







Spqrk应用基础:
Pyspark –master<master-url>(--jars) 按指定模式运行pyspark


若 master-url=yarm则默认为client模式
若直接pyspark运行则默认local[*]模式
打开spark:
Cd /usr/local/spark 移动到spark文件位置(/usr/local是通常的文件安装位置)
./bin/pyspark 打开
执行.py代码
Cd /usr/local/spark/mycode/python 移动到.py文件位置,通常为该路径
Python3 test.py 执行
或者用spark自带的python执行:
格式:
语法(python位置+文件位置):![]() 或
或 用\>换行
用\>换行
Spark集群环境搭建:课时22
RDD编程
创建RDD:两种方法
法一:从文件系统加载
使用函数.testfile() 括号内是数据,可以是:本地数据、HDFS数据、云端数据
例: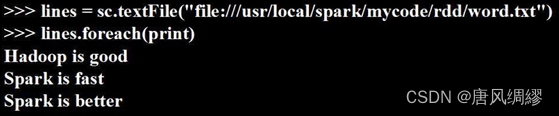
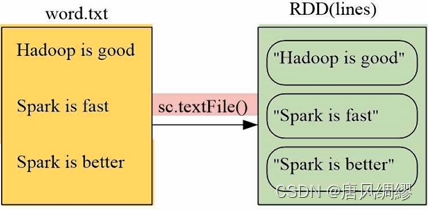
一个○是一个RDD元素。sc是sparkcontext(任务控制节点、指挥官)。如果是pyspark的交互式执行环境,系统会默认创建sc,但如果要编写独立执行文件,需要手动编写。例子中>>>明显是交互式环境。文件目录中用了三个/表示是本地文件。
RDD保存到本地:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









