






网络结构介绍:简单模型、AlexNet、VGGNet、ResNet,并附2025秋招笔试题网络结构
前言
最近准备秋招投的算法岗,面试的时候发现自己网络结构有些不清楚的地方,故整理学习,本文从简单的一个小的神经网络的定义模型介绍,接着介绍AlxeNet网络结构、VGG16网络结构和ResNet18网络结构。
一、简单的神经网络模型
基础知识
在解释这个网络结构之前,让我们先了解一下每个组件的作用:
-
in_channels:输入的通道数,即输入数据的深度。对于灰度图像,这个值通常是1;对于RGB图像,这个值是3。 -
out_channels:输出的通道数,即卷积层输出的特征图的数量。 -
kernel_size:卷积核的大小。对于正方形卷积核,只需要一个整数;对于矩形卷积核,需要一个元组来分别指定高度和宽度。 -
stride:步长,即卷积核在输入数据上移动的步长。步长为1意味着每次移动一个像素。 -
padding:填充,即在输入数据的边缘添加额外的零像素,以控制输出特征图的大小。 -
dilation:扩张,即控制卷积核中元素之间的间距,用于实现空洞卷积。 -
groups:分组卷积的数量,用于控制输入和输出通道之间的连接方式。 -
bias:偏置,决定是否在卷积层的输出中添加一个可学习的偏置项。 -
padding_mode:设置填充的模式,通常有三种:zeros(默认,填充0)、reflect(反射填充)、replicate(复制边缘值填充)。一些函数定义: -
Softmax:
Softmax函数是一种在多类分类问题中常用的激活函数。它将一个向量或矩阵的实数元素转换为一组概率分布,使得每个元素的值都在0到1之间,并且所有元素的和为1。在神经网络的输出层使用Softmax函数可以表示模型对每个类别的预测概率。
数学上,对于输入向量( z )中的每个元素( z_i ),Softmax函数定义为:
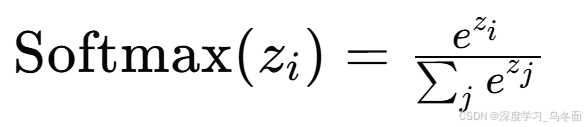
其中,分母是对输入向量中所有元素应用指数函数后的和。
NMS(Non-Maximum Suppression):
NMS是一种在目标检测任务中常用的技术,用于处理多个候选框。在目标检测模型中,可能会为同一个目标预测多个重叠的边界框。NMS通过选择性地保留最佳的边界框并抑制其他重叠的边界框来减少这种重叠。通常,它会保留最高得分的边界框,并移除与其重叠度超过特定阈值的其他边界框。
BN(Batch Normalization):
BN,即批量归一化,是一种用于训练深度神经网络的技术,旨在提高训练速度、稳定性和性能。它通过规范化(归一化)每一层的输入来工作,通常是通过调整和缩放激活的均值和方差来实现的。具体来说,BN会计算每个批次数据的均值和方差,然后使用这些统计数据来规范化该批次的数据。这样做可以减少内部协变量偏移(即每层输入分布的变化),并允许使用更高的学习率。
Dropout:
Dropout是一种正则化技术,用于防止神经网络过拟合。在训练过程中,Dropout层会随机“丢弃”(即将输出设置为0)网络中的一部分神经元,这可以防止模型过于依赖于任何给定的神经元,并鼓励网络学习更加鲁棒的特征表示。在测试时,所有神经元都处于激活状态,但是它们的输出会通过与训练时未被丢弃的神经元的比例相同的比例进行缩放,以保持总体激活的期望值不变。
简单的网络结构
现在,让我们逐层分析这个MyNet网络:
这个网络由两部分组成:特征提取部分(self.features)和分类器部分(self.classifier),它继承自 PyTorch 的 nn.Module。
import torch
from torch import nn
class MyNet(nn.Module):
def __init__(self, num_classes):
super(MyNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, stride=2),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
# nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
# nn.ReLU(),
# nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Linear(128, num_classes) # Assuming input size of 64x64
def forward(self, x):
x = self.features(x)
# print(x.shape) # 打印特征图的尺寸
x = x.view(x.size(0), -1)
# print(x.shape) # 打印扁平化后的尺寸
x = self.classifier(x)
return x
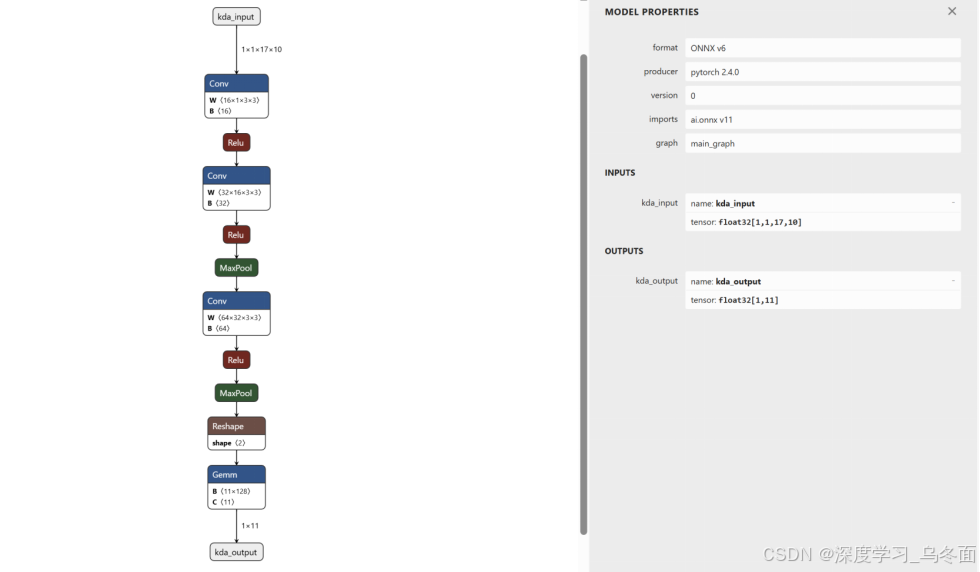
PS:获取网络结构图可以将.onnx文件输入进这个网站:https://netron.app/
根据网络结构和参数,我们可以详细分析每一层的输出特征图尺寸:
self.features是一个nn.Sequential模块,它按顺序包含了以下层:
第一个 nn.Conv2d(1, 16, kernel_size=3, stride=2):
- 输入通道数:1(输入图像是灰度图)
- 输出通道数:16(生成16个特征图)
