







 本文探讨了机器学习中的正则化技术,包括L2正则化、Dropout等方法来预防过拟合,增强模型的泛化能力。介绍了如何通过调整正则化参数λ来平衡模型复杂度与训练目标,以及Dropout的具体实施步骤。
本文探讨了机器学习中的正则化技术,包括L2正则化、Dropout等方法来预防过拟合,增强模型的泛化能力。介绍了如何通过调整正则化参数λ来平衡模型复杂度与训练目标,以及Dropout的具体实施步骤。
目录
目录
1.2 偏差/方差(正则化参数过大欠拟合,正则化参数过小过拟合)
1.4 正则化(有利于防止过拟合,解决高方差(高阶多项式)权重衰减)
1.11 神经网络的权重初始化(主要利用n.sqrt来使权重矩阵避免过快增长或下降)
1.12 梯度的数值逼近(用双边公差检测来验证g(塞塔)是否是f函数的偏导数)
x是n维向量(x1,x2,…,xn),||x||=根号(|x1|方+|x2|方+…+|xn|方))
1.1 训练/开发/测试集(如何选择比例)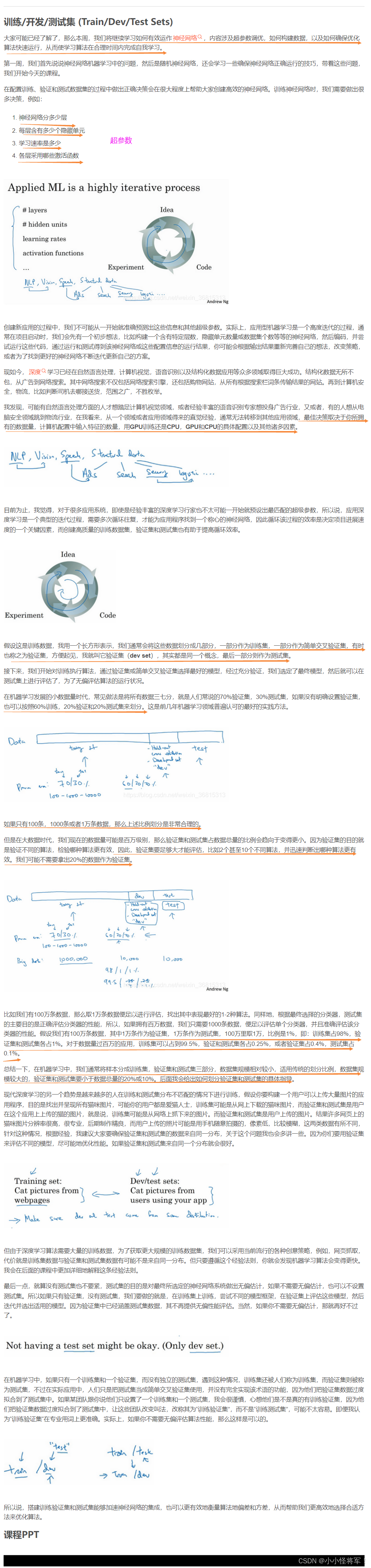
1.2 偏差/方差(正则化参数过大欠拟合,正则化参数过小过拟合)
参照:10.3内容 机器学习(正在更新)_小小怪将军!的博客-优快云博客_机器学习更新

1.3 机器学习基础
1.4 正则化(有利于防止过拟合,解决高方差(高阶多项式)权重衰减)
正则化:
主要作用:加入惩罚项,减少过拟合。
实现:主要是通过限制过多高阶项参数的大小,使它很小,就可以一定程度上避免太过于依赖于各个参数。或者可以理解为限制模型的复杂度,不让模型过于复杂。
正则化参数: λ 这个正则化参数需要控制是平衡拟合训练的目标和保持参数值较小的目标。从而来保持假设的形式相对简单,来避免过度的拟合。
可以理解为衡量 模型的复杂度,同时又要最小化我们的代价函数。(λ 越大,这个限制越强)
(之后可以更深刻的梳理一下正则化项的选择和为何这样的形式可以)
PS:有的时候加上正则项之后,防止过拟合,泛化能力更好了,但可能在训练集上出现精度没有之前高的问题,也是可以解释的。但是在测试集上表现会更好。

