



文章目录
作者团队

摘要
网络流量包括在网络中传输的数据,例如网页浏览和文件传输,其组织形式为数据包(数据的小单位)和数据流(两个端点之间交换的数据包序列)。对加密流量进行分类对于检测安全威胁和优化网络管理至关重要。近年来的研究进展表明,基础模型在这一任务中具有显著优势,尤其是在利用大量未标记数据以及对未见过的数据表现出强大泛化能力方面。
然而,现有方法主要关注令牌级关系,未能捕捉更广泛的流量模式。加密流量中的令牌通常定义为十六进制数字序列,其语义信息有限,无法充分反映流量模式。这些流量模式对于流量分类至关重要,主要来源于数据流内部数据包之间的交互,而非单个数据包的内部结构。
为解决这一局限性,我们提出了一种多实例加密流量Transformer模型(Multi-Instance Encrypted Traffic Transformer, MIETT)。该模型采用多实例方法,将每个数据包视为一个独立实例,而整个数据流则作为一个更大的“袋”(bag)来表示。通过引入双层注意力机制(Two-Level Attention, TLA),MIETT能够更有效地捕捉令牌级和数据包级的关系,从而提升模型学习复杂数据包动态和流量模式的能力。
为进一步增强模型对时间和流量特定动态的理解,我们设计了两种新颖的预训练任务:数据包相对位置预测(Packet Relative Position Prediction, PRPP)和流量对比学习(Flow Contrastive Learning, FCL)。经过微调后,MIETT在五个数据集上均达到了最先进的(State-of-the-Art, SOTA)性能,充分验证了其在加密流量分类和理解复杂网络行为方面的有效性。
前言
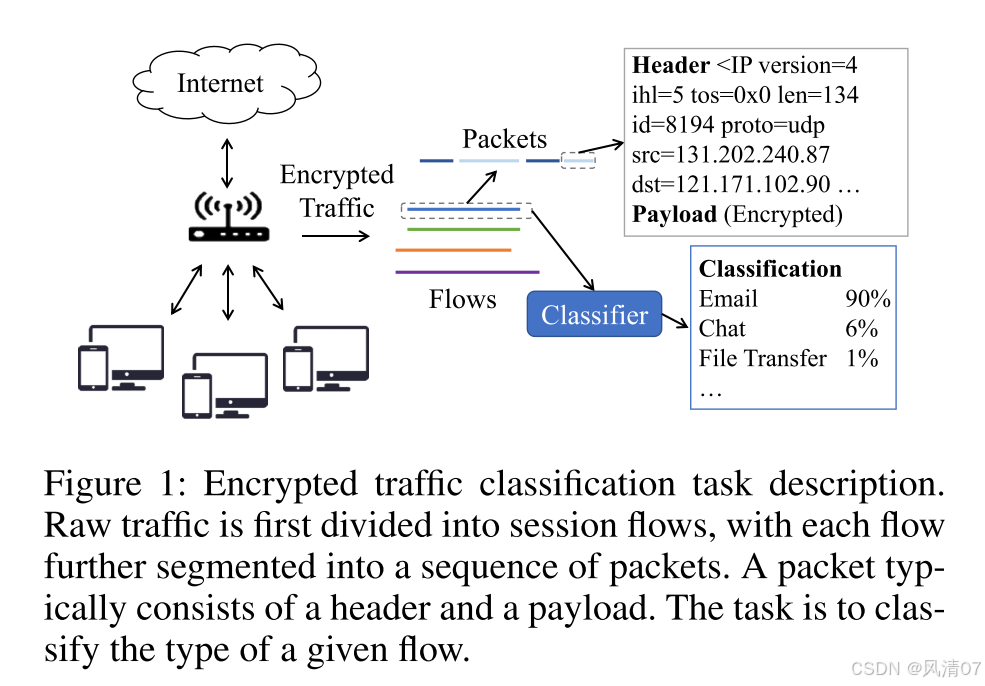
网络流量指的是设备之间通过网络传输的数据流,通常被组织为数据包(网络中传输的小单位)和数据流(两个点之间交换的数据包序列)。每个数据包由两部分组成:头部和有效载荷。头部包含路由信息、源地址和目的地址、数据包长度等关键信息,而有效载荷则携带实际传输的数据,这些数据通常为了安全目的而被加密。
流量分类是识别和分类网络流量的过程,对于网络管理和网络安全至关重要。它使网络管理员能够确保服务质量(Quality of Service, QoS),优化带宽,并检测恶意活动,从而维护网络的安全性和效率。图1提供了加密流量分类任务的概述。
然而,加密的普及使得传统的基于端口和统计的分类方法效果显著下降。深度学习(Deep Learning, DL)的出现带来了显著的改进,基于有效载荷的方法利用卷积神经网络(CNNs)等模型自动从原始数据中提取特征。尽管这些方法取得了成功,但它们严重依赖于大量标记数据,而这些数据的获取往往较为困难。
