






9.1词嵌入的基本原理
词嵌入:电影评论分类
构建IMDb可视化评论分类器
tensorflow内置数据集
电影评论的数据集网址:http://ai.stanford.edu/~amaas/data/sentiment/
@InProceedings{maas-EtAl:2011:ACL-HLT2011,
author = {Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher},
title = {Learning Word Vectors for Sentiment Analysis},
booktitle = {Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies},
month = {June},
year = {2011},
address = {Portland, Oregon, USA},
publisher = {Association for Computational Linguistics},
pages = {142--150},
url = {http://www.aclweb.org/anthology/P11-1015}
}
高维数据查看网站:http://projector.tensorflow.org/
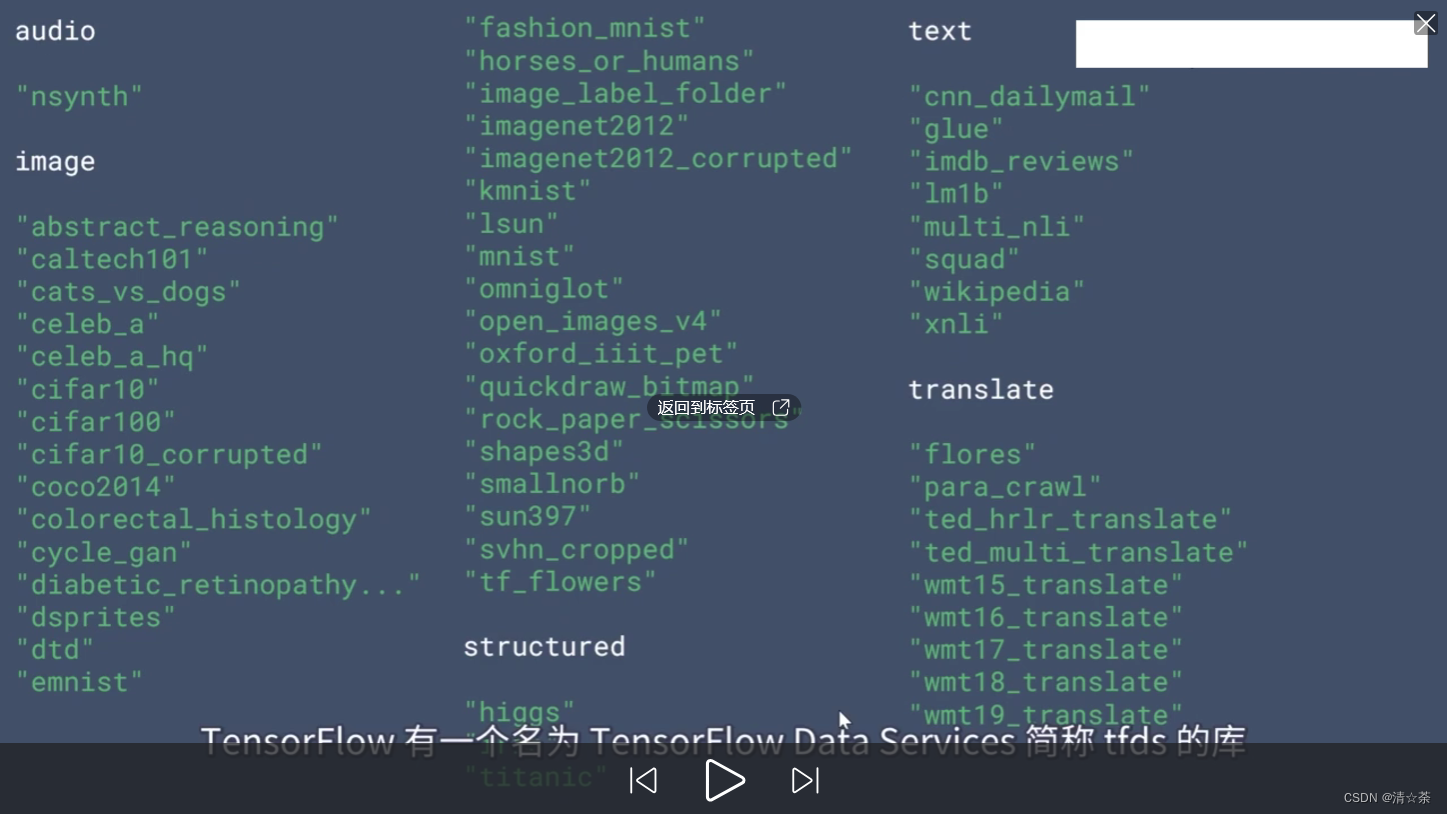
tensorflow内置数据集:
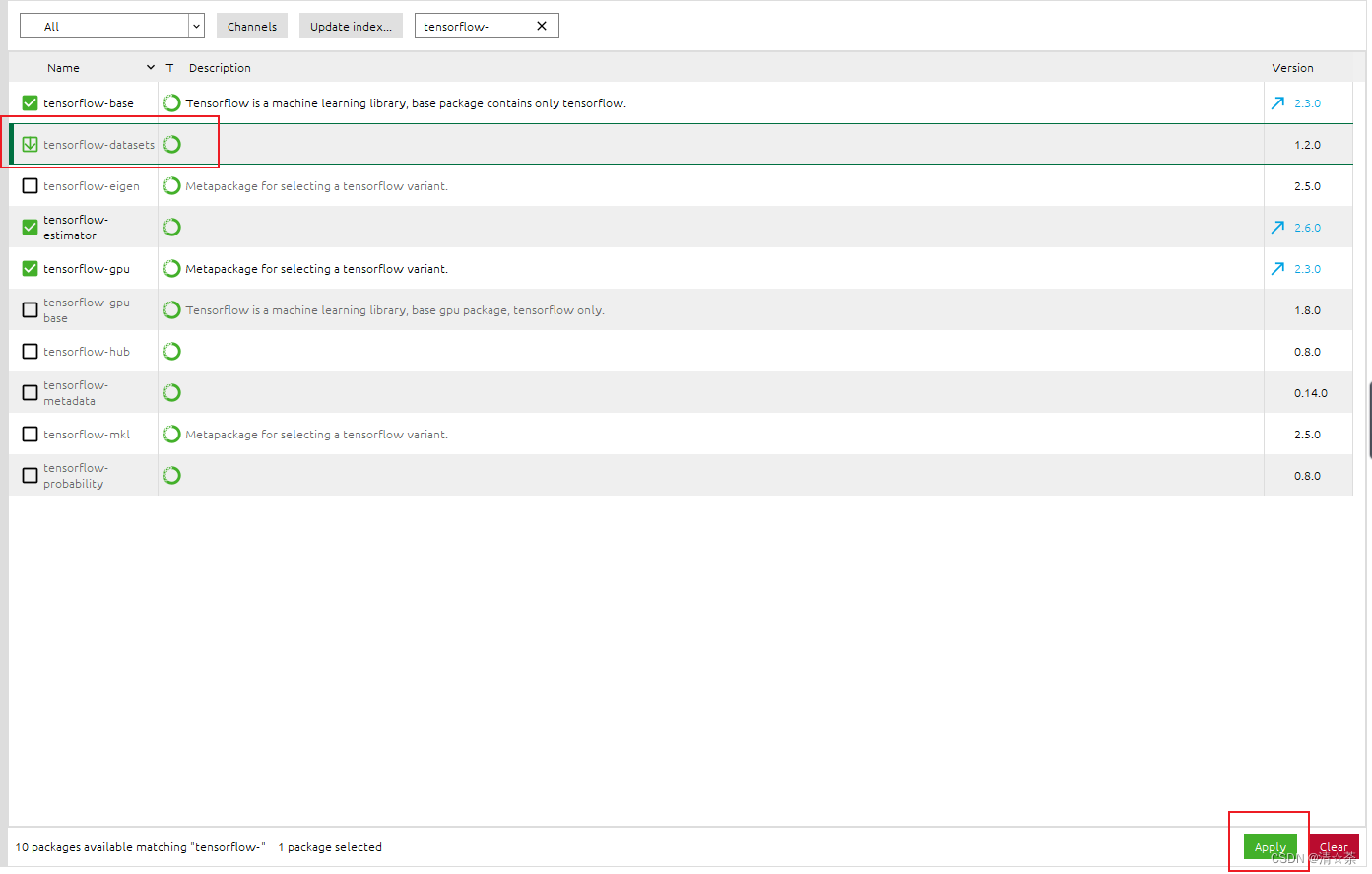
在tensorflow中内置了一些数据集,使用IMDB数据集。本次实验可以使用,需要下载好tensorflow-datasets库。
安装tensorflow-datasets:
首先确认正在使用的Tensorflow版本:
import tensorflow as tf
print(tf.__version__)
如果是1.XX的版本需要执行一下命令升级:
tf.enable_eager_execution()
如果是2.XX版本不要考虑。
import tensorflow_datasets as tfds
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import tensorflow as tf
import io
imdb,info = tfds.load("imdb_reviews",with_info=True,as_supervised=True)
train_data,test_data = imdb['train'],imdb['test']
#定义列表,来存储训练数据和测试数据中的句子和标签
training_sentences = []
training_labels = []
testing_sentences = []
testing_labels = []
#遍历训练数据,将句子和标签放入列表中
for s,l in train_data:
training_sentences.append(str(s.numpy())) #s表示训练数据中的句子
training_labels.append(l.numpy()) #l表示训练数据中的标签
#遍历测试数据,将句子和标签放入列表中
for s,l in test_data:
testing_sentences.append(str(s.numpy))
testing_labels.append(l.numpy())
#将标签列表转换为numpy类型
training_labels_final = np.array(training_labels)
testing_labels_final = np.array(testing_labels)
#对句子进行词条化
vocab_size = 10000
embedding_dim=16
max_length = 120
trunc_type='post'
oov_tok="<OOV>"
#创建一个分词器的实例,给出词典的大小和未登陆词的表示方法
tokenizer = Tokenizer(num_words=vocab_size,oov_token=oov_tok)
#对训练数据创建词典
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
#根据词典的编码将句子序列化
sequences = tokenizer.texts_to_sequences(training_sentences)
#截断或补齐句子到相同的长度,120个数字
padded = pad_sequences(sequences,maxlen=max_length,truncating=trunc_type)
#对测试数据进行相同的处理
#测试数据集是根据训练数据集所产生的词典,来进行编码和序列化的。
testing_sentences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sentences,maxlen=max_length)