1.5 为什么正则化有利于预防过拟合(L2正则化)

1.6 Dropout 正则化 (随机失活正则化)

正则化目的:防止过拟合、增强模型的泛化能力。
什么是 dropout?
在神经网络中,遍历神经网络的每一层,为每一层设置一个概率keep-prob,并以1-(keep-prob)的概率移除一些神经元。 也可以理解为每一个神经元被保留下来的概率为该层的keep-prob。
注意:深度学习模型在训练时使用dropout,在测试时不使用dropout。
Inverted dropout 反向随机激活
1.随机生成矩阵d[l]=np.random.randn(a[l].shape,a[l-1].shape)
2.判断d[l]中每一个元素与keep-prob的大小,若小于keep-prob则被保留下来。
3.新的激活向量为a[l]=np.multiply(a[l],d[l]) <这里是为了把a[l]中相应元素归零,即消除这部分的神经元 >
4.使得a[l]=a[l]/(keep-prob) <随机失活后恢复被保留下来神经元本身的值,即保证a[l]期望不变> 这里把第三步乘上的keep-prob又给除掉了!这是重点!!!
1.7 理解 Dropout

1.8其他正则化的方法 (数据扩增和 即时终止)
正在上传…重新上传取消正在上传…重新上传取消
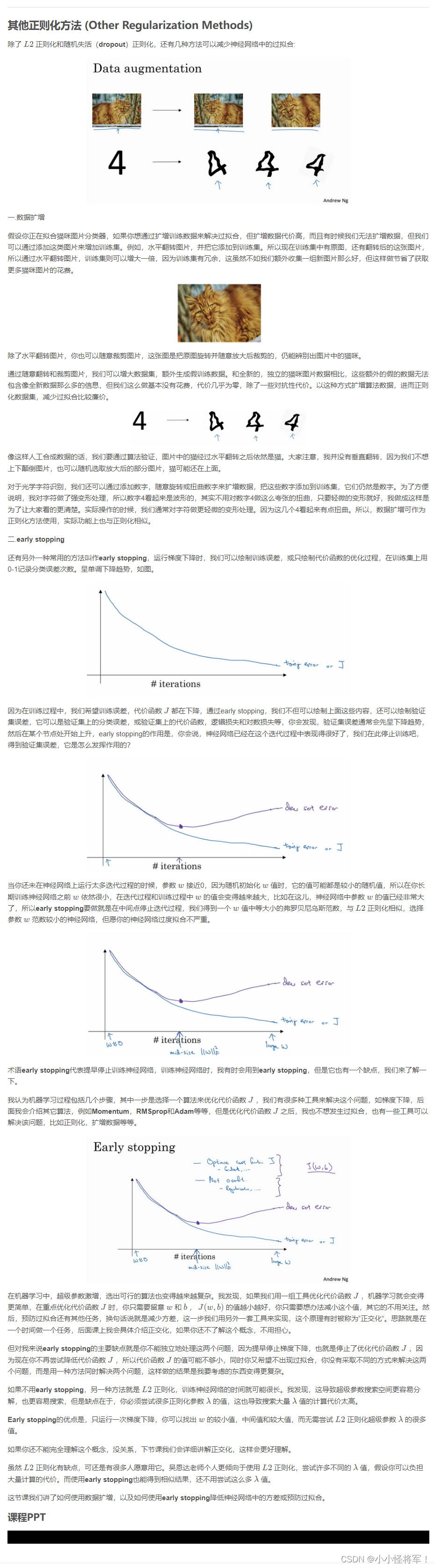
1.9 归一化输入

