






青年大学习观看人员审查系统(3.0版本,带图形化操作界面)
来了来了,带有图形化界面的青年大学习人员审查系统来了!!!
 老规矩,话不多说,直接上代码和下载地址链接: https://pan.baidu.com/s/1VHM0NLMfOP2b8T_xxwIhKQ
老规矩,话不多说,直接上代码和下载地址链接: https://pan.baidu.com/s/1VHM0NLMfOP2b8T_xxwIhKQ
提取码:gxzw
3.0版本的主函数与2.0版本的主函数不同的地方在于加入了python自带的tkinter库,完成了图形化界面的设置。相同点在于都是使用模块化系统化编程的方法,利用主函数调用其他模块函数。(在此,特别感谢 请选择大佬 的文章python通过对话框实现文件或文件夹路径的选择并获得路径所带来的启发)
from tkinter import *
from tkinter import filedialog
from sxit_ky import sxit_ky
from sxit_ky_students import sxit_ky_students
from not_watching import not_watching
from people_not_watching import people_not_watching
import time
root = Tk()
root.geometry('600x220')
#root.withdraw()
v1 = StringVar()
v2 = StringVar()
root.title("青年大学习观看人员审查系统")
Label(root,text="青年大学习观看人员审查系统",fg="red",bg="white",width=25,font="14").grid(row=0,column=1,padx=10,pady=10)
Label(root,text="省属高校文件路径",font="14").grid(row=1,column=0,padx=10,pady=10)
Label(root,text="院/系学生文件路径",font="14").grid(row=2,column=0,padx=10,pady=10)
e_1 = Entry(root,width=32,textvariable=v1).grid(row=1,column=1,padx=10,pady=10)
e_2 = Entry(root,width=32,textvariable=v2).grid(row=2,column=1,padx=10,pady=10)
def personnel_query():
sxit_ky(str(v1.get()))
#程序进行延迟是为了避免程序所需文件尚未生成完毕后直接运行产生报错
time.sleep(10)
sxit_ky_students(str(v2.get()))
time.sleep(5)
not_watching()
time.sleep(5)
people_not_watching()
"""print("%s" % v1.get())
print(type(v1.get()))
print("%s" % v2.get())
print(type(v2.get()))"""
print("运行完成!!!")
def select_file_province():
master=Tk()
master.withdraw()
Filepath1 = filedialog.askopenfilename()
v1.set(Filepath1)
def select_file_school():
master=Tk()
master.withdraw()
Filepath2 = filedialog.askopenfilename()
v2.set(Filepath2)
Button(root,text="选择文件",font="14",command=select_file_province).grid(row=1,column=2,padx=10,pady=10)
Button(root,text="选择文件",font="14",command=select_file_school).grid(row=2,column=2,padx=10,pady=10)
Button(root,text="开始查询",font="14",width=10,command=personnel_query).grid(row=3,column=0,padx=10,pady=10)
Button(root,text="退出",font="14",width=10,command=root.quit).grid(row=3,column=2,padx=10,pady=10)
root.mainloop()
其他模块函数
(从总名单中生成本院/系观看青年大学习人员名单)
#将院/系青年大学习观看人员名单打印
import xlrd
from openpyxl import load_workbook
from pypinyin import pinyin
def sxit_ky(Provincial_Universities):
fi=open("data\\new_data\\sxit_ky_people.txt","w")
#创建一个txt文件储存学生全部数据
#fo=open("data\\new_data\\sxit_ky_people_full.txt","w")
#doc = xlrd.open_workbook('123.xlsx')
route='data\\old_data\\'+str(Provincial_Universities)+'.xlsx'
#wb = load_workbook('data\\old_data\\Provincial_Universities.xlsx')
wb = load_workbook(route)
#ws = doc.sheet_by_index(0)
sheets = wb.worksheets
print(sheets)