近年来,基础模型(Foundation Models)作为一种强大的替代方案崭露头角。这些模型在大量未标记数据上进行预训练,并针对特定任务进行微调。PERT(He, Yang, and Chen, 2020)采用基于BERT的模型,通过掩码语言建模(Masked Language Modeling, MLM)任务预训练一个数据包级编码器,但该方法主要关注单个数据包内的令牌级关系,忽略了数据包之间的更广泛上下文。ET-BERT(Lin et al., 2022)通过引入同源突发预测(Same-origin BURST Prediction, SBP)任务来解决这一局限性,该任务用于确定一个数据包是否在同一数据流中跟随另一个数据包。尽管如此,这种方法仍然未能完全捕捉流量级交互的复杂性和多个数据包段之间的更广泛上下文。
YaTC(Zhao et al., 2023)采用了一种不同的方法,通过将流量数据分块并使用掩码自编码器(Masked Auto-Encoder, MAE)预训练一个流量内的令牌级编码器。然而,由于加密流量令牌的语义信息有限,仅关注令牌依赖关系的效果较差。这种方法往往忽略了流量中整个数据包之间的更广泛模式和关系。实际上,学习能够捕捉这些数据包模式的表示更为稳健。
鉴于每个数据包可以被视为携带独特信息的独立实例,有效建模数据包之间的关系对于实现全面的流量表示至关重要。为解决这一问题,我们提出了一种多实例加密流量Transformer模型(Multi-Instance Encrypted Traffic Transformer, MIETT),该模型引入双层注意力机制(Two-Level Attention, TLA),能够有效捕捉流量中令牌级和数据包级的关系。
为进一步增强模型对时间和流量特定动态的理解,我们设计了两种新颖的预训练任务:数据包相对位置预测(Packet Relative Position Prediction, PRPP)和流量对比学习(Flow Contrastive Learning, FCL)。PRPP任务旨在通过预测数据包在流量中的相对位置,帮助模型理解数据包的序列关系,从而实现对流量结构的更准确表示。同时,FCL任务通过学习强调流量内相似性和流量间差异性的稳健表示,专注于区分同一流量中的数据包和不同流量中的数据包。
基于预训练阶段学习到的稳健表示,模型随后在特定分类任务上进行完全微调。在此阶段,数据包编码器和流量编码器被联合优化,以适应目标任务。在五个数据集上的实验表明,MIETT在性能上始终优于现有方法。
综上所述,本文在加密流量分类领域做出了以下关键贡献:
- 提出了一种新颖的多实例加密流量Transformer架构(MIETT),引入双层注意力机制(TLA),有效捕捉流量中令牌级和数据包级的关系。
- 设计了两种创新的预训练任务:数据包相对位置预测(PRPP)和流量对比学习(FCL)。PRPP任务增强了模型对流量中数据包序列顺序的理解,而FCL任务提高了模型区分同一流量和不同流量数据包的能力。
- 提供了对所提出的MIETT模型的广泛实证验证,结果表明我们的方法在准确率和F1分数上优于现有方法。
相关工作
加密流量分类是网络安全性研究的重要领域。随着加密技术的普及,传统的基于数据包有效载荷的流量分析方法逐渐失效。目前,研究者们致力于开发无需直接访问流量内容即可对加密流量进行分类的方法。这些方法可以分为三类:基于端口的方法、基于统计的方法和基于有效载荷的方法。
基于端口的方法
