






 本文介绍了Docker的常用命令,如安装、启动、停止和管理容器,并对比了Docker与传统Linux安装软件的区别。此外,讨论了数据库分库分表的原因,包括垂直分表和水平分库分表的策略,以及它们在解决性能问题上的作用。同时,提到了分库分表带来的挑战,如分布式事务、主键冲突和跨节点查询,并指出可以通过Sharding-JDBC和mycat等技术来解决这些问题。
本文介绍了Docker的常用命令,如安装、启动、停止和管理容器,并对比了Docker与传统Linux安装软件的区别。此外,讨论了数据库分库分表的原因,包括垂直分表和水平分库分表的策略,以及它们在解决性能问题上的作用。同时,提到了分库分表带来的挑战,如分布式事务、主键冲突和跨节点查询,并指出可以通过Sharding-JDBC和mycat等技术来解决这些问题。
1 docker常用命令
Yum install docker 安装docker
Systemctl status docker 查看当前docker的状态(运行状态、关闭状态)
Systemctl start docker 启动
Systemctl stop docker 停止
Systemctl restart docker 重启
2 docker 操作软件
Docker search mysql/redis/activeMQ 搜索软件,以供安装
Docker pull 软件名字 安装软件
Docker images 查看已经已经下载的软件
Docker rmi 镜像名字:删除镜像images
Docker run -it --name=xxx centos:7 /bin/bash 创建容器,第一次运行软件:交互式容器,
Docker run -di --name= xxx centos:7 创建容器,第一次运行软件:守护式容器
Docker ps :查看当前运行的集装箱
Docker ps -a:查看所有的集装箱(运行+不运行的)
Docker start 容器名字:第二次启动容器,根据名字
Docker stop 容器名字:停止运行的容器,根据名字
Docker rm 容器名字: 删除容器
3、 linux安装软件和docker安装软件的区别:
1、linux安装软件,可能会产生软件冲突:端口冲突、快捷键冲突、环境冲突
2、docker安装软件,docker提供的是独立集装箱,每个集装箱里面装的是最简化的linux系 统,在这个linux系统上安装软件,集装箱之间互相独立
4 docker 跟maven一样,有中央仓库,有私服
Docker中央仓库:在docker安装的软件来自哪里?
Maven中央仓库:jar来自哪里?
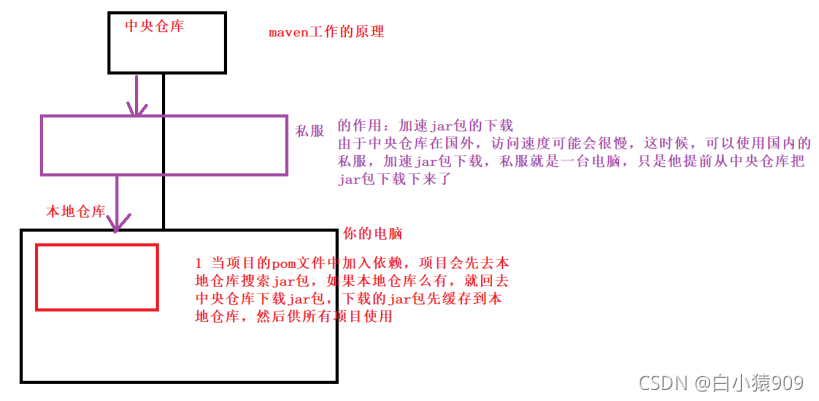
5 为什么需要分库分表?
随着公司业务快速发展,数据库中的数据量增大,访问性能也变慢了,虽然通过机器集群,sql优化,性能调优等方式在一定程度上可以起到提高性能的作用,但是并不能从根本上解决单库,单表数据量过大的问题。
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的
6.为什么要垂直分表?
因为数据的访问频次不同,所以可以根据数据的冷热进行表结构的拆分,从而提升性能
7.垂直分表的依据?
1、把不常用的字段单独放在一张表;
2、把text ,blob等大字段拆分出来放在附表中;
3、经常组合查询的列放在一张表中;
8、什么是垂直分库?
垂直分库是指按照业务将表进行分类 ,分布到不同的数据库上面 ,每个库可以放在不同的服务器上 ,它的核心理念 是专库专用。(以前的微服务的分库方式)
9、什么是水平分库
当一个应用难以垂直切分 ,或切分后数据量巨大 ,存在单库读写、 存储性能瓶颈 ,这时候就需要进行水平分库 ,经过水平切分的优化 ,往往能解决单库存储量及性能瓶颈。 但由于同一个表被分配在不同的数据库,需要额外进行数据操作,因此大大提升了系统复杂度。
水平分库是把同一个表的数据按一定规则(id%2)拆到不同的数据库中 ,每个库可以放在不同的服务器上。
10.水平分表
水平分表是在同一个数据库内 ,把同一个表的数据按一定规则拆到多个表中。
11.分库分表可以解决的问题有哪些?同时他又带来了哪些问题?
解决的问题:
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将大表拆分成若干小表,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
带来的问题:
1分布式事务:
2 主键重复:将原来的表分到不同表中
3 跨节点查询问题:排序和分页问题:找销量最高的10个商品的数据,需要去多个库的多个表中,联合搜索
这些问题通过Sharding-JDBC(当当网),mycat(alibaba)技术可以有效解决这些问题

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









