







目录
一、前言
1.1 两种偏好
偏好、选择理论可以阅读:选择理论1——解构理性:偏好,选择,效用
本处只简单介绍两种偏好,分别是字典序偏好(Lexicographic Preference)和偏序偏好(Posetal Preference)。
1.1.1 Lexicographic Preference(字典序偏好)
这种偏好结构的核心思想是“优先级排序”,即个体在做选择时,首先关注最重要的标准(或特征),如果有多个选项在这个标准上相同,再比较第二个标准,以此类推。举个例子:假设你在选择一台手机,标准为:价格、性能、外观。如果你的偏好是字典顺序的,那么你首先会选择价格最便宜的手机。如果价格相同,再比较性能,性能最好的排在前面。如果价格和性能都相同,再看外观,外观最吸引人的排在前面。这种偏好结构就像字典中按字母顺序排序一样,首先比较第一位,如果相同再比较第二位,以此类推。
1.1.2 Posetal Preference(偏序偏好)
偏序偏好是一种更为宽松的偏好结构,它允许在某些情况下不做严格的比较,而是通过一个偏序关系来表示选择之间的相对优劣。简单来说,偏序偏好是某种类型的“不完全偏好”,也就是说,有些选项之间没有明确的优先级关系。举个例子:假设你有三个选项:A,B 和 C。你的偏好结构是偏序的,这意味着你可能觉得 A 比 B 和 C 都好,但你对 B 和 C 的偏好没有明确的顺序关系。在这种情况下,你不能简单地说 B 比 C 好,或者 C 比 B 好,你只知道 A 最好,B 和 C 没有明确的优先级排序。在偏序偏好中,可能存在某些选项被认为是“不可比”的。也就是说,两个选项之间可能没有明确的优劣之分,这种关系通常通过偏序集来表示。
1.2 Potential Games
每个智能体有不同的奖励函数,但是他们共有的利益可以用一个共享的势函数
ϕ
\phi
ϕ 来描述,势函数定义为:
ϕ
:
S
×
A
→
R
\phi: \mathbb{S}\times \mathbb{A} \to \mathbb{R}
ϕ:S×A→R 满足
∀
(
a
i
,
a
−
i
)
,
(
b
i
,
a
−
i
)
∈
A
,
∀
i
∈
{
1
,
⋯
,
N
}
,
∀
s
∈
S
\forall(a^i, a^{-i}), (b^i, a^{-i})\in \mathbb{A}, \forall i\in \{1, \cdots, N\}, \forall s\in \mathbb{S}
∀(ai,a−i),(bi,a−i)∈A,∀i∈{1,⋯,N},∀s∈S,有如下等式成立
R
i
(
s
,
(
a
i
,
a
−
i
)
)
−
R
i
(
s
,
(
b
i
,
a
−
i
)
)
=
ϕ
(
s
,
(
a
i
,
a
−
i
)
)
−
ϕ
(
s
,
(
b
i
,
a
−
i
)
)
R^i (s, (a^i, a^{-i})) - R^i (s, (b^i, a^{-i})) = \phi (s, (a^i, a^{-i})) - \phi (s, (b^i, a^{-i}))
Ri(s,(ai,a−i))−Ri(s,(bi,a−i))=ϕ(s,(ai,a−i))−ϕ(s,(bi,a−i))
这种类型的博弈一定存在纯策略纳什均衡,此外,如果选择奖励函数作为势函数,势博弈退化为团队博弈。
二、主要贡献
- 区分竞速与城市日常行车,将城市行车博弈(Urban Driving Games,UDG)建模为一般和博弈(General-Sum Games)。
- 令智能体使用字典序偏好描述结果,在竞争性路径规划问题中引入了最小违规(minimum violation)概念
- 证明了UDG可以为迭代最优响应(Iterative Best Response)提供一些收敛性保证,这些结论可以应用在字典序偏好和标准的标量形式中。
- 给出了UDG中社会纳什均衡的存在性与计算方法。
三、摘要
论文将城市行车博弈(Urban Driving Games,简称UDGs)描述为一类特定的微分博弈,用于模拟城市驾驶任务中的互动。驾驶者拥有“共同”利益,例如避免相互碰撞,但同时也自利于遵守交通规则和实现个人目标。在其物理动态的约束下,智能体的偏好通过一个字典序偏好表达,该关系将避免碰撞这一共同目标作为首要优先事项。在假设下,论文证明了共同UDGs具有字典序势博弈的结构,社会效益纳什均衡可以通过解决一个单一的(字典序的)最优控制问题来找到,并且迭代的最优响应方案具有理想的收敛保证。
四、主要内容
4.1 引言
传统的自动驾驶遵循预测——规划的流程,使得智能体成为“被动”的道路使用者,一个较好的决策过程应当考虑其他智能体对本体的规划结果的反应,从而达到社会效益的最大化。
在赛车场景中,每个智能体的目标是战胜对手,因此该问题是一个零和博弈,然而在日常的城市交通中,每个车辆的目标并非互相对立,而是表现为不同优先级的目标函数相互交错的形式。相关工作已包括高速公路并线、十字路口、与行人的交互等,这些场景抽象成数学模型就是求解一个博弈问题。
求解博弈问题通常意味着寻找纳什均衡(Nash Equilibria),但是由于动力学、交互的复杂性,NE难以计算。为此,相关的工作利用不同的假设构造求解器,以找到广义纳什均衡问题(Generalized Nash Equilibrium Problem, GNEP)的局部均衡,例如求解重复二次博弈、增广拉格朗日方法、梯度投影、算子分裂法等等。
城市行车所具有的共享目标(避免碰撞等)以及个人目标(保持车速、保持车道)使得城市行车相较于一般的博弈问题有一些更好的性质,部分文献中已经利用这些条件,结合动态和收益的额外假设,以获得更容易证明NE存在性的场景,并求解NE,例如对最优响应集的凸性假设、控制参数化的动力学、固定路径且车辆只控制加速度的情况等。
