







什么是性能测试
性能测试是一种软件测试类型,用于评估系统的速度、稳定性、可伸缩性和响应时间等性能特征。其主要目的是确保应用程序在预期的负载条件下能够正常运行,并找出可能的性能瓶颈。性能测试包括以下几种类型:
负载测试(Load Testing):测试系统在预期负载条件下的性能表现。目的是确定系统在正常和高峰负载下的表现。
压力测试(Stress Testing):测试系统在超出预期负载的条件下的表现,目的是确定系统的极限,并观察在超负荷情况下系统是否会崩溃以及如何恢复。
容量测试(Capacity Testing):确定系统能够处理的最大用户数量和数据量,以了解系统的可伸缩性。
稳定性测试(Stability Testing)或持久性测试(Soak Testing):长时间运行系统,测试其在持续负载下的稳定性,以发现内存泄漏或其他资源耗尽的问题。
响应时间测试(Response Time Testing):测量系统对各种请求的响应时间,以确保其满足预定的性能标准。
性能测试可以通过多种工具和技术来进行,如JMeter、LoadRunner、Gatling等。测试结果可以帮助开发团队优化系统性能,确保在实际使用环境中系统能够高效运行。
为什么要做性能测试
一般来说,我们我们做性能测试的标准如下:
- 获取性能的指标,作为性能指标的标准
- 应用程序是否能够满足系统要求的各项性能指标
- 应用程序是否能够处理预期的用户负载并有盈余能力
- 应用程序能否处理业务所需要的事务数量。
- 在预期和非预期的用户负载下,应用程序是否稳定
- 是否能够保证用户能够在使用软件获得舒服的体验
性能测试实施的流程
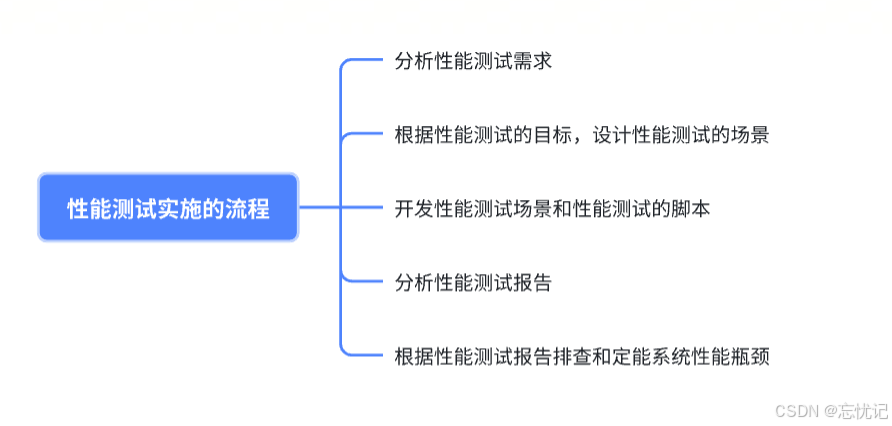
分析性能测试需求
根据性能测试的目标,设计性能测试的场景
开发性能测试场景和性能测试脚本
分析性能测试报告
根据性能测试报告排查和定能系统的性能瓶颈
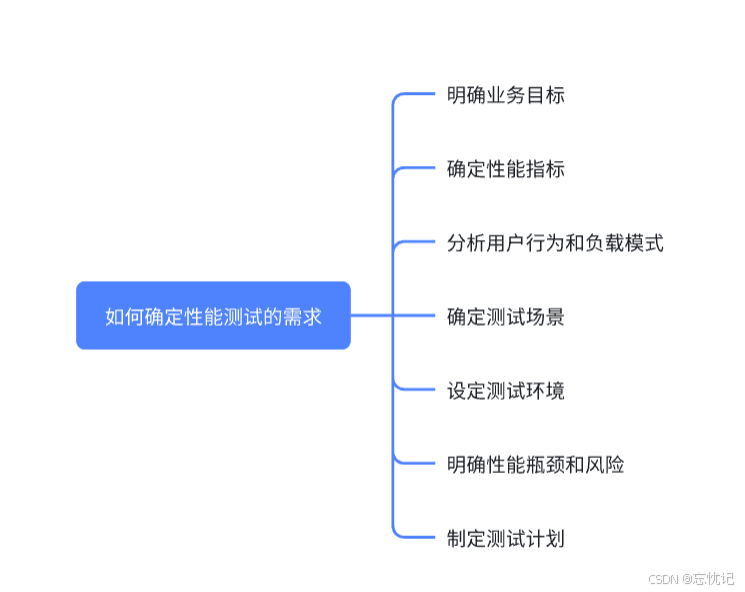
如何确定性能测试的需求
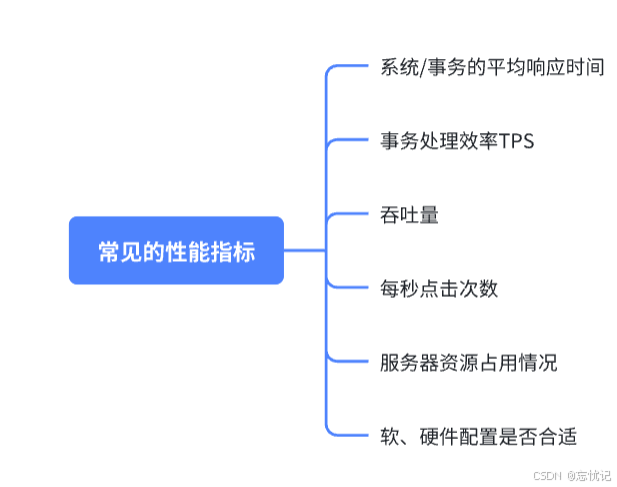
性能测试的关键指标
常见性能测试的概念属于介绍
-
并发用户数
定义:指在同一时间内同时访问和使用系统的用户数量。
重要性:并发用户数是衡量系统能同时处理多少用户请求的重要指标,直接影响系统的响应时间和稳定性。 -