1.10 梯度消失与梯度爆炸(W权重的选择)

1.11 神经网络的权重初始化(主要利用n.sqrt来使权重矩阵避免过快增长或下降)

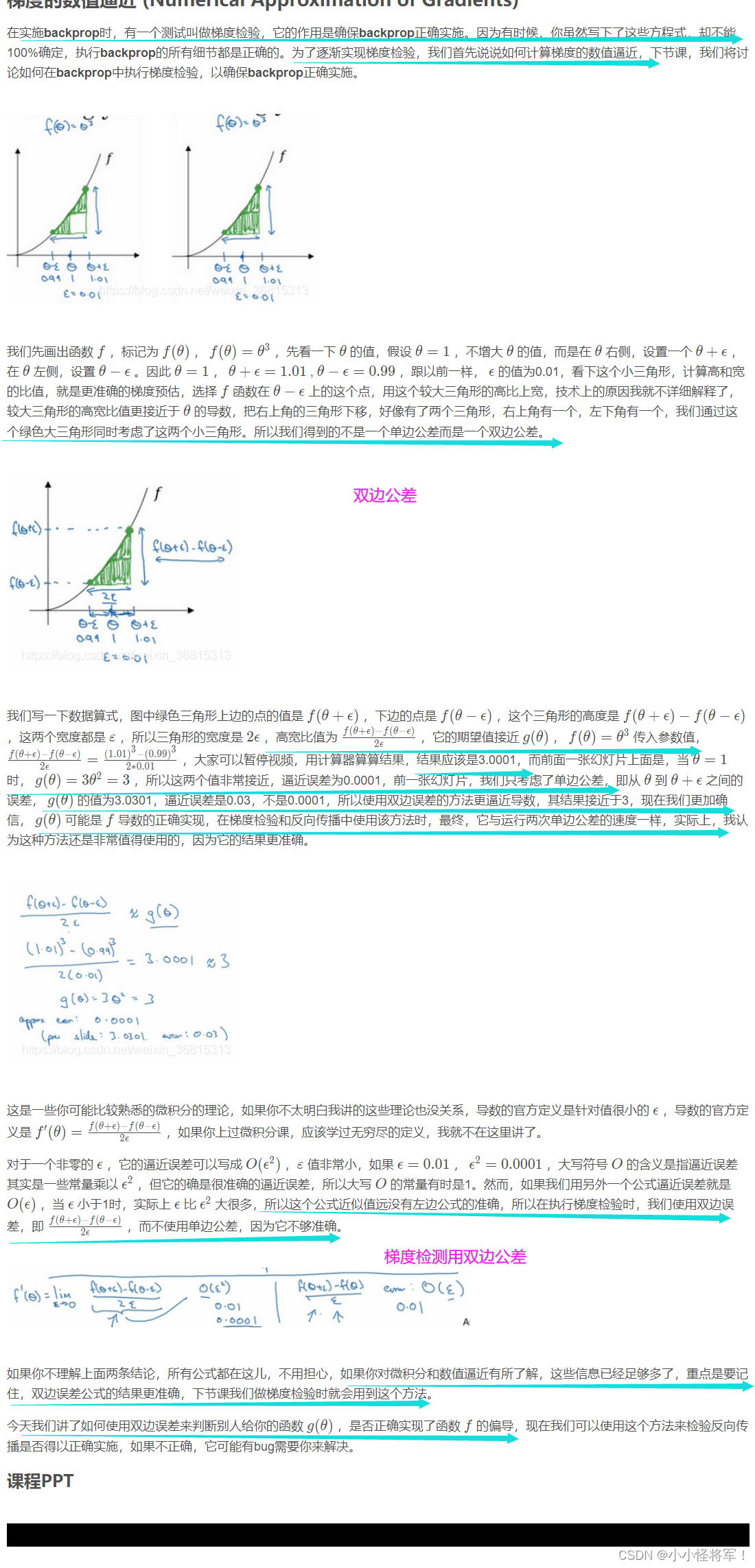
1.12 梯度的数值逼近(用双边公差检测来验证g(塞塔)是否是f函数的偏导数)
今天我们讲了如何使用双边误差来判断别人给你的函数g(θ) ,是否正确实现了函数 f的偏导数