#设计神经网络
model = tf.keras.Sequential([
#嵌入层:结果会得到一个二维数组,行和列分别是句子的长度和向量的维度
tf.keras.layers.Embedding(vocab_size,embedding_dim,input_length=max_length),
#将嵌入的结果展平
#tf.keras.layers.GlobalAveragePooling1D(), #全局平均池化层也可以用来展平,它在每个向量的维度上取平均值进行输出
tf.keras.layers.Flatten(),
#送入全连接神经网络进行分类
tf.keras.layers.Dense(6,activation='relu'),
tf.keras.layers.Dense(1,activation='sigmoid')
])
#编译模型,并打印模型的摘要信息
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
#将序列化后的训练数据和标签作为训练数据集
num_epochs=10 #训练周期为10
model.fit(padded,training_labels_final,
epochs=num_epochs,
validation_data=(testing_padded,testing_labels_final))
#得到第0层的权值
e=model.layers[0]
weights=e.get_weights()[0]
print(weights.shape)
#为了对其进行可视化,对word_index的顺序进行改变
reverse_word_index = dict([(value,key) for (key,value) in word_index.item()])
#将更改后的word_index以及嵌入层的权重,分别写入out_v,out_m
out_v = io.open('vecs.tsv','w',encoding='utf-8')
out_m=io.open('meta.tsv','w',encoding='utf-8')
for word_num in range(1,vocab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word+"\n")
out_v.write('\t'.join([str(x) for x in embeddings])+"\n")
out_v.close()
out_m.close()
项目实战-讽刺数据集的词嵌入
子词对分类器的影响
不完整的子词,很难学习到单词的正确的语意和情感。
链接:https://github.com/tensorflow/datasets/blob/master/docs/dataset_collections.ipynb
import json
import tensorflow as tf
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
vocab_size = 10000
embedding_dim = 16
max_length = 100
trunc_type='post'
padding_type='post'
oov_tok = "<OOV>"
training_size = 20000
with open("../../tensorflow_datasets/sarcasm.json", 'r') as f:
datastore = json.load(f)
sentences = []
labels = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
training_sequences = tokenizer.texts_to_sequences(training_sentences)
training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
num_epochs = 30
training_padded = np.array(training_padded)
training_labels = np.array(training_labels)
testing_padded = np.array(testing_padded)
testing_labels = np.array(testing_labels)
history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2)
import matplotlib.pyplot as plt
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_sentence(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
print(decode_sentence(training_padded[0]))