响应时间/平均响应时间
定义:指用户发出请求到系统返回响应所用的时间。平均响应时间是所有请求响应时间的平均值。
重要性:响应时间直接影响用户体验,较长的响应时间可能导致用户流失。 -
事务的响应时间
定义:指完成一个完整事务(如登录、搜索、提交订单等)所需的时间。
重要性:事务的响应时间是衡量系统处理特定业务流程效率的重要指标。 -
每秒事务通过数
定义:系统在每秒钟能够处理的事务数量。
重要性:TPS是衡量系统处理能力和吞吐量的重要指标,较高的TPS表示系统能够高效处理大量请求。 -
点击率
定义:系统在每秒钟接收到的用户请求数或点击数。
重要性:点击率可以反映系统的负载情况,较高的点击率可能需要更高的资源和性能支持。 -
吞吐量
定义:单位时间内系统能够处理的请求或数据量,通常以请求数/秒或字节数/秒表示。
重要性:吞吐量是衡量系统性能和容量的重要指标,影响系统的处理能力和响应效率。 -
思考时间
定义:用户在两个连续操作之间所花费的时间。
重要性:思考时间反映了用户在使用系统过程中的行为模式,在性能测试中模拟真实用户行为时需考虑思考时间。 -
资源利用率
定义:系统在运行过程中使用的资源比例,包括CPU、内存、磁盘I/O、网络带宽等。
重要性:资源利用率是衡量系统效率和性能的重要指标,高资源利用率可能导致系统瓶颈和性能下降。
性能测试模型
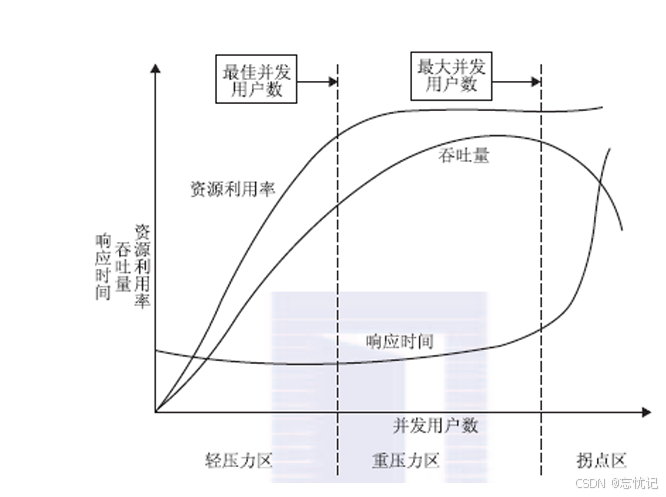
性能测试曲线模型是一条随着测试时间不断变化的曲线,与服务器资源,用户数或其他的性能指标密切相关的曲线。
一般的性能测试曲线图主要分为三个区域,分别是:light load(轻压力区),heavy load(重压力区)和 Buckle Zone。
图中的三条曲线,分别代表:Utilization(资源利用率,指软硬件资源),Throughput(吞吐量,即单位时间内处理请求的数量),Response Time(响应时间)。
图中坐标轴的横轴从左到右表示并发用户数(Number of Concurrent Users)的不断增长。
分析:
资源利用率在第一区域稳定增长,在第二区域小幅增长,在第三区域呈直线,表示饱和。
响应时间随着并发用户数的增加,在前两个区域基本平稳,小幅递增,在第三个区域急速递增,产生拐点。
同时,吞吐量随着并发用户数的增加,请求增加,在第一区域基本稳定上升,在第二区域处理达到顶点,随后开始下降。