- 卷积核大小:3x3
- 步长:2(卷积核每次移动两个像素)
- 输出特征图尺寸:输入图像尺寸为 64 x 64,经过步长为2的卷积操作后,输出尺寸为32 x 32。
第二个 nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1):
- 输入通道数:16(前一层的输出通道数)
- 输出通道数:32(生成32个特征图)
- 卷积核大小:3x3
- 步长:1(卷积核每次移动一个像素)
- 填充:1(在输入特征图的边缘添加一圈0)
- 输出特征图尺寸:由于填充为1,输出尺寸保持不变,仍为 32 x 32。
第三个 nn.MaxPool2d(kernel_size=2, stride=2):
- 池化窗口大小:2x2
- 步长:2(池化窗口每次移动两个像素)
- 输出特征图尺寸:输入特征图尺寸为 32 x 32,经过最大池化操作后,输出尺寸为16 x16。
第四个 nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1):
- 输入通道数:32(前一层的输出通道数)
- 输出通道数:64(生成64个特征图)
- 卷积核大小:3x3
- 步长:1
- 填充:1
- 输出特征图尺寸:由于填充为1,输出尺寸保持不变,仍为 16 x16。
第五个 nn.MaxPool2d(kernel_size=2, stride=2):
- 池化窗口大小:2x2
- 步长:2
- 输出特征图尺寸:输入特征图尺寸为16 x16,经过最大池化操作后,输出尺寸为 8 x 8。
-
self.classifier是一个全连接层(nn.Linear),它将特征提取部分的输出转换为最终的分类结果。这里的参数128是特征图展平后的总特征数,而num_classes是分类任务中类别的数量。这个全连接层的权重将通过反向传播进行学习。 -
forward(self, x)方法定义了数据通过网络的前向传播路径:x = self.features(x): 输入数据x通过特征提取部分,得到一系列特征图。x = x.view(x.size(0), -1): 将特征图展平为一维向量,以便输入到全连接层。这里x.size(0)保持了批次大小不变,-1表示自动计算展平后的维度。x = self.classifier(x): 将展平后的特征向量输入到分类器中,得到最终的分类结果。
二、AlxeNet网络结构
代码如下(示例):
import torch
import torch.nn as nn
class MyNet(nn.Module):
def __init__(self, num_classes=10):
super(MyNet, self).__init__()
self.feature_extraction = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2, bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
nn.Conv2d(in_channels=96, out_channels=192, kernel_size=5, stride=1, padding=2, bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
nn.Conv2d(in_channels=192, out_channels=384, kernel_size=3, stride=1, padding=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1, bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features=256 * 6 * 6, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Linear(in_features=4096, out_features=num_classes),
)
def forward(self, x):
x = self.feature_extraction(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
同样这个网络由两部分组成:特征提取部分(self.feature_extraction)和分类器部分(self.classifier)。
特征提取部分 (self.feature_extraction)
-
第一个
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2, bias=False):- 输入通道数:3(输入图像是RGB彩色图)
- 输出通道数:96(生成96个特征图)
- 卷积核大小:11x11
- 步长:4(卷积核每次移动四个像素)
- 填充:2(在输入特征图的边缘添加两圈0)
- 输出特征图尺寸:输入图像尺寸为 224 x 224,经过卷积操作后,输出尺寸为
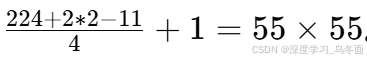
-
第二个
nn.ReLU(inplace=True):- 激活函数,对卷积层的输出进行非线性变换。
-
第三个
nn.MaxPool2d(kernel_size=3, stride=2, padding=0):- 池化窗口大小:3x3