基于端口的流量分类是最早的方法之一,其通过将TCP/UDP头部的端口号与IANA定义的知名端口号进行关联来实现分类。尽管该方法速度快且简单,但由于端口混淆、动态端口分配、网络地址转换(NAT)等技术的广泛使用,其分类准确性已显著下降(Moore and Papagiannaki, 2005)。
基于统计的方法
基于统计的加密流量分类方法利用与有效载荷无关的特征(如数据包大小、时间间隔和流量持续时间)进行分析和分类。例如,Wang等人通过计算数据包有效载荷的熵值,使用支持向量机(SVM)算法选择特征,对八类流量进行分类(Wang et al., 2011)。同样,Korczynski和Duda聚焦于数据包大小、时间间隔和通信模式,用于分类加密隧道中的流量(Korczyński and Duda, 2012)。然而,这些方法依赖于人工设计的特征,随着加密协议的演进、流量模式的变化以及流量混淆技术的使用,已逐渐过时。
基于有效载荷的深度学习方法
基于有效载荷的方法通常利用深度学习技术分析原始数据包数据,无需依赖人工设计的特征。这些方法通过自动提取判别特征,显著推动了加密流量分类的发展。例如,Deep Packet(Lotfollahi et al., 2020)采用堆叠自编码器和卷积神经网络(CNN)框架进行网络流量分类。TSCRNN(Lin, Xu, and Gao, 2021)利用CNN提取抽象空间特征,并引入堆叠双向长短期记忆网络(LSTM)学习时间特征。BiLSTM ATTN(Yao et al., 2019)结合注意力机制与LSTM网络,以增强加密流量分类性能。尽管这些方法能够自动提取特征,但它们严重依赖于标记数据,而标记数据的获取往往较为困难。
基于有效载荷的基础模型
近年来,预训练基础模型因其在解决标记数据不足问题上的潜力而受到广泛关注。这些模型在大量未标记数据上进行预训练,并在下游标记任务上进行微调。例如,PERT(He, Yang, and Chen, 2020)和ET-BERT(Lin et al., 2022)通过词典对流量数据进行分词。PERT采用掩码语言建模(Masked Language Modeling, MLM)任务进行预训练,而ET-BERT则引入改进的MLM任务和下一句预测(Next Sentence Prediction, NSP)任务。此外,YaTC(Zhao et al., 2023)作为一种视觉模型的改编,将流量数据分块并使用掩码自编码器(Masked Auto-Encoder, MAE)进行预训练。然而,这些方法未能充分考虑流量的结构特性以及数据包之间的关系。
为解决上述局限性,我们提出了多实例加密流量Transformer架构(Multi-Instance Encrypted Traffic Transformer, MIETT),该模型通过引入新颖的数据包相对位置预测(Packet Relative Position Prediction, PRPP)任务和流量对比学习(Flow Contrastive Learning, FCL)任务,更好地捕捉流量的复杂性。
方法
多实例加密流量 Transformer
