ′ z' z′和 z ′ ′ z'' z′′当然还有其他输入,但与计算本neuron的影响无关,用 . . . ... ...代替
链式法则分解后
∂
l
∂
a
=
∂
z
′
∂
a
∂
l
∂
z
′
+
∂
z
′
′
∂
a
∂
l
∂
z
′
′
=
w
3
∂
l
∂
z
′
+
w
4
∂
l
∂
z
′
′
\frac{\partial l}{\partial a}=\frac{\partial z'}{\partial a} \frac{\partial l}{\partial z'}+\frac{\partial z''}{\partial a} \frac{\partial l}{\partial z''}=w_3\frac{\partial l}{\partial z'}+w_4\frac{\partial l}{\partial z''}
∂a∂l=∂a∂z′∂z′∂l+∂a∂z′′∂z′′∂l=w3∂z′∂l+w4∂z′′∂l
这里先假设我们已经通过某种方法把
∂
l
∂
z
′
\frac{\partial l}{\partial z'}
∂z′∂l和
∂
l
∂
z
′
′
\frac{\partial l}{\partial z''}
∂z′′∂l这两项给算出来了,那么
∂
l
∂
z
=
∂
a
∂
z
∂
l
∂
a
=
σ
′
(
z
)
[
w
3
∂
l
∂
z
′
+
w
4
∂
l
∂
z
′
′
]
\frac{\partial l}{\partial z}=\frac{\partial a}{\partial z} \frac{\partial l}{\partial a}=\sigma'(z)[w_3 \frac{\partial l}{\partial z'}+w_4 \frac{\partial l}{\partial z''}]
∂z∂l=∂z∂a∂a∂l=σ′(z)[w3∂z′∂l+w4∂z′′∂l]
那么Backward pass这一部分可以看做梯度从后往前的传播
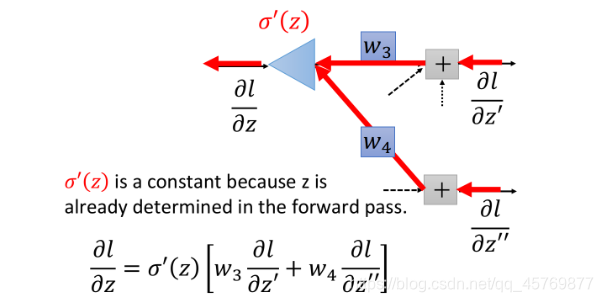
现在我们最后需要解决的问题是,怎么计算 ∂ l ∂ z ′ \frac{\partial l}{\partial z'} ∂z′∂l和 ∂ l ∂ z ′ ′ \frac{\partial l}{\partial z''} ∂z′′∂l这两项,有两个不同的case:
case 1:Output Layer
假设计算的这个neuron已经是hidden layer的最后一层了,
z
′
z'
z′和
z
′
′
z''
z′′所在的两个neuron是output layer,output layer做softmax处理后输出预测值,有了预测值,即可与目标计算损失。
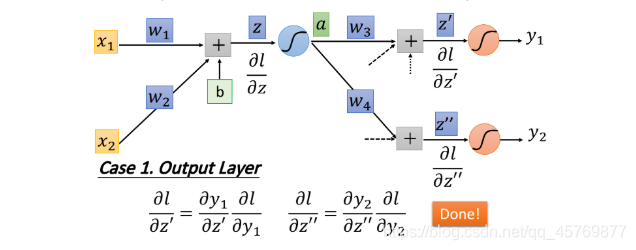
l
l
l对于
z
′
z'
z′的偏微分:
∂
l
∂
z
′
=
∂
y
1
∂
z
′
∂
l
∂
y
1
\frac{\partial l}{\partial z'}=\frac{\partial y_1}{\partial z'} \frac{\partial l}{\partial y_1}
∂z′∂l=∂z′∂y1∂y1∂l
- y 1 y_1 y1: z ′ z' z′经softmax(activation function)之后的预测值输出
- ∂ y 1 ∂ z ′ \frac{\partial y_1}{\partial z'} ∂z′∂y1:output layer的softmax函数对 z ′ z' z′的偏微分
- ∂ l ∂ y 1 \frac{\partial l}{\partial y_1} ∂y1∂l:loss funcation对 y 1 y_1 y1的偏微分,
- l l l:损失函数,可以是MSE或cross entropy等
Case 2:Not Output Layer
假设这个neuron不是hidden layer的最后一层,
z
′
z'
z′和
z
′
′
z''
z′′所在的两个neuron仍然属于hidden layer。
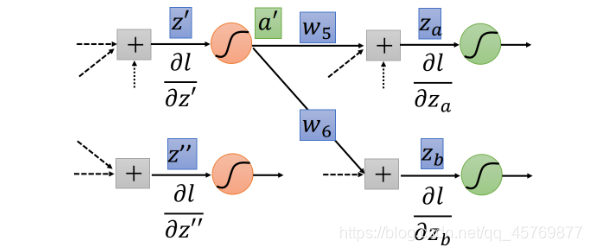