- 步长:2
- 输出特征图尺寸:输入特征图尺寸为 55 x 55 ,经过最大池化操作后,输出尺寸为 27 x 27。
-
第四个
nn.Conv2d(in_channels=96, out_channels=192, kernel_size=5, stride=1, padding=2, bias=False):- 输入通道数:96
- 输出通道数:192
- 卷积核大小:5x5
- 步长:1
- 填充:2
- 输出特征图尺寸:27 x 27。
-
第五个
nn.ReLU(inplace=True):- 激活函数。
-
第六个
nn.MaxPool2d(kernel_size=3, stride=2, padding=0):- 输出特征图尺寸:27/2 = 13.5,由于输出尺寸必须是整数(向下取),实际输出尺寸为 13 x 13。
-
后续卷积层:
- 这些卷积层继续增加深度和特征提取能力,每次卷积操作后都使用
nn.ReLU(inplace=True)进行激活。 - 最后一个
nn.MaxPool2d(kernel_size=3, stride=2, padding=0)将特征图尺寸减小到 13/2 = 6.5,实际输出尺寸为 6 x 6。
- 这些卷积层继续增加深度和特征提取能力,每次卷积操作后都使用
分类器部分 (self.classifier)
-
第一个
nn.Dropout(p=0.5):- 在训练过程中随机丢弃50%的节点,以减少过拟合。
-
第一个
nn.Linear(in_features=256 * 6 * 6, out_features=4096):- 将 (6 \times 6) 的特征图展平,每个特征图有256个通道,共 (256 \times 6 \times 6 = 9216) 个特征,然后通过一个全连接层减少到4096个特征。
-
第二个
nn.ReLU(inplace=True):- 激活函数。
-
第二个
nn.Dropout(p=0.5):- 再次使用dropout。
-
第二个
nn.Linear(in_features=4096, out_features=4096):- 进一步处理特征。
-
第三个
nn.ReLU(inplace=True):- 激活函数。
-
第三个
nn.Linear(in_features=4096, out_features=num_classes):- 最后一个全连接层,将特征映射到类别数
num_classes。
- 最后一个全连接层,将特征映射到类别数
前向传播 (forward 方法)
- 输入数据
x通过特征提取部分,得到一系列特征图。 - 特征图被展平并通过分类器部分进行分类。
- 最终输出分类结果。
这个网络结构是一个典型的卷积神经网络,用于图像分类任务,具有多层卷积和池化层,以及全连接层进行分类。
三、VGG16网络结构
代码如下(示例):
import torch
from torch import nn
class MyNet(nn.Module):
def __init__(self, num_classes):
super(MyNet, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
self.block2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1)
)
self.block3 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1),
)
self.block4 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1)
)
self.block5 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1),
)
self.block6 = nn.Sequential(
nn.Flatten(),
# 使用自适应池化
nn.Linear(in_features=512 * 7 * 7, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=4096, out_features=num_classes),
)
def forward(self, input):
output = self.block1(input)
output = self.block2(output)
output = self.block3(output)
output = self.block4(output)
output = self.block5(output)
output = self.block6(output)
return output
它同样继承自 PyTorch 的 nn.Module,这个网络由多个卷积块和全连接层组成,每个卷积块都包含若干卷积层、批量归一化层(Batch Normalization)、ReLU激活函数和最大池化层。下面是对每一层的详细解释:
卷积块 (block1 到 block5)
每个卷积块结构相似,包含以下层:
-
卷积层
nn.Conv2d:- 输入通道数:由块的输入决定。
- 输出通道数:由块的配置决定,每个块的输出通道数逐渐增加。
- 卷积核大小:3x3
- 步长:1
- 填充:1
- 输出特征图尺寸:由于填充和步长设置,输出特征图的空间尺寸保持不变。
-