本文相较于以往的工作考虑了两个实际的限制:(1)城市场景中,智能体通常有多个相互冲突的目标函数,导致GNEP的可行集是空的;(2)求解器没有明确考虑NE选择问题。
4.2 行车博弈建模
在行车博弈中,存在如下几个特质
- 每个智能体只控制自己的车,各个智能体的动力学相互解耦;
- 每个智能体共享相同的物理空间,若智能体相互碰撞则博弈结束;
- 字典序偏好:智能体首先考虑避免碰撞,其次才考虑最小化个人代价函数。
记包含 n n n 个玩家的玩家集合为 A \cal A A,状态向量 x ∈ X \bold x \in X x∈X 满足具有初始时刻边界条件 x ( 0 ) \bold x(0) x(0) 的微分方程 x ˙ = f ( x ( t ) , u 1 ( t ) , ⋯ , u n ( t ) , t ) \dot{\bold x} = \bold f(\bold x(t), \bold u_1(t), \cdots, \bold u_n (t), t) x˙=f(x(t),u1(t),⋯,un(t),t)。每个智能体的控制输入为 u i ∈ U i \bold u_i \in U_i ui∈Ui。每个智能体的决策空间 Γ i \Gamma_i Γi 中的每个元素表示从状态、时间到控制输入的映射 γ i : X × [ 0 , T ] → U i \gamma_i: X\times [0, T] \to U_i γi:X×[0,T]→Ui,因此控制输入可以表示为函数 u i = γ i ( x ( t ) , t ) \bold u_i = \gamma_i(\bold x(t) , t) ui=γi(x(t),t)。基于此,我们可以区分反馈策略 ( x ( t ) , t ) ↦ u ( t ) (\bold x(t), t) \mapsto \bold u(t) (x(t),t)↦u(t) 和开环策略 x ( 0 ) ↦ u i T \bold x (0) \mapsto \bold u_i^T x(0)↦uiT。
基于上述定义,论文引入了适定性假设以保证微分博弈的适定性:
假设1:向量场 f \bold f f 对于 t ∈ [ 0 , T ] t\in[0,T] t∈[0,T] 和每个状态 x \bold x x 是连续的,对 x \bold x x, u i , ∀ i ∈ A \bold u_i, \forall i \in \cal A ui,∀i∈A 是一致Lipschitz连续的。策略 γ i ∈ Γ i ( i ∈ A ) \gamma_i\in \Gamma_i (i \in \cal A) γi∈Γi(i∈A) 对于 t ∈ [ 0 , T ] t\in[0,T] t∈[0,T] 和每个状态 x \bold x x 是连续的,并且对 x \bold x x 是一致Lipschitz连续的。
进一步的,论文给出了行车博弈的定义
定义1(行车博弈):行车博弈是一种确定性微分博弈,具有如下的性质:
- 每个智能体的个人状态 x i ( t ) ∈ X i \bold x_i(t) \in X_i xi(t)∈Xi,其动力学独立于其他智能体,例如, x ˙ i ( t ) = f i ( x i ( t ) , u i ( t ) , t ) \dot{\bold x}_i(t) = f_i(\bold x_i(t), \bold u_i(t), t) x˙i(t)=fi(xi(t),ui(t),t),初始状态为 x i ( 0 ) = x i 0 \bold x_i(0) = \bold x_i^0 xi(0)=xi0。
- 每个智能体 i ∈ A i\in \cal A i∈A具有终止时间 T i T_i Ti, T i T_i Ti 定义为智能体首次抵达终点或与另一个智能体发生碰撞。令 X i goal ⊂ X i X_i^{\text{goal}} \subset X_i Xigoal⊂Xi 为智能体 i i i 的目标区域,则到达终点时间为 t i goal = min { t ∈ R + ∣ x i ( t ) ∈ X i goal } t_i^{\text{goal}} = \min \{ t\in \mathbb{R}_+ | \bold x_i(t) \in X_i^{\text{goal}} \} tigoal=min{t∈R+∣xi(t)∈Xigoal}。令 ϕ ( x ) \phi (x) ϕ(x) 为智能体在物理空间中的轨迹,则碰撞时间为 t i col = min { t ∈ R + ∣ ϕ ( x i ( t ) ) ∩ ϕ ( x j ( t ) ) ≠ ∅ } t_i^\text{col} = \min \{ t\in \mathbb{R}_+| \phi(\bold x_i(t)) \cap \phi(\bold x_j(t)) \neq \emptyset \} ticol=min{t∈R+∣ϕ(xi(t))∩ϕ(xj(t))=∅},则终止时间为 T i = min { t i goal , t i col } T_i = \min\{ t_i^\text{goal}, t_i^\text{col} \} Ti=min{tigoal,ticol}。
- 两个智能体之间的代价函数为
J
i
,
j
col
:
X
i
T
i
×
X
j
T
j
→
R
≥
0
J_{i,j}^\text{col}: X_i^{T_i}\times X_j^{T_j} \to \mathbb R_{\geq 0}
Ji,jcol:XiTi×XjTj→R≥0。智能体
i
i
i 的总碰撞代价函数为