在加密流量分类任务中,我们将原始网络流量(PCAP 追踪文件)作为输入,目标是将其分类到类别中,例如 VPN 服务(如 P2P、流媒体、电子邮件)和应用程序。在本节中,我们首先概述将原始数据转换为多实例流量表示的预处理步骤。然后,我们介绍我们的多实例加密流量 Transformer(Multi-Instance Encrypted Traffic Transformer,MIETT)架构,该架构专门设计用于高效处理和分类此类流量数据。
MIETT 编码器
本节详细说明了如何为多实例加密流量 Transformer(MIETT)架构表示多实例流量数据。该过程包括三个关键步骤:原始数据的分词化、单个数据包的表示,以及这些数据包表示的聚合形成统一的流表示。
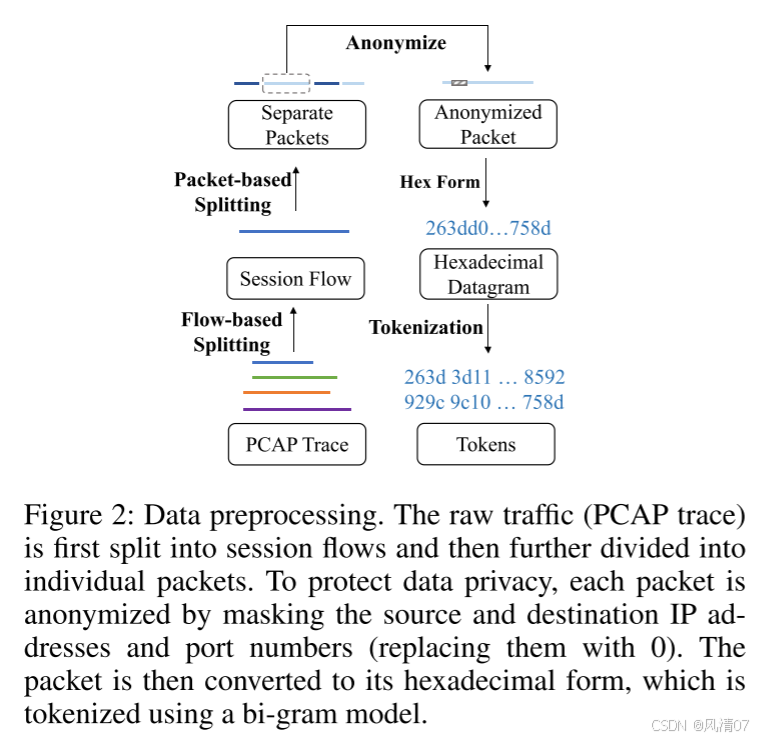
分词化(Tokenization) 通过图 2 所示的数据预处理步骤获得流的十六进制序列。遵循 ET-BERT(Lin 等人,2022)的做法,我们使用双字节模型(bi-gram model)对十六进制序列进行编码,其中每个单元由两个连续字节组成。然后我们利用字节对编码(Byte-Pair Encoding,BPE)进行词元表示,词元单元的取值范围为 0 到 65535,最大词典大小为 65536。对于训练,我们还引入了特殊词元,包括 [CLS]、[PAD] 和 [MASK]。
数据包表示(Packet Representation) 每个数据包以 [CLS] 词元开始,后接从数据包内容中提取的词元,内容包括包含元特征的包头和加密负载。每个词元的嵌入由两部分组成:位置嵌入(position embedding),指示词元在数据包中的位置,以及数值嵌入(value embedding)。为了保证信息利用的高效性并避免过度关注长包,数据包长度被标准化为固定大小 128。长度短于 128 的数据包在末尾使用 [PAD] 词元进行填充。
流表示(Flow Representation) 流表示由多个数据包表示组成,这些表示堆叠形成一个矩阵 X ∈ RN×L×d,其中 N 是数据包数量,L 是数据包长度,d 是嵌入维度。这种多实例表示方式,与 ET-BERT 所采用的直接拼接数据包的方法不同,能够更有效地建模数据包之间的关系,并更好地捕获流的组织结构。
MIETT 架构
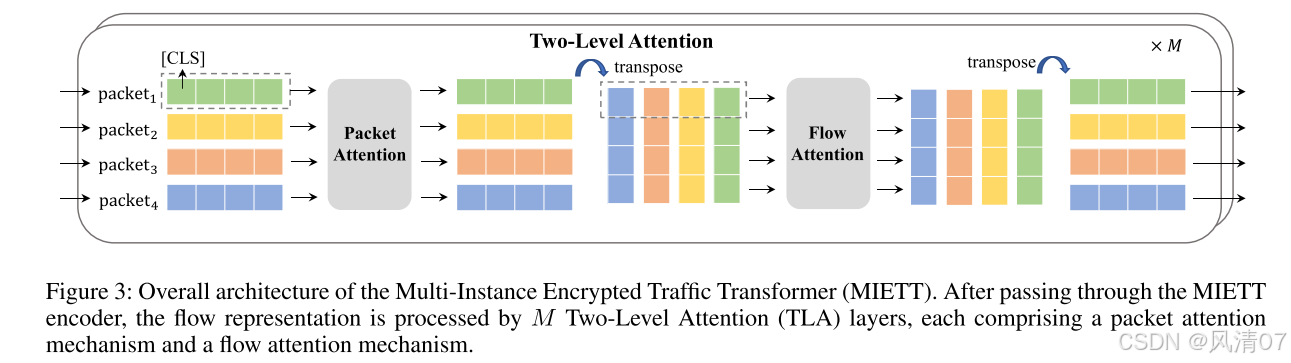
流表示是一个二维的词元映射,可以被展平成一维序列输入标准 Transformer,就像 ViT(Dosovitskiy 等人,2021)和 YaTC(Zhao 等人,2023)在预训练和微调阶段所做的那样。然而,这种方法引入了两个问题:(1) 展平序列会丢失时间信息,例如数据包顺序,可能会忽略重要的依赖关系。虽然二维位置嵌入可以指示时间关系,但它不够灵活,并且可能在诸如数据包丢失的场景中失效。(2) 计算复杂度,即 O(N2L2d),随着包含更多数据包的引入而显著增加,因为序列长度被扩展。为了解决这些问题,我们引入了双层注意力(Two-Level Attention,TLA)层,以保留时间结构并保持计算效率。
整体架构(Overall Architecture) 多实例加密流量 Transformer(MIETT)首先按照 MIETT 编码器部分所述方式进行词元嵌入。接下来,流表示经过 M 个 TLA 层处理。最后,所有数据包的 [CLS] 词元嵌入被用于预训练或微调任务。MIETT 的整体架构如图 3 所示。