批量归一化层
nn.BatchNorm2d:- 用于归一化每个通道的特征,有助于加速训练过程并提高模型的稳定性。
-
ReLU激活层
nn.ReLU:- 引入非线性,增强模型的表达能力。
-
最大池化层
nn.MaxPool2d:- 池化窗口大小:2x2
- 步长:2
- 用于减小特征图的空间尺寸,增加感受野,减少计算量。
卷积块具体分析
-
block1:- 输入通道数:3(RGB图像)
- 输出通道数:64
- 特征图尺寸:输入图像尺寸不变,经过最大池化后尺寸减半。
-
block2:- 输入通道数:64
- 输出通道数:128
- 特征图尺寸:经过最大池化后尺寸减半。
-
block3:- 输入通道数:128
- 输出通道数:256
- 特征图尺寸:经过最大池化后尺寸减半。
-
block4:- 输入通道数:256
- 输出通道数:512
- 特征图尺寸:经过最大池化后尺寸减半。
-
block5:- 输入通道数:512
- 输出通道数:512
- 特征图尺寸:经过最大池化后尺寸减半。
全连接层 (block6)
-
nn.Flatten:- 将多维的特征图展平成一维向量。
-
全连接层
nn.Linear:- 将展平的特征向量映射到更高维度的空间,进行特征的进一步抽象和分类。
-
ReLU激活层
nn.ReLU:- 引入非线性。
-
Dropout层
nn.Dropout:- 在训练过程中随机丢弃部分节点,防止过拟合。
-
最后的全连接层:
- 将特征映射到类别数
num_classes。
- 将特征映射到类别数
前向传播 (forward 方法)
- 输入数据
input依次通过block1到block5的卷积块,每个块都进行特征提取。 - 经过
block6的全连接层进行分类。 - 最终输出分类结果。
这个网络结构是一个典型的卷积神经网络,用于图像分类任务,具有多层卷积和池化层,以及全连接层进行分类。每个卷积块中的批量归一化和ReLU激活层有助于提高模型的性能和训练速度。
四、ResNet-18网络结构
代码如下(示例):
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
return model
# Example usage:
# model = resnet18(pretrained=False, num_classes=10)
# print(model)
这段代码定义了一个完整的ResNet-18模型,它是一个经典的深度残差网络,广泛用于图像识别任务。下面是对代码中各个组件的详细解释:
BasicBlock 类
BasicBlock 是ResNet中的基本构建块,用于构建较浅的网络(如ResNet-18和ResNet-34)。它包含两个具有批量归一化和ReLU激活的卷积层,以及一个可能的恒等映射或卷积下采样(如果需要改变特征图的维度)。
expansion属性:这个属性用于控制输出通道数。在BasicBlock中,expansion被设置为1,这意味着输出通道数等于out_channels。downsample参数:这是一个可选的下采样层,用于在需要时调整输入x的维度,以匹配残差连接的维度。
ResNet 类
ResNet 类定义了整个网络的结构,包括初始的卷积层、四个由 BasicBlock 组成的残差层,以及最后的全连接层。
conv1:初始的卷积层,用于提取输入图像的基本特征。bn1:批量归一化层,用于归一化conv1的输出。maxpool:最大池化层,用于减少特征图的空间维度。layer1到layer4:这些层是由BasicBlock组成的残差层,每层包含不同数量的BasicBlock。avgpool:自适应平均池化层,用于将最后一个残差层的输出转换为固定长度的特征向量。fc:全连接层,用于将特征向量映射到最终的类别。
_make_layer 方法
这个方法用于创建一个由多个 BasicBlock 组成的残差层。它接受一个块类型、输出通道数、块的数量和步长作为参数。
downsample:如果输入和输出的通道数不同,或者步长不为1(需要下采样),则创建一个下采样层。
forward 方法
forward 方法定义了数据通过网络的前向传播路径。它首先通过初始的卷积层、批量归一化层和最大池化层,然后依次通过四个残差层。最后,通过自适应平均池化层和全连接层得到最终的分类结果。
resnet18 函数
这个函数是一个构造器,用于创建一个具有18层的ResNet模型(ResNet-18)。它接受一个可选的 pretrained 参数,如果设置为 True,则可以加载预训练的权重(在这个示例代码中没有实现加载预训练权重的功能)。
示例用法
在示例用法中,创建了一个ResNet-18模型,设置了类别数为10。然后,我们打印出模型的结构。
这个ResNet-18模型可以用于图像分类任务,通过调整 num_classes 参数来适应不同的分类任务。此外,通过修改 BasicBlock 和 ResNet 类中的参数,可以构建不同深度和复杂度的ResNet模型。
总结
最后布置一个小作业:
使用PyTorch实现一个简单的神经网络模型,并对一组随机生成的数据进行训练。要求模型包含一个输入层、一个隐藏层和一个输出层。这个是在笔试中本人遇到的题目,有需要的可以关注我,点赞评论区艾特我,我私信给你(PS:仅用于技术交流,不可商用转载)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









