







论文:DBCopilot: Scaling Natural Language Querying to Massive Databases
⭐⭐⭐⭐
Code: DBCopilot | GitHub
一、论文速读
论文认为目前的 Text2SQL 研究大多只关注具有少量 table 的单个数据库上的查询,但在面对大规模数据库和数据仓库的查询时时却力显不足。本文提出的 DBCopilot 能够在大规模数据库上查询模式不可知的 NL question。
论文指出,实现这个的核心是:从能够构建各种 NL question 到海量数据库模型元素的 semantic mapping,从而能够自动识别目标数据库并过滤出最少的相关 tables。但目前的基于 LLM 的方法有两个主要挑战:
- 由于 token 限制,无法将所有 schema 都输入给 LLM
- LLM 仍然难以有效利用长上下文中的信息
而在解决可扩展性的问题时,主要有基于 retrieval 的方法和基于 fine-tune 的方法,但是,
- 基于 retrieval 的方法往往是将 doc 视为检索对象,忽略了 DB 和 DB table 之间的关系;
- fine-tune LLM 来为其注入 schema 的相关知识是资源密集型的方式,且有时候 LLM 是无法微调的
DBCopilot 的做法如下图所示:
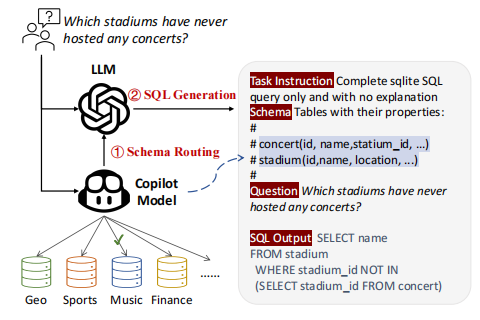
主要分成两步:
- Schema Routing:输入 user question,使用 DSI 技术找到所需要用的 DB 和 DB tables,也就是 DB schema。
- SQL Generation:输入 user question、DB schema,通过 prompt LLM 生成 SQL query。
二、问题定义
2.1 Schema-Agnostic NL2SQL
Schema-Agnostic NL2SQL 指的是:只给定 user question 而不给定预期的 SQL query schema(DB 和 DB tables),来生成一个可以在一个数据库集合中的某个 DB 上执行的 SQL。
像之前 WikiSQL 数据集上,都是指定 question 在哪个 DB 上的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4168
4168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