双层注意力(Two-Level Attention,TLA)层 TLA 层捕获包内和包间依赖关系,以增强模型对复杂流量流的理解。它包括两个阶段:数据包注意力(Packet Attention)和流注意力(Flow Attention)。在数据包注意力阶段,多头自注意力(Multi-Head Self-Attention,MHSA)在单个数据包内应用,用于识别词元之间的依赖关系,确保模型理解每个数据包的内部结构。对于 MHSA,键、查询和值都设置为输入序列,输出为增强的序列表示。在流注意力阶段,MHSA 在每个位置跨数据包表示应用,用于捕获不同数据包之间的依赖关系。这种两阶段方法有效地建模了流量的层次结构,通过结合细粒度的数据包级特征与更广泛的包间关系,显著提升了模型捕获复杂依赖关系的能力,但同时也引入了计算复杂度。
在数据包注意力(Packet Attention)阶段的多头自注意力机制(MHSA)复杂度为 O(L²d)(每个数据包),而在流注意力(Flow Attention)阶段的复杂度为 O(N²d)(每个位置),因此总体复杂度为 O(NL²d + LN²d)。
当默认参数 L = 128、N = 5 时,我们的方法比将序列展平成一维输入标准 Transformer 的方法高效约 4.8 倍。
数据包注意力(Packet Attention) 在 TLA 层的第一阶段,我们专注于包内关系,通过在每个独立数据包内执行多头自注意力(Multi-Head Self-Attention, MHSA)来实现。
设流表示为
X
∈
R
N
×
L
×
d
,
X \in \mathbb{R}^{N \times L \times d},
X∈RN×L×d,
其中 N 为数据包数量,L 为数据包长度,d 为嵌入维度。
对于每个数据包
X
i
∈
R
L
×
d
,
X_i \in \mathbb{R}^{L \times d},
Xi∈RL×d,
我们应用自注意力以捕获数据包内词元之间的依赖关系,过程如下:
X
^
i
p
k
t
=
L
a
y
e
r
N
o
r
m
(
X
i
+
M
H
S
A
p
k
t
(
X
i
)
)
(1)
\hat{X}^{pkt}_i = LayerNorm(X_i + MHSA^{pkt}(X_i)) \tag{1}
X^ipkt=LayerNorm(Xi+MHSApkt(Xi))(1)
X
i
p
k
t
=
L
a
y
e
r
N
o
r
m
(
X
^
i
p
k
t
+
M
L
P
(
X
^
i
p
k
t
)
)
(2)
X^{pkt}_i = LayerNorm(\hat{X}^{pkt}_i + MLP(\hat{X}^{pkt}_i)) \tag{2}
Xipkt=LayerNorm(X^ipkt+MLP(X^ipkt))(2)
流注意力(Flow Attention) 在 TLA 层的第二阶段,我们专注于包间关系,通过在每个数据包的位置上执行多头自注意力(MHSA)来捕获不同数据包之间的依赖。
