







 本文详细介绍了模型性能度量的重要指标,包括误差、误差期望值及其组成:样本噪声、模型预测值的方差和偏差。通过误差期望值公式阐述了模型复杂度与偏差、方差的关系,并分析了偏差与方差在训练集上的体现。针对欠拟合(高偏差、低方差)和过拟合(低偏差、高方差)问题,提出了相应的解决方案,如增加模型复杂度、正则化等。
本文详细介绍了模型性能度量的重要指标,包括误差、误差期望值及其组成:样本噪声、模型预测值的方差和偏差。通过误差期望值公式阐述了模型复杂度与偏差、方差的关系,并分析了偏差与方差在训练集上的体现。针对欠拟合(高偏差、低方差)和过拟合(低偏差、高方差)问题,提出了相应的解决方案,如增加模型复杂度、正则化等。
模型性能度量
在监督学习中,通过已知样本数据 ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) (x1,y1),(x2,y2),...,(x_n,y_n) (x1,y1),(x2,y2),...,(xn,yn),要求在设定好的模型上训练参数,拟合出一个最好的函数 f ^ \widehat{f} f ,使得预测值 f ^ ( x ) \widehat{f}(x) f (x)与实际值 y y y的误差最小。性能测试时,使用拟合函数 f ^ \widehat{f} f 对样本数据预测,可以采用均方误差MSE来判断其拟合程度的好坏。
误差
误差来源于三方面:
样本噪声:样本数据由采样而来,
y
y
y并不是真实值本身,假设真实模型(函数)是
f
f
f,则采样值
y
=
f
(
x
)
+
ε
y=f(x)+ε
y=f(x)+ε,其中ε代表噪音,其均值为0,方差为
σ
2
σ^2
σ2
模型预测值的方差:采用特定模型,每次在样本中随机选取固定大小的训练集进行训练,假设n次训练后得到n个函数
f
^
\widehat{f}
f
,用这n个函数对样本预测得到n个预测值
f
^
(
x
)
\widehat{f}(x)
f
(x),这n个预测值的方差即为预测模型的方差
模型预测值的偏差:对这n个预测值
f
^
(
x
)
\widehat{f}(x)
f
(x)取平均后得到预测值期望
E
(
f
^
(
x
)
)
E(\widehat{f}(x))
E(f
(x)),作为我们最终的预测结果,
E
(
f
^
(
x
)
)
E(\widehat{f}(x))
E(f
(x))与真实值
f
(
x
)
f(x)
f(x)的距离即为偏差
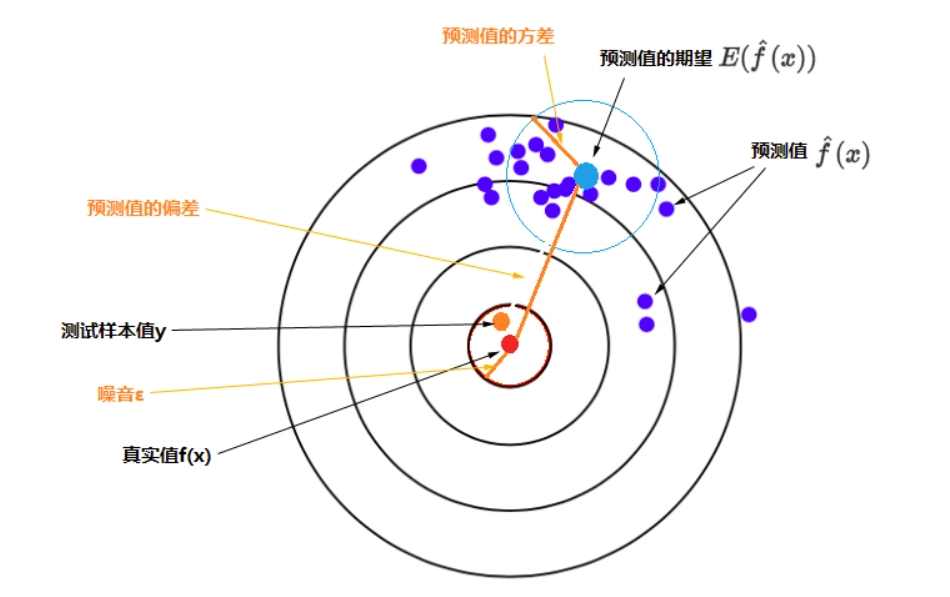
误差期望值
期望值的含义是指在同样的条件下重复多次随机试验,得到的所有可能状态的平均结果。对于机器学习来说,这种实验就是我们选择一种算法(并选定超参数),以及设置一个固定的训练集大小,这就是同样的条件,也就是上文所说的特定的模型。然后每次训练时从样本空间中选择一批样本作为训练集,但每次都随机抽取不同的样本,这样重复进行多次训练。每次训练会得到一个具体的模型,每个具体模型对同一个未见过的样本进行预测可以得到预测值。不断重复训练和预测,就能得到一系列预测值,根据样本和这些预测值计算出方差和偏差,就可以帮助我们考察该特定模型的预测误差的期望值,也就能衡量该特定模型的性能。对比多个特定模型的误差的期望值,可以帮助我们选择合适的模型。
误差期望值公式
误差的期望值 = 噪音的方差 + 模型预测值的方差 + 模型预测值的偏差的平方
E
(
(
y
−
f
^
(
x
)
)
2
)
=