J i col ( γ ) = ∑ j ∈ { − i } J i , j col ( x i T , x j T ) (1) \begin{aligned} J_i^\text{col}(\gamma) = \sum_{j\in \{-i\}} J_{i,j}^\text{col} (\bold x_i^T, \bold x_j^T) \end{aligned} \tag{1} Jicol(γ)=j∈{−i}∑Ji,jcol(xiT,xjT)(1) - 每个智能体
i
∈
A
i\in\cal A
i∈A的个人代价函数由两部分组成,分别是增量代价
g
i
:
X
×
U
i
×
R
≥
0
→
R
g_i:X\times U_i \times \mathbb{R}_{\geq 0} \to \mathbb{R}
gi:X×Ui×R≥0→R,以及终端代价
s
i
:
X
i
→
R
s_i: X_i \to \mathbb{R}
si:Xi→R:
J i per ( γ ) = ∫ 0 T i g i ( x ( t ) , u i ( t ) , t ) d t + s i ( x ( T i ) ) (2) J_i^\text{per}(\gamma) = \int_0^{T_i} g_i(\bold x(t), \bold u_i(t), t) \text dt + s_i(\bold x(T_i)) \tag{2} Jiper(γ)=∫0Tigi(x(t),ui(t),t)dt+si(x(Ti))(2) - 当
∀
i
∈
A
\forall i\in \cal A
∀i∈A
J i ( γ ∗ ) ⪯ J i ( γ i , γ − i ∗ ) , ∀ γ i ∈ Γ i , ∀ ( x 0 , t 0 ) ∈ X × [ 0 , T ] (3) \begin{aligned}J_i(\gamma^*)&\preceq J_i(\gamma_i,\gamma_{-i}^*),\\&\forall\gamma_i\in\Gamma_i,\forall(\mathbf{x}^0,t^0)\in X\times[0,T]\end{aligned} \tag{3} Ji(γ∗)⪯Ji(γi,γ−i∗),∀γi∈Γi,∀(x0,t0)∈X×[0,T](3)
联合策略 γ ∗ \gamma^* γ∗ 是NE。其中偏好关系 ⪯ \preceq ⪯ 是元组上的字典序
J i ( γ ) = ⟨ J i c o l , J i p e r ⟩ (4) J_i(\gamma)=\langle J_i^\mathrm{col},J_i^\mathrm{per}\rangle \tag{4} Ji(γ)=⟨Jicol,Jiper⟩(4)
定义2(城市行车博弈):城市行车博弈定义为个人代价只与个人状态和个人动作相关的行车博弈
J
i
per
(
γ
i
)
=
∫
0
T
i
g
i
(
x
i
(
t
)
,
u
i
(
t
)
,
t
)
d
t
+
s
i
(
x
i
(
T
i
)
)
(5)
J_i^\text{per} (\gamma_i) = \int_{0}^{T_i} g_i(\bold x_i(t), \bold u_i(t), t) \text d t + s_i(x_i(T_i)) \tag{5}
Jiper(γi)=∫0Tigi(xi(t),ui(t),t)dt+si(xi(Ti))(5)
此处的个人成本是标量,对于不同类型的个人成本,也可以表示为不同优先级的字典序个人目标。
为了使得碰撞成本被智能体视为共同目标,即任何一个智能体都不希望发生碰撞,论文定义了如下的公共碰撞代价
定义3(公共碰撞代价):碰撞代价可以被称为公共的当且仅当
∀
i
∈
A
\forall i\in \cal A
∀i∈A 并且对于每个
γ
i
,
γ
i
′
∈
Γ
i
\gamma_i, \gamma_i' \in \Gamma_i
γi,γi′∈Γi,
γ
−
i
∈
Γ
−
i
\gamma_{-i}\in \Gamma_{-i}
γ−i∈Γ−i 有
J
i
c
o
l
(
γ
′
)
−
J
i
c
o
l
(
γ
)
<
0
⇒
∑
j
∈
{
−
i
}
[
J
j
,
i
c
o
l
(
γ
′
)
−
J
j
,
i
c
o
l
(
γ
)
]
≤
0
(6)
J_i^{\mathrm{col}}(\gamma^{\prime})-J_i^{\mathrm{col}}(\gamma)<0\Rightarrow\sum_{j\in\{-i\}}\left[J_{j,i}^{\mathrm{col}}(\gamma^{\prime})-J_{j,i}^{\mathrm{col}}(\gamma)\right]\leq0 \tag{6}
Jicol(γ′)−Jicol(γ)<0⇒j∈{−i}∑[Jj,icol(γ′)−Jj,icol(γ)]≤0(6)
上式表明,如果智能体
i
i
i 单方面改变策略导致碰撞代价提高,则与
i
i
i 交互的其他智能体的智能体的总碰撞成本不会提高。
4.3 CUDG的势博弈结构
静态势博弈具有纯策略纳什均衡,其学习过程通常有收敛保证,并且通常是非合作NE。论文在这一部分证明了CUDG具有势博弈结构。
全序集:指在一个集合 X X X 上定义了一个全序关系(Total Order)的集合。全序关系是一种特殊的偏序关系,具有以下性质:
- 自反性:对所有 a ∈ X a \in X a∈X,有 a ⪯ a a\preceq a a⪯a
- 反对称性:若 a ⪯ b a\preceq b a⪯b 且 b ⪯ a b \preceq a b⪯a,则 a = b a=b a=b
- 传递性:若 a ⪯ b a\preceq b a⪯b 且 b ⪯ c b\preceq c b⪯c,则 a ⪯ c a\preceq c a⪯c
