









 本文详细介绍了Avatar Hadoop高可用性设置中的NameNode和standbyNameNode管理,包括如何正常启停standbyNameNode,处理Nfs故障导致的standbyNode down问题,以及NameNode无中断服务的重启流程。内容涵盖故障总结、解决办法和关键步骤,确保集群稳定运行。
本文详细介绍了Avatar Hadoop高可用性设置中的NameNode和standbyNameNode管理,包括如何正常启停standbyNameNode,处理Nfs故障导致的standbyNode down问题,以及NameNode无中断服务的重启流程。内容涵盖故障总结、解决办法和关键步骤,确保集群稳定运行。
Avatar hadoop HA (高可用)
一.NameNode 、standbyNameNode 与 NFS
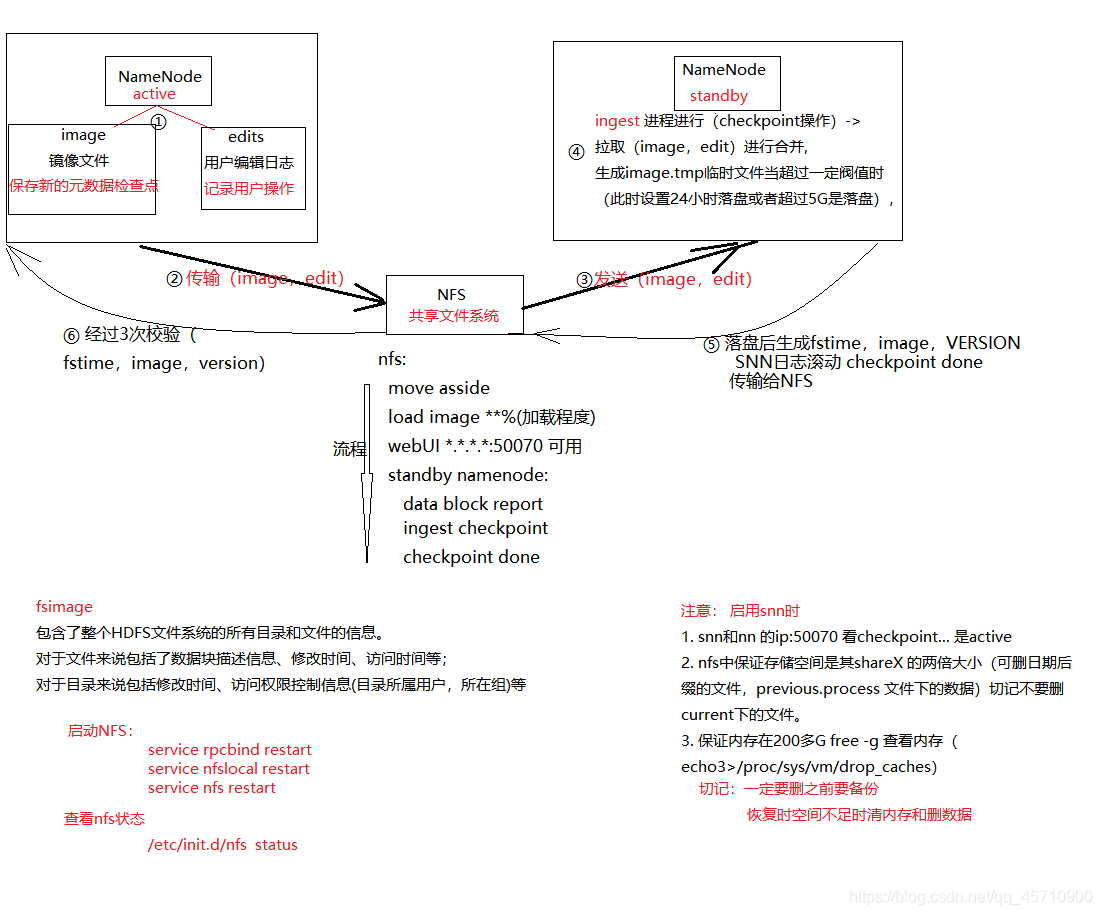
二.故障总结
1. 启停 standbyNameNode
1)停止 standby
/home/work/software/hadoop/bin/hadoop-daemon.sh stop avatarnode -one -standby
2)启动 standby
- 启动之前需要关注一下本地磁盘(主和被的都要检查,目前在启动之前本地空间最好剩余在120G以上)和 nfs 磁盘空间是否充足
查看磁盘空间使用情况:df -h
如果空间不充足,可删除备份文件(带日期的image和edit文件,防止意外情况,最好是在删除之前做备份):
/home/work/hadoop/nfs_mount/ha/share/share1/image:2017-、edits:2017-
/home/work/hadoop/namenode/image:2017-、edits:2017- - 检查Standby的内存使用情况,要保证内存充足,目前JVM设置为230G,所以至少要保证内存在230G以上。可以使用root用户尝试清理内存:
free -g 查看内存
echo 3 >/proc/sys/vm/drop_caches - 启动:/home/work/software/hadoop/bin/hadoop-daemon.sh start avatarnode -one -standby
3)关注一下日志中是否有报错
- tailf /home/work/hadoop/log/master.dc.log | grep ERROR
- 如果发现报错信息:“Unable to move current for …”
- 在 r1 和 r4 两台机器上,看看这个目录中的文件是哪个进程在使用(使用root用户执行):
lsof /home/work/hadoop/nfs_mount/ha/share/share1/image/previous.checkpoint/*
4)确认checkpoint是否正常完成
1、确认webUI ip:50070 界面能够打开,且退出了安全模式
2、检查nfs share目录显示active
3、检查主、被namenode及share0、share1上最新的fstime,是否为系统最近时间
4、过滤standby namenode日志,过滤关键字为check,确定checkpoint done
2. Nfs故障导致的snn down问题恢复:
1)问题:
由于nfs服务不正常(例如nfs存储空间满),因此active nn nfs同步元数据目录报错;
2)处理办法:
-
备份nfs下所有的share目录(share0(r1对应share0)、share1(r4对应share1));
-
确认第一步完成后, 且standby nn进程节点已经挂掉,清空nfs子目录中的数据(删除之前一定要做备份。先确认谁是主namenode,比如r1是主,就不要去删shere0下的文件,但如果现在是r4是主,就不要删share1下文件。尤其是主对应的current目录下(包括fsimage和edit)的文件千万不要进行删除,优先删除日期后缀的文件,空间还是不足的情况下可以考虑删除previous里边的文件),不要直接删除所有子目录, 删除文件即可
以保证nfs存储空间的充足; -
检查hdfs服务是否正常;检查namenode jvm的可用内存情况,linux服务器的可用内存情况,确保有一定的内存空间情况下,