如果知道
∂
l
∂
z
a
\frac{\partial l}{\partial z_a}
∂za∂l和
∂
l
∂
z
b
\frac{\partial l}{\partial z_b}
∂zb∂l,我们就可以计算
l
l
l对于
z
′
z'
z′的偏微分:
∂
l
∂
z
′
=
σ
′
(
z
′
)
[
w
5
∂
l
∂
z
a
+
w
6
∂
l
∂
z
b
]
\frac{\partial l}{\partial z'}=\sigma'(z')[w_5 \frac{\partial l}{\partial z_a} + w_6 \frac{\partial l}{\partial z_b}]
∂z′∂l=σ′(z′)[w5∂za∂l+w6∂zb∂l]
Example
对于Backward pass的部分需要从后往前,首先计算output layer,然后从后往前依层递推计算hidden layer,
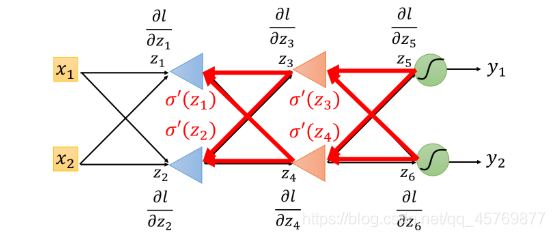
对于上图,整一个流程是,计算出
∂
l
∂
z
5
\frac{\partial l}{\partial z_5}
∂z5∂l和
∂
l
∂
z
6
\frac{\partial l}{\partial z_6}
∂z6∂l,然后再把这两个偏微分的值乘上路径上的weight汇集到neuron上面,再通过op-amp
σ
′
(
z
3
)
\sigma'(z_3)
σ′(z3)和
σ
′
(
z
4
)
\sigma'(z_4)
σ′(z4)放大,就可以得到
∂
l
∂
z
3
\frac{\partial l}{\partial z_3}
∂z3∂l和
∂
l
∂
z
4
\frac{\partial l}{\partial z_4}
∂z4∂l这两个偏微分的值,让它们乘上各自路径上的weight并通过op-amp
σ
′
(
z
1
)
\sigma'(z_1)
σ′(z1)和
σ
′
(
z
2
)
\sigma'(z_2)
σ′(z2),就得到
∂
l
∂
z
1
\frac{\partial l}{\partial z_1}
∂z1∂l和
∂
l
∂
z
2
\frac{\partial l}{\partial z_2}
∂z2∂l这两个偏微分的值,这样就计算完了,这个过程叫做Backward pass
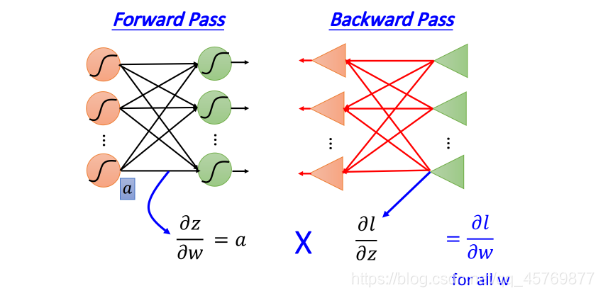
Summary
Forward pass:每个neuron的activation function的output,就是它所连接的weight的 ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z
Backward pass:可以看做与原方向相反的梯度network,它的三角形neuron的output就是 ∂ l ∂ z \frac{\partial l}{\partial z} ∂z∂l
把通过forward pass得到的
∂
z
∂
w
\frac{\partial z}{\partial w}
∂w∂z和通过backward pass得到的
∂
l
∂
z
\frac{\partial l}{\partial z}
∂z∂l乘起来就可以得到
l
l
l对
w
w
w的偏微分
∂
l
∂
w
\frac{\partial l}{\partial w}
∂w∂l
∂
l
∂
w
=
∂
z
∂
w
∣
f
o
r
w
a
r
d
p
a
s
s
⋅
∂
l
∂
z
∣
b
a
c
k
w
a
r
d
p
a
s
s
\frac{\partial l}{\partial w} = \frac{\partial z}{\partial w}|_{forward\ pass} \cdot \frac{\partial l}{\partial z}|_{backward \ pass}
∂w∂l=∂w∂z∣forward pass⋅∂z∂l∣backward pass


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