- 比较性:对于任意 a , b ∈ X a, b\in X a,b∈X,必有 a ⪯ b a\preceq b a⪯b 或 b ⪯ a b\preceq a b⪯a。
定义4(全序集的序势函数):令
(
X
,
⪯
)
(X, \preceq)
(X,⪯) 为全序集,若对于每个智能体
i
∈
A
i\in \cal A
i∈A 和每个策略
γ
−
i
∈
Γ
−
i
\gamma_{-i} \in \Gamma_{-i}
γ−i∈Γ−i,对所有
γ
i
′
,
γ
i
∈
Γ
\gamma_i', \gamma_i \in \Gamma
γi′,γi∈Γ 有函数
P
:
×
i
Γ
i
→
X
P: \times_i \Gamma_i \to X
P:×iΓi→X 满足
J
i
(
γ
i
′
,
γ
−
i
)
≺
J
i
(
γ
i
,
γ
−
i
)
i
f
f
P
(
γ
i
′
,
γ
−
i
)
≺
P
(
γ
i
,
γ
−
i
)
(8)
J_i(\gamma_i^{\prime},\gamma_{-i})\prec J_i(\gamma_i,\gamma_{-i})\mathrm{~iff~}P(\gamma_i^{\prime},\gamma_{-i})\prec P(\gamma_i,\gamma_{-i}) \tag{8}
Ji(γi′,γ−i)≺Ji(γi,γ−i) iff P(γi′,γ−i)≺P(γi,γ−i)(8)
则称
P
P
P 是
X
X
X 上的一个序势函数。
论文最主要的理论结果就是证明了以下结论:
定理1(CUDG是社会效率势博弈):令
G
\cal G
G 是一个有公共碰撞代价的UDG(CUDG)则对于紧的策略空间和半连续有界的代价,社会成本的最小值对应
G
\cal G
G 的纯策略纳什均衡。
证明
(1)首先证明 G \cal G G 拥有偏序势函数 P P P(这一部分证明原论文有小错误)
P ( γ ) = ⟨ 1 2 ∑ i ∈ A J i c o l ( γ ) , ∑ i ∈ A J i p e r ( γ i ) ⟩ (9) P(\gamma)=\left\langle\frac{1}{2}\sum_{i\in\mathcal{A}}J_i^{\mathrm{col}}(\gamma),\sum_{i\in\mathcal{A}}J_i^{\mathrm{per}}(\gamma_i)\right\rangle \tag{9} P(γ)=⟨21i∈A∑Jicol(γ),i∈A∑Jiper(γi)⟩(9)
对于智能体 i i i 的单方面策略偏离( γ i → γ i ′ \gamma_i\to\gamma_i' γi→γi′, γ → γ ′ \gamma\to\gamma' γ→γ′,其中 γ ′ = [ γ 1 , ⋯ , γ i ′ , ⋯ , γ n ] \gamma' = [\gamma_1, \cdots, \gamma_i', \cdots, \gamma_n] γ′=[γ1,⋯,γi′,⋯,γn]),式(9)的第一项展开为
1 2 ∑ i ∈ A J i c o l ( γ ) = 1 2 [ J i col ( γ ′ ) + ∑ j ∈ { − i } J j col ( γ ′ ) ] = 1 2 J i col ( γ ′ ) + 1 2 ∑ j ∈ { − i } ∑ k ∈ { − j } J j , k col ( γ j , γ k ) = 1 2 J i col ( γ ′ ) + 1 2 ∑ j ∈ { − i } [ ∑ k ∈ { − j } \ { i } J j , k col ( γ j , γ k ) + J j , i col ( γ j , γ i ′ ) ] = 1 2 J i col ( γ ′ ) + 1 2 ∑ j ∈ { − i } [ ∑ k ∈ { − i } \ { j } J j , k col ( γ j , γ k ) + J j , i col ( γ j , γ i ′ ) ] \begin{aligned} \frac{1}{2}\sum_{i\in\mathcal{A}}J_i^{\mathrm{col}}(\gamma) &= \frac{1}{2} [J_i^\text{col}(\gamma') + \sum_{j\in\{-i\}}J_j^\text{col}(\gamma')]\\ &= \frac{1}{2} J_i^\text{col}(\gamma') + \frac{1}{2} \sum_{j\in\{-i\}} \sum_{k\in\{-j\}} J_{j,k}^\text{col}(\gamma_j, \gamma_k)\\ &= \frac{1}{2} J_i^\text{col}(\gamma') + \frac{1}{2} \sum_{j\in\{-i\}} \left[ \sum_{k\in\{-j\}\backslash\{i\}} J_{j,k}^\text{col}(\gamma_j, \gamma_k) + J_{j,i}^\text{col}(\gamma_j, \gamma_i')\right]\\ &= \frac{1}{2} J_i^\text{col}(\gamma') + \frac{1}{2} \sum_{j\in\{-i\}} \left[ \sum_{k\in\{-i\}\backslash\{j\}} J_{j,k}^\text{col}(\gamma_j, \gamma_k) + J_{j,i}^\text{col}(\gamma_j, \gamma_i')\right] \end{aligned} 21i∈A∑Jicol(γ)=21[Jicol(γ′)+j∈{−i}∑Jjcol(γ′)]=21Jicol(γ′)+21j∈{−i}∑k∈{−j}∑Jj,kcol(γj,γk)=21Jicol(γ′)+21j∈{−i}∑ k∈{−j}\{i}∑Jj,kcol(γj,γk)+Jj,icol(γj,γi′) =21Jicol(γ′)+21j∈{−i}∑ k∈{−i}\{j}∑Jj,kcol(γj,γk)+Jj,icol(γj,γi′)
