







 本文介绍了一种将MySQL中的大量数据高效导入Elasticsearch的方法,包括使用多线程技术进行数据预处理、分批插入等步骤,适用于不同环境下的数据迁移场景。
本文介绍了一种将MySQL中的大量数据高效导入Elasticsearch的方法,包括使用多线程技术进行数据预处理、分批插入等步骤,适用于不同环境下的数据迁移场景。
我的任务是将mysql里的 3044457 条数据导入到es中。其中六十五万的那个是主表,其他的是关联表。也就是说,最后es里需要有 654251 条数据。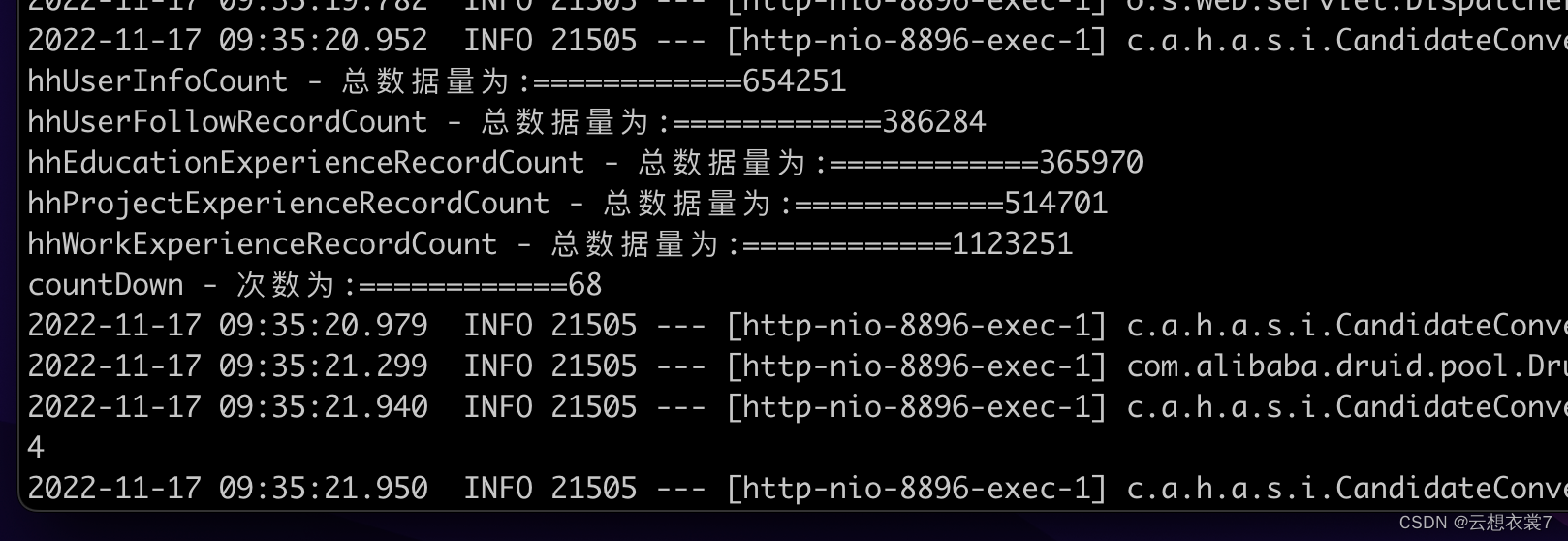
我的处理思路是将所有数据 使用多线程 全部读到内存里,预处理。然后使用多线程遍历、聚合主表数据,将数据批量插入到es中。在dev环境,mysql在本机,大概需要花三分钟。

在测试和生产环境,mysql 不在本机,大概需要十几二十分钟。
内存的占用情况,
程序运行前:
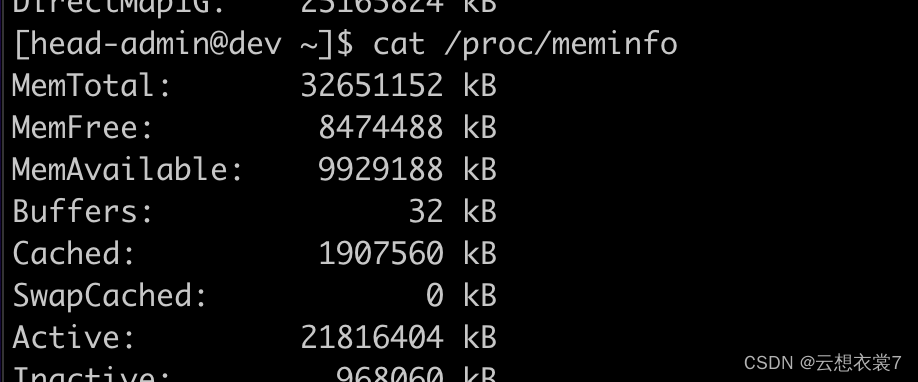
程序运行时:
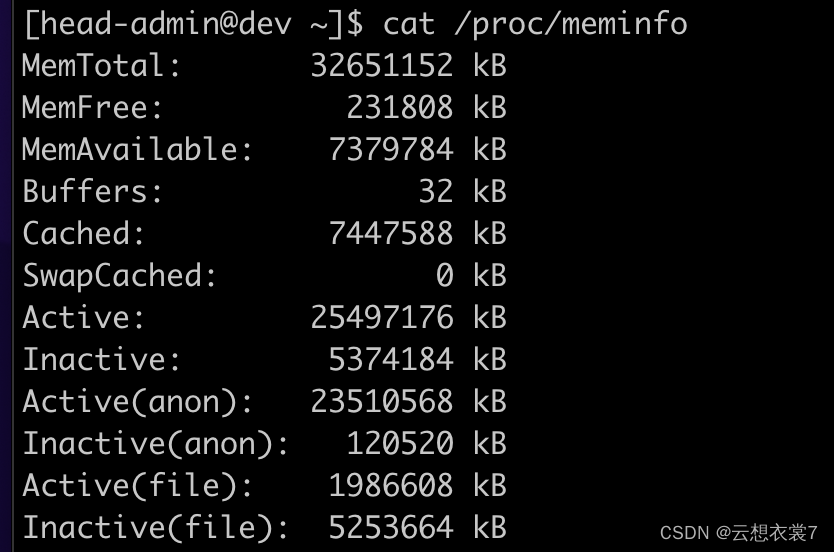
大概花了六个多G的内存,并且没有还回来。。。。图有点不准。(这台机器在六百万左右数据的时候就oom了)
关于 PAGE_SIZE 和 线程池的配置,看具体的机器而定。
private final Integer PAGE_SIZE = 50000;
int processors = Runtime.getRuntime().availableProcessors();
log.info("cpu的核心数量为:{}", processors);
threadPool = new ThreadPoolExecutor(6, 10, 4, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(500), new ThreadPoolExecutor.CallerRunsPolicy());
/**
*
* @param index 需要插入的索引名
*/
private void queryUserInfoIndexData(String index) {
long millis = System.currentTimeMillis();
hhUserInfo.setByYear(1);
hhUserFollowRecordES.setByYear(1);
hhEducationExperienceRecordES.setByYear(1);
hhEducationExperienceRecordQuery.setQueryObject(hhEducationExperienceRecordES);
hhProjectExperienceRecordES.setByYear(1);
hhProjectExperienceRecordQuery.setQueryObject(hhProjectExperienceRecordES);
hhWorkExperienceRecordES.setByYear(1);
hhWorkExperienceRecordQuery.setQueryObject(hhWorkExperienceRecordES);
//查询主表和关联表的数据总量
Integer hhUserInfoCount = headAccountService.countHhUserInfoByParam(hhUserInfo);
Integer hhUserFollowRecordCount = headAccountService.countHhUserFollowRecordByParam(hhUserFollowRecordES);
Integer hhEducationExperienceRecordCount = headAccountService.countHhEducationExperienceRecordByParam(hhEducationExperienceRecordQuery);
Integer hhProjectExperienceRecordCount = headAccountService.countHhProjectExperienceRecordByParam(hhProjectExperienceRecordQuery);
Integer hhWorkExperienceRecordCount = headAccountService.countHhWorkExperienceRecordByParam(hhWorkExperienceRecordQuery);
//计算 CountDown 次数
int sum = ((hhUserInfoCount / PAGE_SIZE) + 1)
+ ((hhUserFollowRecordCount / PAGE_SIZE) + 1)
+ ((hhEducationExperienceRecordCount / PAGE_SIZE) + 1)
+ ((hhProjectExperienceRecordCount / PAGE_SIZE) + 1)
