










提出一个模型:DEEPCTRL
下图是模型算法的描述
 算法解释:
算法解释:
我们建议通过引入数据编码器
ϕ
\phi
ϕd和规则编码器
ϕ
\phi
ϕr这两个通道来改进规范化训练方法。
这样,我们的目标是使每个编码器分别学习潜在表示(zd和zr),对应于从标记数据和规则中提取的信息。然后,将这两个表示随机连接(记为⊕),得到一个表示z。我们使用的是小批量训练,就是有Db的存在。为了调整数据与规则编码的相对贡献,我们使用随机变量α∈[0,1],它也将(zd, zr)与相应的目标(Ltask, Lrule)耦合(算法1中的第4和第5行)。α从分布P (α)中采样。
关于模型类型:
DEEPCTRL是模型类型不可知的——我们可以根据类型和任务为编码器和决策块选择适当的归纳偏差。例如,如果输入数据是图像,而任务是分类,编码器可以是卷积层,以提取与局部空间相干相关的隐藏表示,决策块可以是MLP后面跟着一个softmax层。
关于α:
使用随机α的动机是鼓励学习与一系列值的映射,以便在推理时,模型可以使用任何特定的选择值产生高性能。决策块的输出在整个目标中使用。通过修改推理时的控制参数α,用户可以控制模型的行为,使其适应不可见数据。增加α的值可以增强规则对输出决策的强度。设置α = 0会使规则在推理上的贡献最小化,但从实验中可以看出,由于在训练过程中考虑了较广的α范围,因此结果仍然可以优于传统训练。通常,在给定特定性能、透明度和可靠性目标的情况下,一个中间α值产生最优解。为了确保一个模型在α→0或α→1时表现出明显的和鲁棒的行为,从而在之后进行精确的插值,我们建议在两个极端处对α进行更多的采样,而不是从两个极端均匀地采样。为此,我们选择从Beta分布(Beta(β, β))中取样。当β = 0.1 in时,我们观察到较强的结果。在第5节中,我们进一步研究了α的先验选择的影响。由于Beta分布是高度极化的,每个编码器都被鼓励学习与相应编码器相关联的不同表示,而不是混合表示。在[1,33]中也考虑了类似的采样思想,以有效地对混合权重进行采样,以进行表示学习。
我们主要的公式:
L=Ltask+
λ
\lambda
λLrule
Ltask是基于目标的,Lrule是基于规则的。
考虑到两者的计算尺度可能不同(比如一个算出来为10,20,一个算出来是0.1,0.2,我们在训练集上计算初始的损失值Lrule,0,Ltask,0,引入一个尺度参数
ρ
\rho
ρ。
公式如下:
ρ
\rho
ρ=Lrule,0/Ltask,0
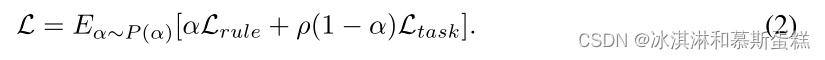
处理基于规则的部分(拓展了基于规则的范围):
我们某些时刻可以直接把规则转换为可微形式,比如如果x<5,…这种,但是很多时候是不可微的,需要进行转化,这里的转化方法是:
输入特征x,修改原始输出的元素y~,为其构造基于规则的约束Lrule。
比如面对不可微的规则:【当a < xk(其中a是一个常数, xk是第k个特征)时,第j个类的概率高一些】
我们的转化:【我们只会考虑xp是一个有效的摄动输入,当xk <a和a< x~p, k~,并且ˆyp从xp计算得到。Lrule定义为:】
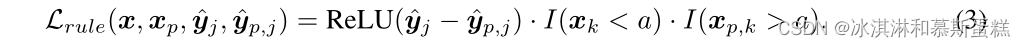
算法二:DEEPCTRL通过基于微扰的规则集成。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