sheet = sheets[0]
print(sheet)
rows = sheet.rows
print(rows)
for row in rows:
#print(row)
row_val = [col.value for col in row]
#print(row_val)
#print(type(row_val[1]))
if('学校名,院/系名' in str(row_val[2])): #这里的‘学校名,院/系名’写你想筛查的目标名(一般直接复制excel文件中的名字即可),row_val[2]是你的'学校名,院/系名'在表格中所对应的索引值,不要瞎写,可能会导致逻辑错误。
#print(row_val)
#只生成学生姓名
try:
fi.write(str(row_val[0])+'\n')
except UnicodeEncodeError as e:
fi.write(str(pinyin(row_val))+'\n')
#生成学生全部数据
"""
try:
fo.write('姓名:'+row_val[0]+',')
fo.write('电话:'+row_val[1]+',')
fo.write('学校:'+row_val[2]+',')
fo.write('学号:'+row_val[3])
fo.write('\n')
except UnicodeEncodeError as e:
fo.write('姓名:'+str(pinyin(row_val[0]))+',')
fo.write('电话:'+row_val[1]+',')
fo.write('学校:'+row_val[2]+',')
fo.write('学号:'+row_val[3])
fo.write('\n')
"""
"""for i in row_val:
if str(i[2])=='学校名,院/系名':
fi.write(row_val[0])"""
print(' ')
#关闭文件
fi.close()
#fo.close()
"""print(ws.nrows)
cell_11=sheet.cell(2,2).value
print(cell_11)
print(type(cell_11))
"""
(生成本院/系人员名单)
#生成院/系人员名单
import xlrd
from openpyxl import load_workbook
from pypinyin import pinyin
def sxit_ky_students(ky_students):
fi=open("data\\new_data\\sxit_ky_students.txt","w")
#doc = xlrd.open_workbook('123.xlsx')
route = 'data\\old_data\\'+str(ky_students)+'.xlsx'
#wb = load_workbook('data\\old_data\\院/系人员名单.xlsx')
wb = load_workbook(route)
#ws = doc.sheet_by_index(0)
sheets = wb.worksheets
print(sheets)
sheet = sheets[0]
print(sheet)
rows = sheet.rows
print(rows)
for row in rows:
#print(row)
row_val = [col.value for col in row]
#print(row_val)
#print(type(row_val[1]))
#if('大学' in str(row_val[2])):
#print(row_val)
try:
fi.write(str(row_val[3])+'\n')
except UnicodeEncodeError as e:
fi.write(str(pinyin(row_val[3]))+'\n')
"""for i in row_va1:
#if i[1]=='学校名,院/系名':
print(i[1])"""
print(' ')
fi.close()
"""print(ws.nrows)
cell_11=sheet.cell(2,2).value
print(cell_11)
print(type(cell_11))
"""
(生成本院/系未观看人员名单,初步检测,可能会有错误,以二次检测结果为准)
#生成院/系未观看人员名单
def not_watching():
#route_sxit_ky_people = 'data\\new_data\\'+str(sxit_ky_people)+'.txt'
#route_sxit_ky = 'data\\new_data\\'+str(sxit_ky)+'.txt'
#routenot_watching = 'data\\new_data\\'+str(not_watching)+'.txt'
fi = open('data\\new_data\\sxit_ky_people.txt',"r")
fo = open('data\\new_data\\sxit_ky_students.txt',"r")
fn = open("data\\new_data\\not_watching.txt","w")
data = fi.readlines()
data_ky = fo.readlines()
print(len(data))
for i in range(len(data_ky)):
a=data_ky[i]
a = ''.join(a.split())
a = a+'\n'
#print(type(a))
if(a not in data):
fn.write(a)
#print("1")
fi.close()
fo.close()
fn.close()
(生成本院/系未观看人员名单,二次检测。以本次检测结果为准)
#将青年大学习未观看人员名单打印
import xlrd
from openpyxl import load_workbook
from pypinyin import pinyin