第二项展开为
∑ i ∈ A J i per ( γ i ) = J i per ( γ i ′ ) + ∑ j ∈ { − i } J j per ( γ j ) \sum_{i\in\cal A} J_i^\text{per} (\gamma_i) = J_i^\text{per}(\gamma_i') + \sum_{j\in\{-i\}} J_j^\text{per} (\gamma_j) i∈A∑Jiper(γi)=Jiper(γi′)+j∈{−i}∑Jjper(γj)
因此 P P P 改写为如下的形式,将 γ i ′ \gamma_i' γi′ 项分离出来。
P = ⟨ 1 2 J i col ( γ ′ ) + 1 2 ∑ j ∈ { − i } ∑ k ∈ { − i } \ { j } J j , k col ( γ j , γ k ) + 1 2 ∑ j ∈ { − i } J j , i col ( γ j , γ i ′ ) , J i per ( γ i ′ ) + ∑ j ∈ { − i } J j per ( γ j ) ⟩ (10) \begin{aligned} P &= \langle \frac{1}{2} J_i^\text{col}(\gamma') \\ &+ \frac{1}{2} \sum_{j\in\{-i\}} \sum_{k\in\{-i\}\backslash\{j\}}J_{j,k}^\text{col}(\gamma_j, \gamma_k) + \frac{1}{2} \sum_{j\in\{-i\}} J_{j,i}^\text{col}(\gamma_j, \gamma_i') ,\\ &J_i^\text{per}(\gamma_i') + \sum_{j\in\{-i\}} J_j^\text{per} (\gamma_j) \rangle \end{aligned} \tag{10} P=⟨21Jicol(γ′)+21j∈{−i}∑k∈{−i}\{j}∑Jj,kcol(γj,γk)+21j∈{−i}∑Jj,icol(γj,γi′),Jiper(γi′)+j∈{−i}∑Jjper(γj)⟩(10)
因此,为了验证 P ( γ i ′ , γ − i ) ≺ P ( γ ) P(\gamma_i', \gamma_{-i})\prec P(\gamma) P(γi′,γ−i)≺P(γ) 是否成立,只需要考虑取决于新策略 γ ′ \gamma' γ′ 的项即可,即
P ( γ i ′ , γ − i ) ≺ P ( γ ) ⇔ ⇔ ⟨ 1 2 J i c o l ( γ ′ ) + 1 2 ∑ j ∈ { − i } J j , i c o l ( γ ′ ) , J i p e r ( γ ′ ) ⟩ ≺ ≺ ⟨ 1 2 J i c o l ( γ ) + 1 2 ∑ j ∈ { − i } J j , i c o l ( γ ) , J i p e r ( γ i ) ⟩ . (11) \begin{aligned}P(\gamma_i^{\prime},\gamma_{-i})&\prec P(\gamma)\Leftrightarrow\\&\Leftrightarrow\left\langle\frac{1}{2}J_i^{\mathrm{col}}(\gamma^{\prime})+\frac{1}{2}\sum_{j\in\{-i\}}J_{j,i}^{\mathrm{col}}(\gamma^{\prime}),J_i^{\mathrm{per}}(\gamma^{\prime})\right\rangle\prec\\&\prec\left\langle\frac{1}{2}J_i^{\mathrm{col}}(\gamma)+\frac{1}{2}\sum_{j\in\{-i\}}J_{j,i}^{\mathrm{col}}(\gamma),J_i^{\mathrm{per}}(\gamma_i)\right\rangle.\end{aligned} \tag{11} P(γi′,γ−i)≺P(γ)⇔⇔⟨21Jicol(γ′)+21j∈{−i}∑Jj,icol(γ′),Jiper(γ′)⟩≺≺⟨21Jicol(γ)+21j∈{−i}∑Jj,icol(γ),Jiper(γi)⟩.(11)
结合上面的推导,式(11)显然成立,证毕(2) P P P 的最小值是 G \cal G G 的纯策略NE
对于紧策略集以及下半连续有界的代价函数, P P P 的全局极小值存在。
令 γ ∗ ∈ argmin γ ∈ Γ P ( γ ) \gamma^* \in \text{argmin}_{\gamma\in\Gamma} P(\gamma) γ∗∈argminγ∈ΓP(γ),则由式(8) γ ∗ \gamma^* γ∗ 是 G \cal G G 的纯策略NE。
(3) P P P 的最小值能够达成最小的社会代价
社会代价的定义为
C ( γ ) = ∑ i ∈ A J i ( γ ) \mathcal{C}(\gamma) = \sum_{i\in\cal{A}} J_i(\gamma) C(γ)=i∈A∑Ji(γ)