σ
2
+
V
a
r
[
f
^
(
x
)
]
+
(
B
i
a
s
[
f
^
(
x
)
]
)
2
E((y - \widehat{f}(x))^2) = σ^2+Var[\widehat{f}(x)] + (Bias[\widehat{f}(x)])^2
E((y−f
(x))2)=σ2+Var[f
(x)]+(Bias[f
(x)])2
误差分析案例
偏差 - 方差在训练集上的体现
方差与偏差是由model的复杂程度决定的,一个简单的model在不同的training data set下可以获得比较稳定分布的 f ^ \widehat{f} f ,而复杂的model在不同的training data set下的分布比较散乱(如果data足够多,那复杂的model也可以得到比较稳定的分布)。
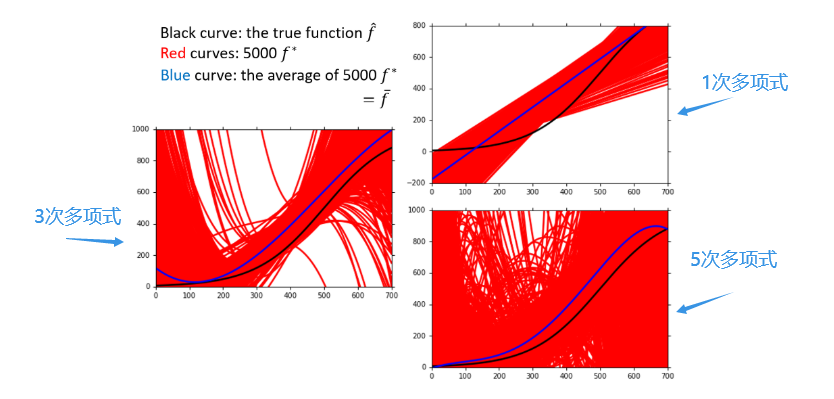
直观得可以看出,如果采用简单的model,那么每次实验所得 f ^ \widehat{f} f 之间的variance是比较小,而bias可能比较大;如果采用复杂的model,那么每次实验所得 f ^ \widehat{f} f 之间的variance是比较大,而bias比较小。
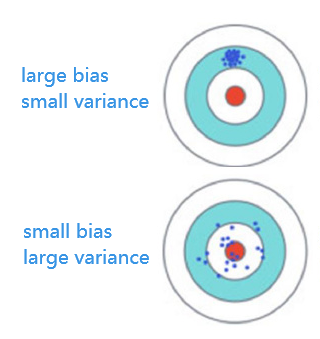
因为简单的model(没有高次项的model,或者高次项的系数非常小的model)受到个别的data的影响是比较小的,对个别data的敏感度较小,最终表现得会比较平滑,而复杂的model对个别data的较为敏感,在个别data的身上学得的东西较多,这就导致简单的model对data的拟合程度并不是很好导致其bias较大,但每次训练得到的 f ^ \widehat{f} f 分布比较稳定因而其variance较小,复杂model相反。
偏差 - 方差与拟合的关系
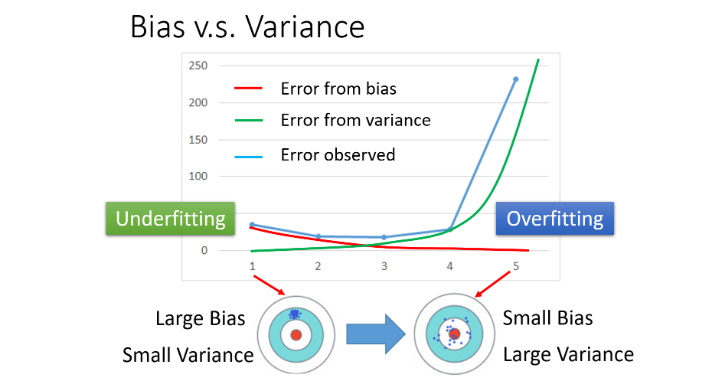
随着model越来越复杂,bias会逐渐减少,而variance则逐渐增加,总体误差呈先减后增趋势。
简单模型(左边)是偏差比较大造成的误差,这种情况叫做欠拟合,而复杂模型(右边)是方差过大造成的误差,这种情况叫做过拟合。
如何处理
对于偏差大(欠拟合)
- 考虑更多的属性和因素
- 考虑更复杂的模型
- 如果此时强行再收集更多的data去训练,这是没有什么帮助的,因为设计的函数集本身就不好,再找更多的训练集也不会更好。
对于方差大(过拟合)
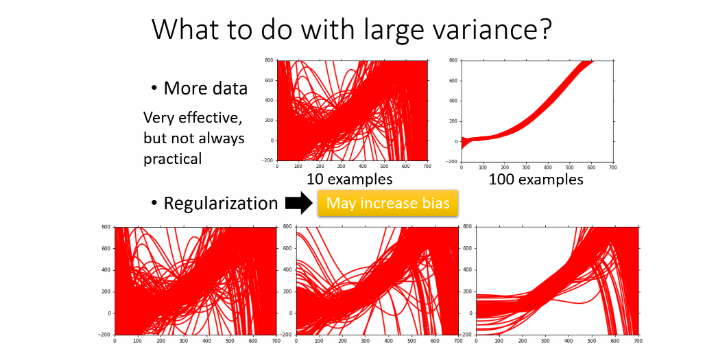
- 降低模型复杂度
- 更多的数据
- 添加正则项
加了regularization以后,强迫所有的曲线都要比较平滑,所以这个时候也会让你的variance变小;但regularization可能伤害bias,因为它实际上调整了function set的space范围,变成它只包含那些比较平滑的曲线。
Summary
| 多项式次数 | 模型复杂度 | 偏差 | 方差 | 训练误差 | 测试误差 | 拟合 |
|---|---|---|---|---|---|---|
| 高 | 高 | 低 | 高 | 低 | 高 | 过拟合 |
| 低 | 低 | 高 | 低 | 高 | 高 | 欠拟合 |

















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