设经过包注意力阶段更新后的流表示为
X
p
a
c
k
e
t
∈
R
N
×
L
×
d
.
X^{packet} \in \mathbb{R}^{N \times L \times d}.
Xpacket∈RN×L×d.
对于每个位置 j(其中 j ∈ {1, 2, …, L}),我们收集该位置在所有数据包中的词元表示,形成一个矩阵
X
⋅
j
p
a
c
k
e
t
∈
R
N
×
d
,
X^{packet}_{·j} \in \mathbb{R}^{N \times d},
X⋅jpacket∈RN×d,
其中 N 为数据包数量。
然后,我们对这些矩阵应用自注意力以捕获不同数据包之间的依赖关系,过程如下:
X
^
⋅
j
f
l
o
w
=
L
a
y
e
r
N
o
r
m
(
X
⋅
j
p
k
t
+
M
H
S
A
f
l
o
w
(
X
⋅
j
p
k
t
)
)
(3)
\hat{X}^{flow}_{·j} = LayerNorm(X^{pkt}_{·j} + MHSA^{flow}(X^{pkt}_{·j})) \tag{3}
X^⋅jflow=LayerNorm(X⋅jpkt+MHSAflow(X⋅jpkt))(3)
X
⋅
j
f
l
o
w
=
L
a
y
e
r
N
o
r
m
(
X
^
⋅
j
f
l
o
w
+
M
L
P
(
X
^
⋅
j
f
l
o
w
)
)
(4)
X^{flow}_{·j} = LayerNorm(\hat{X}^{flow}_{·j} + MLP(\hat{X}^{flow}_{·j})) \tag{4}
X⋅jflow=LayerNorm(X^⋅jflow+MLP(X^⋅jflow))(4)
训练任务(Training Tasks)
本节概述了为提升模型加密流量分类能力而设计的训练任务。
预训练阶段包括三种任务:
掩码流预测(Masked Flow Prediction, MFP)、
数据包相对位置预测(Packet Relative Position Prediction, PRPP) 和
流对比学习(Flow Contrastive Learning, FCL)。
这些任务帮助模型捕获流依赖关系、预测数据包顺序,并区分流级特征。
在预训练之后,模型将被微调用于流量分类任务,以优化最终性能。
预训练任务(Pre-Training Tasks)
我们提出的模型由多个双层注意力(Two-Level Attention, TLA)层组成,用于有效捕获流量中包级与流级的信息。
在预训练阶段,我们使用预训练的 ET-BERT 检查点作为包注意力模块的初始化,并在训练中保持其冻结状态,而流注意力模块则被训练以学习流的整体结构和依赖关系。
这种设计使模型能够继承稳定的包级特征,同时专注于增强流级理解。
图 4 展示了我们提出的三种预训练任务的总体结构。
掩码流预测(Masked Flow Prediction, MFP)任务 掩码流预测任务旨在增强模型处理不完整流信息的能力。
在该任务中,随机屏蔽流中 15% 的词元,模型需根据未被屏蔽的上下文预测被掩盖词元的原始内容。
通过训练流编码器推测缺失的词元,模型能够学习流的潜在结构与依赖关系。