易得,对于 γ ∗ ∈ argmin γ ∈ Γ P ( γ ) \gamma^* \in \text{argmin}_{\gamma\in\Gamma}P(\gamma) γ∗∈argminγ∈ΓP(γ) 同样有 γ ∗ ∈ argmin γ ∈ Γ C ( γ ) \gamma^*\in\text{argmin}_{\gamma\in\Gamma}\cal C (\gamma) γ∗∈argminγ∈ΓC(γ)
通常情况下,势博弈并不一定存在社会效益的纯策略纳什均衡,NE通常会导致社会效益低下。通过定理1我们可以知道,对于CUDG,NE也对应社会代价的最小值,因此仅需在纯策略集合上求解非线性优化问题即可找到社会效益NE。
4.4 迭代最优响应收敛
对于一般的博弈而言,迭代最优响应(Iterated Best Response, IBR)算法并不存在收敛性的保证,由于CUDG的势博弈结构,收敛性保证是存在的。
命题1(CUDG的IBR):令定理1的假设条件成立,则对于任意小的
ϵ
>
0
\epsilon > 0
ϵ>0,I
ε
\varepsilon
ε-BR在有限步内收敛到纳什
ε
\varepsilon
ε均衡。对于离散策略,IBR能够收敛到NE。
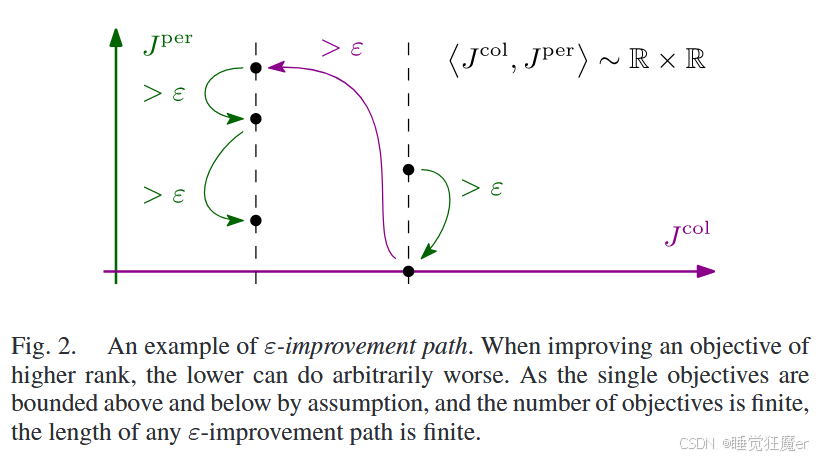
证明:
称策略序列 Π = [ γ 0 , γ 1 , ⋯ ] \Pi = [\gamma^0, \gamma^1, \cdots] Π=[γ0,γ1,⋯] 是 Γ \Gamma Γ 的一个 ε \varepsilon ε-imporvement path 若其满足
⟨ J i c o l ( γ k − 1 ) − ε , J i p e r ( γ k − 1 ) ⟩ ≻ J i ( γ k ) o r ⟨ J i c o l ( γ k − 1 ) , J i p e r ( γ k − 1 ) − ε ⟩ ≻ J i ( γ k ) , \begin{aligned}&\left\langle J_i^{\mathrm{col}}(\gamma^{k-1})-\varepsilon,J_i^{\mathrm{per}}(\gamma^{k-1})\right\rangle\succ J_i(\gamma^k)\mathrm{~or}\\&\left\langle J_i^{\mathrm{col}}(\gamma^{k-1}),J_i^{\mathrm{per}}(\gamma^{k-1})-\varepsilon\right\rangle\succ J_i(\gamma^k),\end{aligned} ⟨Jicol(γk−1)−ε,Jiper(γk−1)⟩≻Ji(γk) or⟨Jicol(γk−1),Jiper(γk−1)−ε⟩≻Ji(γk),
对于 ε > 0 \varepsilon > 0 ε>0 和所有的 k ≥ 1 k\geq 1 k≥1,称策略 γ ε \gamma^\varepsilon γε 是一个总序 ε \varepsilon ε-NE,当且仅当存在 ε > 0 \varepsilon>0 ε>0 且 ∀ i ∈ A \forall i\in \cal A ∀i∈A 有
{ J i ( γ ε ) ≺ ⟨ J i col ( γ i , γ − i ε ) + ε , J i per ( γ i , γ − i ε ) ⟩ J i ( γ ε ) ≺ ⟨ J i col ( γ i , γ − i ε ) , J i per ( γ i , γ − i ε ) + ε ⟩ , ∀ γ i ∈ Γ i (13) \begin{aligned} \begin{cases} J_i(\gamma^\varepsilon) \prec \langle J_i^\text{col}(\gamma_i, \gamma_{-i}^\varepsilon) + \varepsilon, J_i^\text{per} (\gamma_i, \gamma_{-i}^\varepsilon) \rangle \\ J_i(\gamma^\varepsilon) \prec \langle J_i^\text{col}(\gamma_i, \gamma_{-i}^\varepsilon), J_i^\text{per} (\gamma_i, \gamma_{-i}^\varepsilon) + \varepsilon \rangle, \forall \gamma_i \in \Gamma_i \end{cases} \end{aligned} \tag{13} {Ji(γε)≺⟨Jicol(γi,γ−iε)+ε,Jiper(γi,γ−iε)⟩Ji(γε)≺⟨Jicol(γi,γ−iε),Jiper(γi,γ−iε)+ε⟩,∀γi∈Γi(13)
给定上述定义,后续证明和有限博弈相同。如果 γ ε \gamma^\varepsilon γε 不能找到一个 ε \varepsilon ε 更优的偏离,则满足式(12)并且是一个 ε \varepsilon ε-NE。
若能够找到 ε \varepsilon ε 更优的偏离,则玩家每一次的更新都会使得势函数 P P P 有 ε / 2 \varepsilon/2 ε/2 的提升。由于 P P P 是有界的,最终存在一个有限的最大迭代步数使得策略收敛到 ε \varepsilon ε-NE。
将智能体
i
i
i 对于策略
γ
\gamma
γ 的最优响应记为
R
i
(
γ
)
⊆
Γ
i
\cal R_i(\gamma) \subseteq \Gamma_i
Ri(γ)⊆Γi,每个智能体可以通过如下的约束优化问题求解其最优响应
R
i
(
γ
−
i
)