print(training_sentences[2])
print(labels[2])
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(1, vocab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()
sentence = ["granny starting to fear spiders in the garden might be real", "game of thrones season finale showing this sunday night"]
sequences = tokenizer.texts_to_sequences(sentence)
padded = pad_sequences(sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
print(model.predict(padded))
项目实战-imdb评论子词数据集的词嵌入
# NOTE: PLEASE MAKE SURE YOU ARE RUNNING THIS IN A PYTHON3 ENVIRONMENT
import tensorflow as tf
print(tf.__version__)
# If the import fails, run this
# !pip install -q tensorflow-datasets
import tensorflow_datasets as tfds
imdb, info = tfds.load("imdb_reviews/subwords8k", with_info=True, as_supervised=True)
train_data, test_data = imdb['train'], imdb['test']
tokenizer = info.features['text'].encoder
sample_string = 'TensorFlow, from basics to mastery'
tokenized_string = tokenizer.encode(sample_string)
print ('Tokenized string is {}'.format(tokenized_string))
original_string = tokenizer.decode(tokenized_string)
print ('The original string: {}'.format(original_string))
# expected output:
# Tokenized string is [6307, 2327, 4043, 2120, 2, 48, 4249, 4429, 7, 2652, 8050]
# The original string: TensorFlow, from basics to mastery
for ts in tokenized_string:
print ('{} ----> {}'.format(ts, tokenizer.decode([ts])))
BUFFER_SIZE = 25000
BATCH_SIZE = 1
train_data = train_data.shuffle(BUFFER_SIZE)
train_data = train_data.padded_batch(BATCH_SIZE)
test_data = test_data.padded_batch(BATCH_SIZE)
embedding_dim = 64
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
num_epochs = 10
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
history = model.fit(train_data, epochs=num_epochs, validation_data=test_data)
import matplotlib.pyplot as plt
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(1, tokenizer.vocab_size):
word = tokenizer.decode([word_num])
embeddings = weights[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()
# try:
# from google.colab import files
# except ImportError:
# pass
# else:
# files.download('vecs.tsv')
# files.download('meta.tsv')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