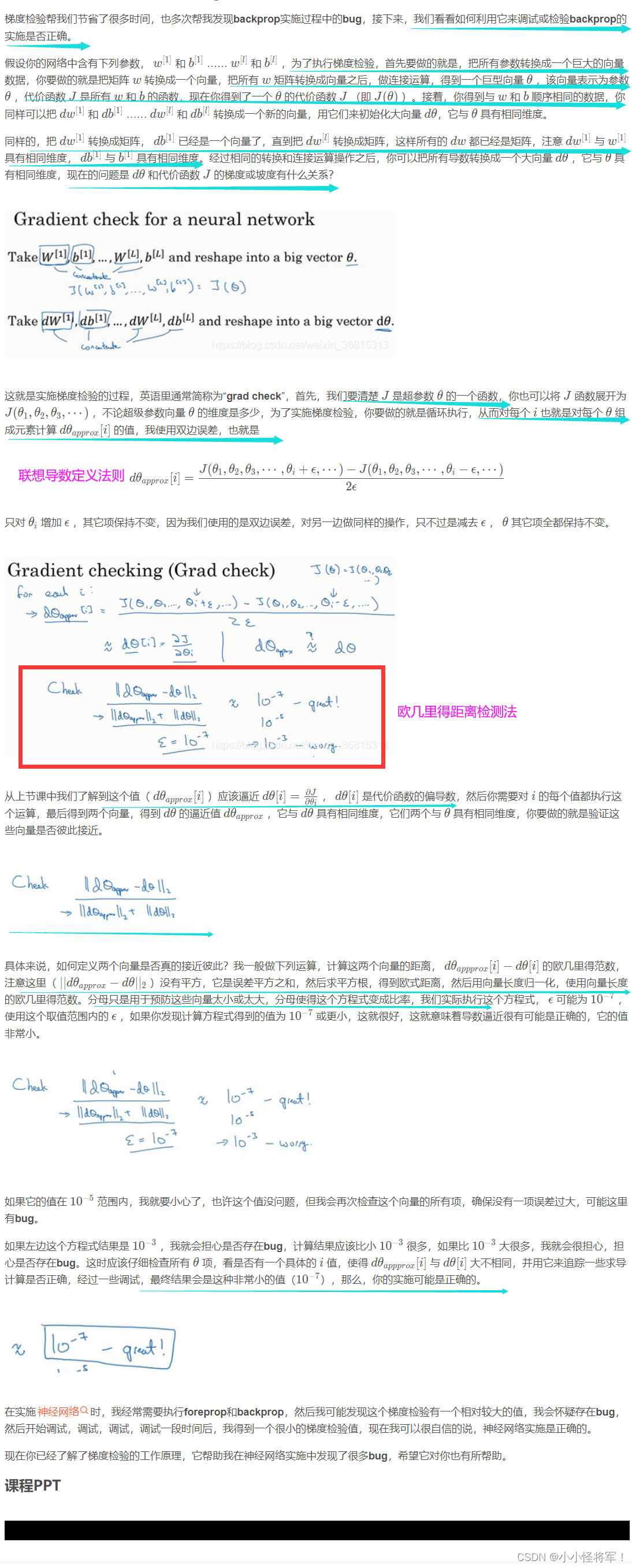
1.13 梯度检验(欧几里得范数检验
x是n维向量(x1,x2,…,xn),
||x||=根号(|x1|方+|x2|方+…+|xn|方))
补充;
1.14 梯度检验应用的注意事项

总结:


















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