=
argmin
γ
i
∈
Γ
i
⟨
J
i
col
(
γ
i
,
γ
−
i
)
,
J
i
per
(
γ
i
)
⟩
subject to
x
˙
i
(
t
)
=
f
i
(
x
i
(
t
)
,
u
i
(
t
)
)
x
i
(
0
)
=
x
i
0
(13)
\begin{aligned} \mathcal R_i (\gamma_{-i}) = &\text{argmin}_{\gamma_i \in \Gamma_i} \langle J_i^\text{col} (\gamma_i, \gamma_{-i}) , J_i^\text{per} (\gamma_i) \rangle \\ &\text{subject to } \dot{\bold x}_i(t) = f_i(\bold x_i(t), \bold u_i(t)) \\ &\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\bold x_i(0) = \bold x_i^0 \end{aligned}\tag{13}
Ri(γ−i)=argminγi∈Γi⟨Jicol(γi,γ−i),Jiper(γi)⟩subject to x˙i(t)=fi(xi(t),ui(t))xi(0)=xi0(13)
给定初始策略
γ
0
∈
Γ
\gamma^0 \in \Gamma
γ0∈Γ 和玩家更新的顺序(可以任意选择)以及终止容差
ε
>
0
\varepsilon > 0
ε>0,存在有限的
k
ˉ
\bar k
kˉ 使得
γ
i
k
ˉ
∈
R
i
(
γ
−
i
k
ˉ
)
,
∀
i
∈
A
\gamma_i^{\bar k} \in \mathcal{R}_i(\gamma_{-i}^{\bar k}), \forall i \in \cal A
γikˉ∈Ri(γ−ikˉ),∀i∈A,即
γ
k
ˉ
\gamma^{\bar k}
γkˉ 是
ε
\varepsilon
ε-NE。IBR更新算法如下所示

算法1求解的
ε
\varepsilon
ε-NE没有求解质量的保证,即
- 可能不是最优的NE,即可能存在其他NE使得所有智能体的收益更大
- 初值敏感,不同 γ 0 \gamma^0 γ0 可能会收敛到不同的 γ k ˉ \gamma^{\bar k} γkˉ
- γ k ˉ \gamma^{\bar k} γkˉ 与IBR中玩家更新的顺序相关
开环和反馈的情形都可以应用上述算法,但是需要注意的是闭环策略需要将每个可能的状态作为初始状态进行求解,而开环策略只需要给定初始状态即可使用一般的优化工具求解。
4.5 仿真
开环形式的CUDG在求解上更加简单,论文将这一类CUDG问题称为轨迹博弈(Trajectory Game)。并且在一个包含三辆车辆的四向交叉路口进行了验证。
4.5.1 仿真场景
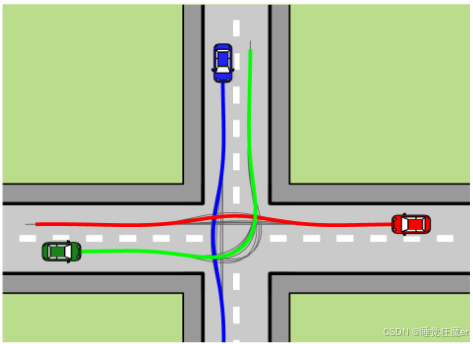
论文使用自行车模型,车辆运动控制可以看笔者的专栏 自动驾驶控制与规划,其中车辆的状态为
x
i
=
[
x
i
,
y
i
,
ϕ
i
,
v
i
,
δ
i
,
a
x
,
i
]
\bold x_i = [x_i, y_i, \phi_i, v_i, \delta_i, a_{x,i}]
xi=[xi,yi,ϕi,vi,δi,ax,i],分别是车辆质心二维位置
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi)(m),车辆偏航角
ϕ
i
\phi_i
ϕi(rad),标量速度
v
i
v_i
vi(m/s),转向角
δ
i
\delta_i
δi(rad)以及纵向加速度
a
x
,
i
a_{x,i}
ax,i(m/s^2)。控制输入是
u
i
=
[
δ
˙
i
,
a
˙
x
,
i
]
\bold u_i = [\dot \delta_i, \dot a_{x,i}]
ui=[δ˙i,a˙x,i],分别是有界的转向角速度和加加速度。此外,物理约束还包括最大最小的加速度以及转向角。运动学方程如下:
x
˙
i
=
v
i
⋅
cos
(
ϕ
i
)
y
˙
i
=
v
i
⋅
sin
(
ϕ
i
)
ϕ
˙
i
=
v
i
/
l
⋅
tan
(
δ
i
)
\begin{aligned} \dot x_i &= v_i \cdot \cos(\phi_i)\\ \dot y_i &= v_i \cdot \sin(\phi_i)\\ \dot \phi_i &= v_i / l \cdot \tan(\delta_i) \end{aligned}
x˙iy˙iϕ˙i=vi⋅cos(ϕi)=vi⋅sin(ϕi)=vi/l⋅tan(δi)
式中
l
l
l 是轴距。
4.5.2 字典序偏好的优化问题
字典序目标函数包括三部分 ⟨ J col , J per(1) , J per(2) ⟩ \langle J^\text{col}, J^\text{per(1)}, J^\text{per(2)} \rangle ⟨Jcol,Jper(1),Jper(2)⟩。第一项对应避碰;第二项对应交通规则,即限速和车道保持;第三项对应舒适度以及期望巡航速度。
J col J^\text{col} Jcol:碰撞代价 J i , j col J_{i,j}^\text{col} Ji,jcol 使用最小安全距离以及车辆不超出路面,路面宽度为 7m,最小安全距离 d ‾ \underline d d 为 4m。