当系统的负载等于最佳并发用户数时,整体效率最高,也没有资源被浪费,用户也不需要等待;当系统负载处于最佳并发用户数和最大用户并发数之间时,系统可以继续工作但用户的等待时间延长;当系统负载大于最大并发用户数时,用户满意度基本为零,甚至放弃访问。
可能这个模型看起来有一些吃力,我们举一个实际的例子,大家都做过地铁吧
假设;
某地铁站进站只有3个刷卡机。
人少的情况下,每位乘客很快就可以刷卡进站,假设进站需要1s。
乘客耐心有限,如果等待超过30min,就暴躁、唠叨,甚至放弃。
场景一:只有1名乘客进站时,这名乘客可以在1s的时间内完成进站,且只利用了一台刷卡机,剩余2台等待着。
场景二:只有2名乘客进站时,2名乘客仍都可以在1s的时间内完成进站,且利用了2台刷卡机,剩余1台等待着。
场景三:只有3名乘客进站时,3名乘客还能在1s的时间内完成进站,且利用了3台刷卡机,资源得到充分利用。
场景四:A、B、C三名乘客进站,同时D、E、F乘客也要进站,因为A、B、C先到,所以D、E、F乘客需要排队。那么,A、B、C乘客进站时间为1s,而D、E、F乘客必须等待1s,所以他们3位在进站的时间是2s
场景五:假设这次进站一次来了9名乘客,有3名的“响应时间”为1s,有3名的“响应时间”为2s(等待1s+进站1s),还有3名的“响应时间”为3s(等待2s+进站1s)。
场景六:如果地铁正好在火车站,每名乘客都拿着大小不同的包,包太大导致卡在刷卡机堵塞,每名乘客的进站时间就会又不一样。刷卡机有加宽的和正常宽度的两种类型,那么拿大包的乘客可以通过加宽的刷卡机快速进站(增加带宽)。
场景七:进站的乘客越来越多,3台刷卡机已经无法满足需求,为了减少人流的积压,需要再多开几个刷卡机,增加进站的人流与速度(提升TPS、增大连接数)。
场景八:终于到了上班高峰时间了,乘客数量上升太快,现有的进站措施已经无法满足,越来越多的人开始抱怨、拥挤,情况越来越糟。单单增加刷卡机已经不行了,此时的乘客就相当于“请求”,乘客不是在地铁进站排队,就是在站台排队等车,已经造成严重的“堵塞”,那么增加发车频率(加快应用服务器、数据库的处理速度)、增加车厢数量(增加内存、增大吞吐量)、增加线路(增加服务的线程)、限流、分流等多种措施便应需而生。
性能测试方法



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











