







子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
条件:
一条sql语句的查询结果作为另一条查询语句的条件或者查询结果。
嵌套:
多条sql语句嵌套使用,内部的sql查询语句称为子查询。
使用子查询解决的问题:不能够一步求解的问题。
示例:查询工资比SCOTT高的员工信息
1.select sal from emp where name = ‘SCOTT’;查询出来SCOTT的工资是3000
2.select * from emp where sal>3000;
使用子查询解决上面的问题:
select * from emp where sal > (select sal from emp where name = ‘SCOTT’);
子查询注意的10个问题
- 子查询语法中的小括号
- 子查询的书写风格
- 可以使用子查询的位置:where,select,having,from
- 不可以使用子查询的位置:group by
- == from后面的子查询==
- 主查询和子查询可以不是同一张表
- 一般不在子查询中使用排序;但在Top-N分析问题中,必须对子查询进行排序
- 一般先执行子查询,再执行主查询;相关子查询例外
- 单行子查询只能使用单行操作符;多行子查询只能使用多行操作符
- 子查询中null值问题
在select后面使用子查询:
子查询必须是单行子查询(返回一行记录的子查询)
select empno ,ename,(select job from emp where empno =7839 ) 第四列 from emp;
在having 后面使用子查询:
select deptno,avg(sal)
from emp
group by deptno
having avg(sal) > (select max(sal)
from emp
where deptno = 30);
在from后面使用子查询:
# 查询员工信息:员工号,姓名,月薪
select *
from (select empno ,ename,sal from emp);#可以把from后面的子查询的结果看成是一张新的表(虚拟表)
#查询员工信息:员工号,姓名,月薪,年薪
select *
from (select empno ,ename,sal,sal*12 annsal from emp);
主查询和子查询可以不是同一张表
#查询部门名称是SALES的员工信息
select *
from emp
where deptno = (select deptno
from dept
where dname = 'SALES' );
#主查询查询的是员工表,子查询查询的是部门表
#使用多表查询语句解决上面的问题
select e.*
from emp e,dept d
where e.deptno = d.deptno and d.dname = 'SALES';
一般不在子查询中使用排序;但在Top-N分析问题中,必须对子查询进行排序
Top-N问题:
按照某个规律排序后,取出最前面的几条记录。
#找到员工表中工资最高的前三名
select rownum,empno,ename ,sal
from(slecet *
from emp
order by sal desc)
where rownum<=3;
一般先执行子查询,再执行主查询;相关子查询例外
#相关子查询
#找到员工表中薪水大于本部门平均薪水的员工
select empno,ename,sal,(select avg(sal) from emp where deptno = e.deptno) avgsal
from emp e
where sal>(select avg(sal) from emp where deptno = e.deptno);
单行子查询只能使用单行操作符;多行子查询只能使用多行操作符
单行子查询:子查询只返回一条记录;
单行操作符:
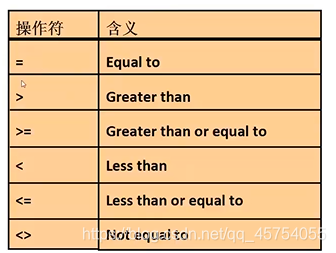
单行子查询只能使用单行操作符
一个主查询中可以有多个单行子查询
#查询员工信息,要求:职位与7566员工一样,薪水大于7782员工的薪水
select * from emp
where job = (select job from emp where empno =7566) and sal > (select sal fron where empno =7782);
#查询工资最低的员工信息
select *
from emp
where sal = (select min(sal) from emp );
#查询最低工资大于20号部门最低工资的部门号和部门的最低工资
select deptno,min(sal)
from emp
group by deptno
having min(sal) > (select min(sal) from emp where deptno = 20);
多行子查询:自查询返回的记录是多行的。
多行操作符:

in的使用:
#查询部门名称是SALES和ACCOUNTING的员工信息
select *
from emp
where deptno in (select deptno from dept where dname = 'SALES'or dname ='ACCOUNTING')
#使用多表查询语句完成
select e.*
from emp e,dept d
where e.deptno = d.deptno and
(d.dname ='SALES'or d.dname ='ACCOUNTING');
any的使用:
#查询工资比30号部门任意一个员工高的员工信息
select * from emp
where sal > any(select sal from emp where deptno = 30);
#大于集合的任意一个值,只需要大于集合中元素的最小值
select * from emp
where sal > (select min(sal) from emp where deptno = 30)
all的使用
#查询工资比30号部门所有员工高的员工信息
select *
from emp
where sal > all(select sal from emp where deptno = 30);
#大于集合的所有值,只需要大于集合的最大值
select * from emp
where sal > (select max(sal) from emp where deptno = 30);
子查询中null值问题
单行子查询:
- 如果子查询中的结果为null,那么主查询中的where条件永远为假,不会得到任何的结果。
多行子查询中的null值问题
#查询不是老板的员工
select * from emp
where empno not in (select mqr from emp where mqr is not null);
in 和 exists 区别
#查询语文或者英语课程的成绩信息
select * from score where course_id in(select if from course where name ='语文'or name = '英语');
slect * from score sco from (select sco.id from course cou where(name = '语文'or name = '英语') and cou.id = sco.course_id);
mysql中的in语句是把外表和内表作hash 连接,
而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的。这个是要区分环境的。
- 如果查询的两个表大小相当,那么用in和exists差别不大。
- 如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
- not in 和not exists:如果查询语句使用了not in,那么内外表都进行全表扫描,没有用到索引; 而not extsts的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