J per(1) J^\text{per(1)} Jper(1):限速和车道用软约束的加权和实现,车道定义为一条二次可微的样条曲线 λ ( η ) : [ 0 , l λ ] → R 2 \lambda(\eta): [0, l_\lambda]\to \mathbb{R}^2 λ(η):[0,lλ]→R2,其中 η ∈ [ 0 , l λ ] \eta\in[0, l_\lambda] η∈[0,lλ] 表示车道上离车辆当前位置最近的位置的索引,最大车速为 9m/s。
J per(2) J^\text{per(2)} Jper(2):表示为如下几个目标的加权和
- 车道保持,对横向和纵向偏离施加二次惩罚
- 保持期望速度,期望速度为8.3 m/s,使用二次项非对称惩罚(较低的速度惩罚较小)
- 舒适度,对转向速度的变化 以及 加加速度 施加二次惩罚
对于字典序目标的优化问题,论文提出了两种求解方法:
方法1:在每个字典序上求解一次优化问题,第
k
k
k个优化问题以不恶化前一次优化的代价为约束,最小化第
k
k
k个目标,在这种方法下式(13)重写为:
(
J
i
c
o
l
)
∗
=
min
u
i
∈
U
i
,
x
i
(
T
i
)
∈
X
i
g
o
a
l
J
i
c
o
l
(
x
i
,
x
−
i
)
s. t.
x
˙
i
=
f
i
(
x
i
,
u
i
)
,
x
i
0
(14)
\begin{aligned}(J_{i}^{\mathrm{col}})^{*}&=\min_{\mathbf{u}_{i}\in U_{i}, \mathbf{x}_{i}(T_{i})\in X_{i}^{\mathrm{goal}}}J_{i}^{\mathrm{col}}(\mathbf{x}_{i},\mathbf{x}_{-i}) \\ &\text{s. t. }\dot{\mathbf{x}}_{i}=f_{i}(\mathbf{x}_{i},\mathbf{u}_{i}),\mathbf{x}_{i}^{0} \end{aligned} \tag{14}
(Jicol)∗=ui∈Ui,xi(Ti)∈XigoalminJicol(xi,x−i)s. t. x˙i=fi(xi,ui),xi0(14)
以及
(
J
i
p
e
r
)
∗
=
min
u
i
∈
U
i
,
x
i
(
T
i
)
∈
X
i
g
o
a
l
J
i
p
e
r
(
x
i
,
u
i
)
s. t.
J
i
col
(
x
i
,
x
−
i
)
≤
(
J
i
col
)
∗
x
˙
i
=
f
i
(
x
i
,
u
i
)
,
x
i
0
(15)
\begin{aligned}(J_{i}^{\mathrm{per}})^{*}&=\min_{\mathbf{u}_{i}\in U_{i}, \mathbf{x}_{i}(T_{i})\in X_{i}^{\mathrm{goal}}}J_{i}^{\mathrm{per}}(\mathbf{x}_{i},\bold u_i) \\ &\text{s. t. } \; J_i^\text{col}(\bold x_i, \bold x_{-i}) \leq (J_i^\text{col})^* \\ &\;\;\;\;\;\;\;\; \dot{\mathbf{x}}_{i}=f_{i}(\mathbf{x}_{i},\mathbf{u}_{i}),\mathbf{x}_{i}^{0} \end{aligned} \tag{15}
(Jiper)∗=ui∈Ui,xi(Ti)∈XigoalminJiper(xi,ui)s. t. Jicol(xi,x−i)≤(Jicol)∗x˙i=fi(xi,ui),xi0(15)
方法2:给定碰撞代价的下界,例如设定最小安全距离5m,3m,2m,然后并行地求解式(15)。每个结果可以为字典序目标优化问题给出一个解并且保证了特定的安全水平,相当于方法1将第一层离散近似。
4.5.3 IBR和势函数求解NE的对比
IBR求解过程中不同玩家依次求解字典序偏好优化问题,依次更新自身策略;而通过势函数求解通过优化不同玩家目标函数的和并且考虑所有玩家的物理约束。
4.5.4 结果分析
IBR和势函数的解如图3、4所示,图5展示了个人成本的变化。在这些结果中,最终的碰撞代价都可以忽略不计,说明没有发生明显违反最小安全距离的情况。
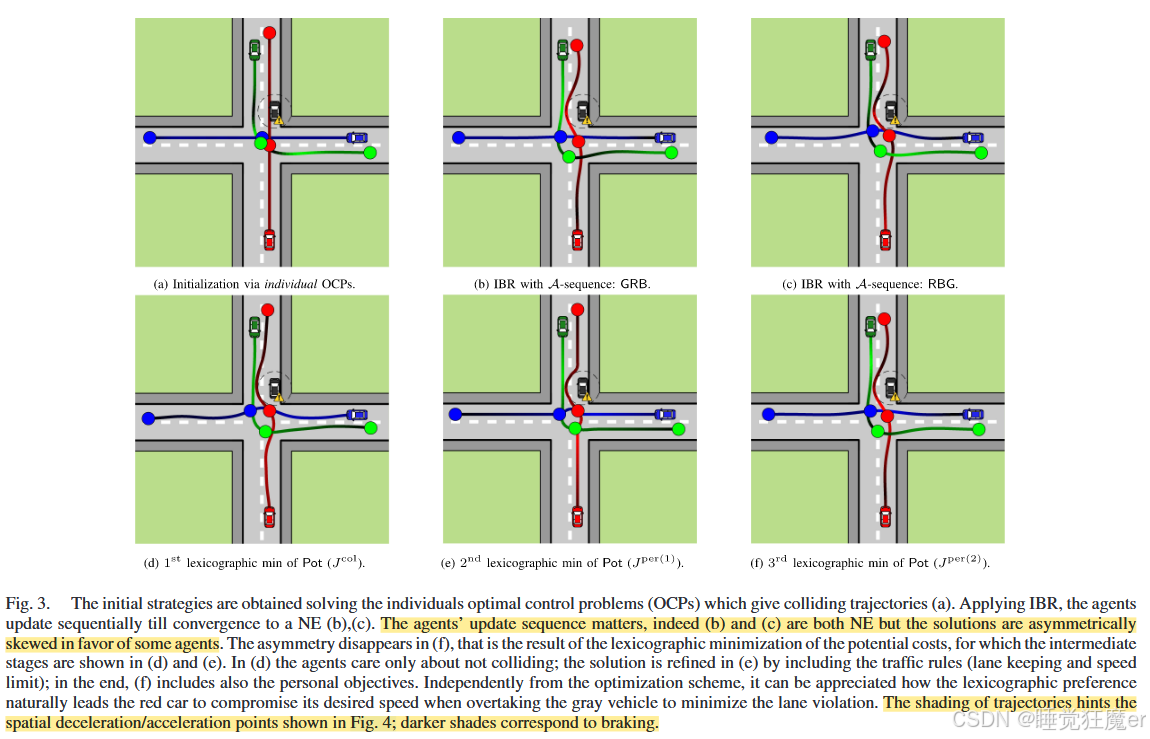
在图3、4的(b),(f)中,红车由于被黑色抛锚车辆阻挡,驶离车道并且牺牲了其巡航速度。但是在图3、4©中红色车辆出现显著转向和侧向偏差,反映在图5(a)中较高的
J
per(1)
J^\text{per(1)}
Jper(1) 上。
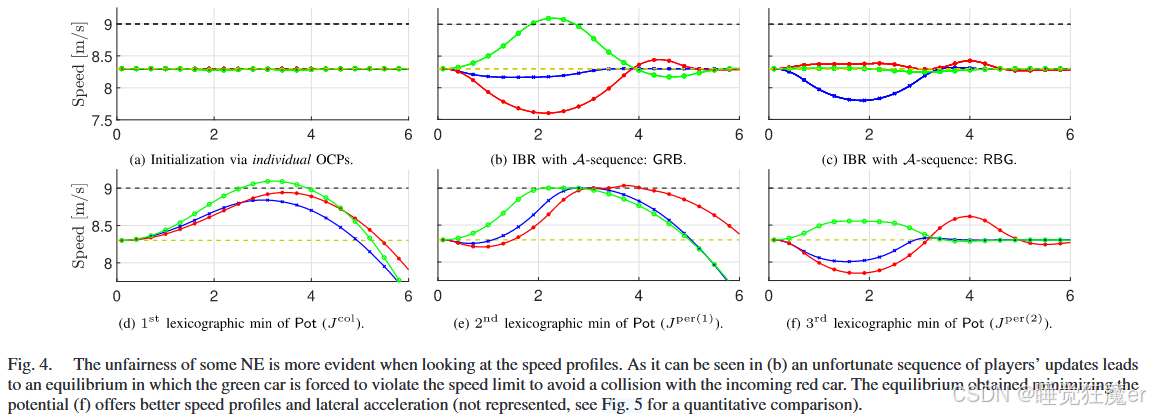
IBR和势函数大部分的结果都是类似的,所获得的NE都是可容许的,即没有一个均衡严格支配另一个均衡。但是IBR有时会产生明显偏向某个智能体的均衡,例如在图3( b ),( c )中绿车被迫违反速度限制以避免红车靠近。
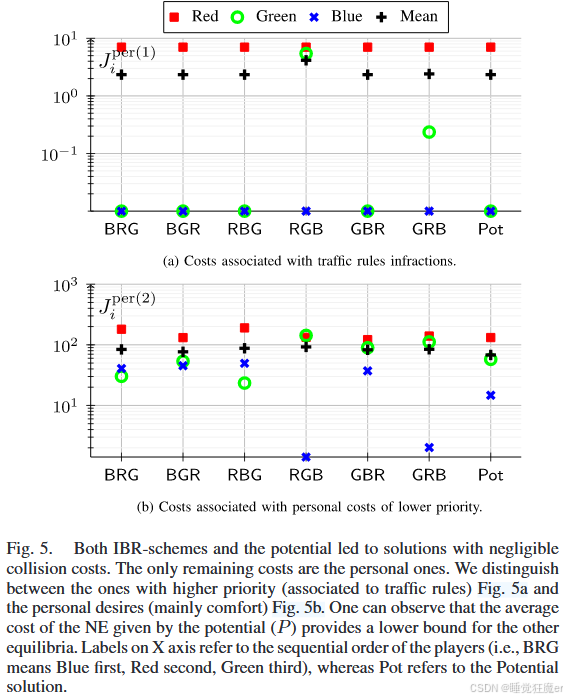
由于问题的非凸性,该问题难以获得全局最优性保证,但是与定理1一致,通过优化势函数获得的NE比其他方法的社会效益都更好,论文推测可能是由于联合优化中对称的成本分摊了一部分不可减小的代价函数。这一点在IBR中难以保证,因为每个智能体优化过程中不会权衡自身的低优先级目标(例如舒适度)与对方的高优先级目标(交通规则)。
五、可能的扩展方向
- 智能体的目标脱离全序集(在作者的后面一篇论文中就讨论了更广泛的偏序关系)
- 将优化方法扩展到反馈策略
- 利用问题固有的对称性


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