def people_not_watching():
#route_not_watching = 'data\\new_data\\'+str(not_watching)+'.txt'
#route_sxit_ky = 'data\\new_data\\'+str(sxit_ky)+'.txt'
fi=open('data\\new_data\\not_watching.txt',"r")
fo=open("data\\new_data\\people_not_watching.txt","w")
fn=open('data\\new_data\\sxit_ky_people.txt',"r")
#doc = xlrd.open_workbook('123.xlsx')
wb = load_workbook('data\\old_data\\院/系人员名单.xlsx')
#ws = doc.sheet_by_index(0)
sheets = wb.worksheets
print(sheets)
people=fi.readlines()
print(people)
num_people=fn.readlines()
sheet = sheets[0]
print(sheet)
rows = sheet.rows
print(rows)
i=0
for row in rows:
#print(row)
row_val = [col.value for col in row]
#print(row_val)
#print(type(row_val[1]))
#for i in range(0,1062):
if(str(row_val[3])+'\n' in people):
print(row_val)
#try:
fo.write(str(row_val)+'\n')
continue
#except UnicodeEncodeError as e:
else:
i+=1
continue
"""try:
fi.write('姓名:'+row_val[0]+',')
fi.write('电话:'+row_val[1]+',')
fi.write('学校:'+row_val[2]+',')
fi.write('学号:'+row_val[3])
fi.write('\n')
except UnicodeEncodeError as e:
fi.write('姓名:'+str(pinyin(row_val[0]))+',')
fi.write('电话:'+row_val[1]+',')
fi.write('学校:'+row_val[2]+',')
fi.write('学号:'+row_val[3])
fi.write('\n')"""
"""for i in row_val:
if str(i[2])=='学校名,院/系名':
fi.write(row_val[0])"""
print(' ')
fi.close()
fo.close()
fn.close()
"""print(ws.nrows)
cell_11=sheet.cell(2,2).value
print(cell_11)
print(type(cell_11))
"""
(生僻字处理函数)
from pypinyin import pinyin
try:
fo.write('姓名:'+row_val[0]+',')
fo.write('电话:'+row_val[1]+',')
fo.write('学校:'+row_val[2]+',')
fo.write('学号:'+row_val[3])
fo.write('\n')
except UnicodeEncodeError as e:
fo.write('姓名:'+str(pinyin(row_val[0]))+',')
fo.write('电话:'+row_val[1]+',')
fo.write('学校:'+row_val[2]+',')
fo.write('学号:'+row_val[3])
fo.write('\n')
"""
这里就不对模块函数做具体分析讲解了,如果对模块函数有什么疑问,大家可以阅读我的另外两篇文章青年大学习人员审查系统(2.0版本)
利用python进行青年大学习人员审查或在评论区留言提问
3.0版本操作讲解
本系统所运行的程序文件是青年大学习人员审查系统.py不是main.py!!!
如下图所示,共有四个按键,‘选择文件按键’作用是能够让用户自主对所要审查的文件进行选择,不必像1.0版本和2.0版本一样要在使用前将源文件移动到指定目录下,简化了操作(选择源文件的时候选对了,别选反了)。选择完文件后所选择的文件路径(绝对路径)将会出现在输入框中,请检查文件路径是否正确。选择完毕后就可以开始查询了。但是,重要的地方来了,划重点:点击开始查询后,此界面可能会假死,不要管!!这种情况是因为程序运行所导致的,不要乱点乱按,否则真的可能会死机!!等待2-3分钟后如果没有任何反应,那就是真死了0.0。
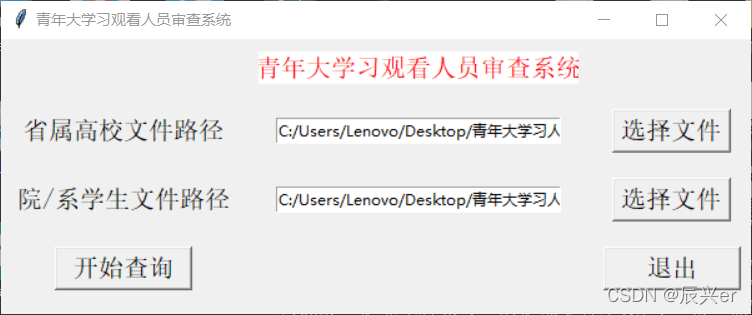 如果在cmd中看到运行完成的提示,就可以关闭程序去查看生成的txt文件了(这里再说一下最终生成文件的路径:青年大学习人员审查系统\data\new_data\people_not_watching.txt,别开错了)
如果在cmd中看到运行完成的提示,就可以关闭程序去查看生成的txt文件了(这里再说一下最终生成文件的路径:青年大学习人员审查系统\data\new_data\people_not_watching.txt,别开错了)

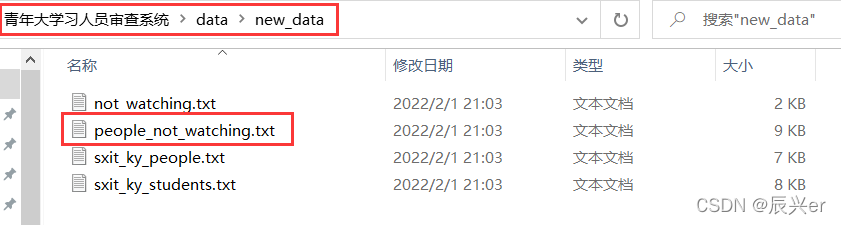
至此,3.0版本的青年大学习人员审查系统就都介绍完了,操作是不是很简单(不过作者要在这里说一句,本系统的运行需要python3.0以上的环境才可正常运行,否则会报错)
能看到这里的hxd们应该都是本着学习的心态来的,希望各位能够帮忙点个赞,谢谢各位!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