执行./bin/hadoop dfsadmin -saveNamespace
刷新最新的元数据到本地磁盘文件和nfs;
注意: saveNamespace执行需要运行一段时间(大概十分钟左右);且这个过程active namenode会进入安全模式,所以执行过程中集群无法对外提供写服务;
-
确认第三步执行完成,去active namenode web页面检查对应的nfs share目录,如果显示为active,说明操作成功;
-
再次检查hdfs服务是否正常,如果正常, 执行重启standby nn操作,参考文档(standby启停.txt)进行操作。
3.NameNode重启流程(不中断服务)
1)提要:
- 本流程适用于 CERT 项目 hadoop集群:r1.hadoop为 active,r4.hadoop为 standby
- 准备好需要调整的配置项目
- 所有操作使用 work 用户
2)重启
1、切换 NameNode
确保当前没在做 checkpoint
r4:./bin/hadoop org.apache.hadoop.hdfs.AvatarShell -one -faileoverprepare
r4:./bin/hadoop org.apache.hadoop.hdfs.AvatarShell -zero -shutdownAvatar
r4:./bin/hadoop org.apache.hadoop.hdfs.AvatarShell -one -setAvatar primary
观察客户端是否正常
注意:
a. 要通过客户端去验证服务是否正常(不能通过namenode节点去验证服务), 例如通过hbase regionserver节点上的hadoop客户端验证,或者
通过穿透加载log验证写如hdfs数据是否正常;
b. 一定按照顺序执行上述步骤,每一步执行有可能会卡住或者失败, 需要重新执行一边。
2、重启 r1 节点(重启之前都要检查nfs空间和本地空间,以及内存使用情况,内存剩余应该大于JVM的设置。)
调整本次需要修改的配置项目;
启动之前,检查本地磁盘和 NFS 目录空间是否充足,:
1).如果r1节点上本地存储或者nfs空间不足,需要手动把备份目录scp到其他服务器上,
md5sum对比确认之后, 删除文件;
删除文件注意事项:优先删除本地和nfs上以日期结尾的备份fsimage和edit文件。
比如/home/work/hadoop/namenode/image:2017-*。
如果空间还是不够,可以删除previous文件夹里边的文件
(切记不要删目录,只删文件,删之前一定要备份)
2)启动之前一定检查内存使用情况,检查r4的web界面上nfs目录为active。
3)启动命令:
~/software/hadoop/bin/hadoop-daemon.sh start avatarnode –zero –standby
启动过程需要很长时间: copy and load image,checkpoint,1800多台datanode节点的全量blockreport,要保证全部完成,
通过在namenode log中检索关键字checkpoint、是否持续的刷blockreport log等, 尽量多等一段时间。
3、切换 NameNode
r1:./bin/hadoop org.apache.hadoop.hdfs.AvatarShell -zero -faileoverprepare
r1:./bin/hadoop org.apache.hadoop.hdfs.AvatarShell -one -shutdownAvatar
r1:./bin/hadoop org.apache.hadoop.hdfs.AvatarShell -zero -setAvatar primary
观察客户端是否正常
4、重启 r4 节点
调整本次需要修改的配置项目;
确保没有其他问题之后,r4 节点起 Standby
启动之前,检查本地磁盘和 NFS 目录空间是否充足,内存是否足够
~/software/hadoop/bin/hadoop-daemon.sh start avatarnode –one –standby























 8442
8442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