+ ((hhWorkExperienceRecordCount / PAGE_SIZE) + 1);
// countDownLatchAllTable 用来处理 关联表的数据分组(按主表的关联ID分组),只有四个表需要分组,所有是四次。
countDownLatchAllTable = new CountDownLatch(4);
// countDownLatch 用来处理所有表数据的查找,是数据查找这一阶段的线程池的任务总数量
countDownLatch = new CountDownLatch(sum);
log.info("\nhhUserInfoCount - 总数据量为:============{}" +
"\nhhUserFollowRecordCount - 总数据量为:============{}" +
"\nhhEducationExperienceRecordCount - 总数据量为:============{}" +
"\nhhProjectExperienceRecordCount - 总数据量为:============{}" +
"\nhhWorkExperienceRecordCount - 总数据量为:============{}"+
"\ncountDown - 次数为:============{}"
, hhUserInfoCount
, hhUserFollowRecordCount
, hhEducationExperienceRecordCount
, hhProjectExperienceRecordCount
, hhWorkExperienceRecordCount
, (sum + 4)
);
queryUserInfoData(hhUserInfoCount);
queryUserDetailData();
queryUserFollowRecordData(hhUserFollowRecordCount);
queryEducationExperienceRecordData(hhEducationExperienceRecordCount);
queryProjectExperienceRecordData(hhProjectExperienceRecordCount);
queryWorkExperienceRecordData(hhWorkExperienceRecordCount);
//阻塞当前线程,必须完成 所有查找数据任务 才能往下走
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("\nuserInfoAllList - 总数据量为:============{}" +
"\nfollowRecordAllList - 总数据量为:============{}" +
"\neducationRecordAllList - 总数据量为:============{}" +
"\nprojectRecordAllList - 总数据量为:============{}" +
"\nworkRecordALlList - 总数据量为:============{}"
, userInfoAllList.size()
, followRecordAllList.size()
, educationRecordAllList.size()
, projectRecordAllList.size()
, workRecordALlList.size()
);
log.info("数据查找完成 花费{}ms,开始分组数据:=========================", (System.currentTimeMillis() - millis));
dataGroup();
//阻塞当前线程,必须完成 所有关联表数据分组任务 才能往下走
try {
countDownLatchAllTable.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("数据分组完成 花费{}ms,开始转换数据:=========================", (System.currentTimeMillis() - millis));
log.info("\nfollowAllMap - 总数据量为:============{}" +
"\neducationAllMap - 总数据量为:============{}" +
"\nprojectAllMap - 总数据量为:============{}" +
"\nworkAllMap - 总数据量为:============{}"
, followAllMap.size()
, educationAllMap.size()
, projectAllMap.size()
, workAllMap.size()
);
log.info("查找数据 花费{}ms,开始 - 转换数据:=========================", (System.currentTimeMillis() - millis));
try {
//页长设置为 4000 是由于 es 的批量插入请求数量有限制,并且 dubbo 每次的请求也对大小有限制
List<List<HhUserInfo>> list = splitList(userInfoAllList, 4000);
log.info("切割数据完成 花费{}ms,开始 - 聚合数据:=========================", (System.currentTimeMillis() - millis));
CountDownLatch countDownLatch = new CountDownLatch(list.size());
LongAdder longAdder = new LongAdder();
for (List<HhUserInfo> hhUserInfoList : list) {
threadPool.execute(new Thread(() -> {
try {
Map<String, Map<String, Object>> dataMap = new HashMap<>();
for (HhUserInfo hhUserInfo : hhUserInfoList) {
dataMap.put(String.valueOf(hhUserInfo.getUid()), getHhUserInfoIndex(hhUserInfo));
}
elasticsearchService.bulkInsertData(index, dataMap);
int size = dataMap.size();
longAdder.add(size);
log.info("=========第{}次插入:新增{}条数据", countDownLatch.getCount(),size);
countDownLatch.countDown();
} catch (Exception e) {
log.info("=========e:{}报错了",e.getStackTrace());
}
}));
}
//让当前线程处于阻塞状态,直到锁存器计数为0
countDownLatch.await();
log.info("=========总共新增{}条数据", longAdder.intValue());
} catch (Exception e) {
log.info("=========e:{}", Throwables.getStackTraceAsString(e));
}
log.info("聚合 花费{}ms=========================", (System.currentTimeMillis() - millis));
}
/**
* 拆分集合
*
* @param <T> 泛型对象
* @param resList 需要拆分的集合
* @param subListLength 每个子集合的元素个数
* @return 返回拆分后的各个集合组成的列表
**/
private <T> List<List<T>> splitList(List<T> resList, int subListLength) {
if (org.springframework.util.CollectionUtils.isEmpty(resList) || subListLength <= 0) {
return Lists.newArrayList();
}
List<List<T>> ret = Lists.newArrayList();
int size = resList.size();
if (size < subListLength) {
// 数据量不足 subListLength 指定的大小
ret.add(resList);
} else {
int pre = size / subListLength;
int last = size % subListLength;
// 前面pre个集合,每个大小都是 subListLength 个元素
for (int i = 0; i < pre; i++) {
List<T> itemList = Lists.newArrayList();
for (int j = 0; j < subListLength; j++) {
itemList.add(resList.get(i * subListLength + j));
}
ret.add(itemList);
}
// last的进行处理
if (last > 0) {
List<T> itemList = Lists.newArrayList();
for (int i = 0; i < last; i++) {
itemList.add(resList.get(pre * subListLength + i));
}
ret.add(itemList);
}
}
return ret;
}

















 6049
6049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