数据包相对位置预测(Packet Relative Position Prediction, PRPP)任务 数据包相对位置预测任务旨在根据每个数据包的 [CLS] 词元嵌入预测流中数据包的相对顺序。
该任务帮助模型理解数据包之间的时序关系,这对于准确建模流量至关重要。
给定包含 N 个数据包的输出流表示,
设
O
p
k
t
∈
R
N
×
d
O^{pkt} \in \mathbb{R}^{N \times d}
Opkt∈RN×d
表示流中所有数据包 [CLS] 词元的嵌入,其中 d 为嵌入维度。
任务目标是确定对于任意数据包对 (i, j),数据包 i 是否在数据包 j 之前。
首先,对 [CLS] 词元进行线性变换、激活函数与层归一化处理:
P
=
L
a
y
e
r
N
o
r
m
(
G
E
L
U
(
O
p
k
t
W
1
+
b
1
)
)
(5)
P = LayerNorm(GELU(O^{pkt} W_1 + b_1)) \tag{5}
P=LayerNorm(GELU(OpktW1+b1))(5)
其中
(W_1 \in \mathbb{R}^{d \times d}),
(b_1 \in \mathbb{R}^d)
为可学习参数,(P \in \mathbb{R}^{N \times d})。
然后,预测数据包 (i, j) 的相对位置如下:
z
^
i
j
=
S
o
f
t
m
a
x
(
(
P
i
−
P
j
)
W
2
+
b
2
)
(6)
\hat{z}_{ij} = Softmax((P_i - P_j)W_2 + b_2) \tag{6}
z^ij=Softmax((Pi−Pj)W2+b2)(6)
其中
(W_2 \in \mathbb{R}^{d \times 2}),
(b_2 \in \mathbb{R}^2)
为可学习参数,
(\hat{z}_{ij} \in \mathbb{R}^2) 表示数据包 i 位于数据包 j 之前或之后的概率。
真实标签 (z_{ij} \in {0,1}) 依据原始数据包顺序定义:
z
i
j
=
{
1
,
若数据包
i
在
j
之前
0
,
否则
(7)
z_{ij} = \begin{cases} 1, & \text{若数据包 } i \text{ 在 } j \text{ 之前} \\ 0, & \text{否则} \end{cases} \tag{7}
zij={1,0,若数据包 i 在 j 之前否则(7)
最终,PRPP 损失 (L_{PRPP}) 通过预测标签与真实标签之间的交叉熵计算得到:
L
P
R
P
P
=
−
∑
i
,
j
,
i
≠
j
[
z
i
j
log
(
z
^
i
j
)
+
(
1
−
z
i
j
)
log
(
1
−
z
^
i
j
)
]
(8)
L_{PRPP} = -\sum_{i,j,i \neq j} [ z_{ij} \log(\hat{z}_{ij}) + (1 - z_{ij}) \log(1 - \hat{z}_{ij}) ] \tag{8}
LPRPP=−i,j,i=j∑[zijlog(z^ij)+(1−zij)log(1−z^ij)](8)
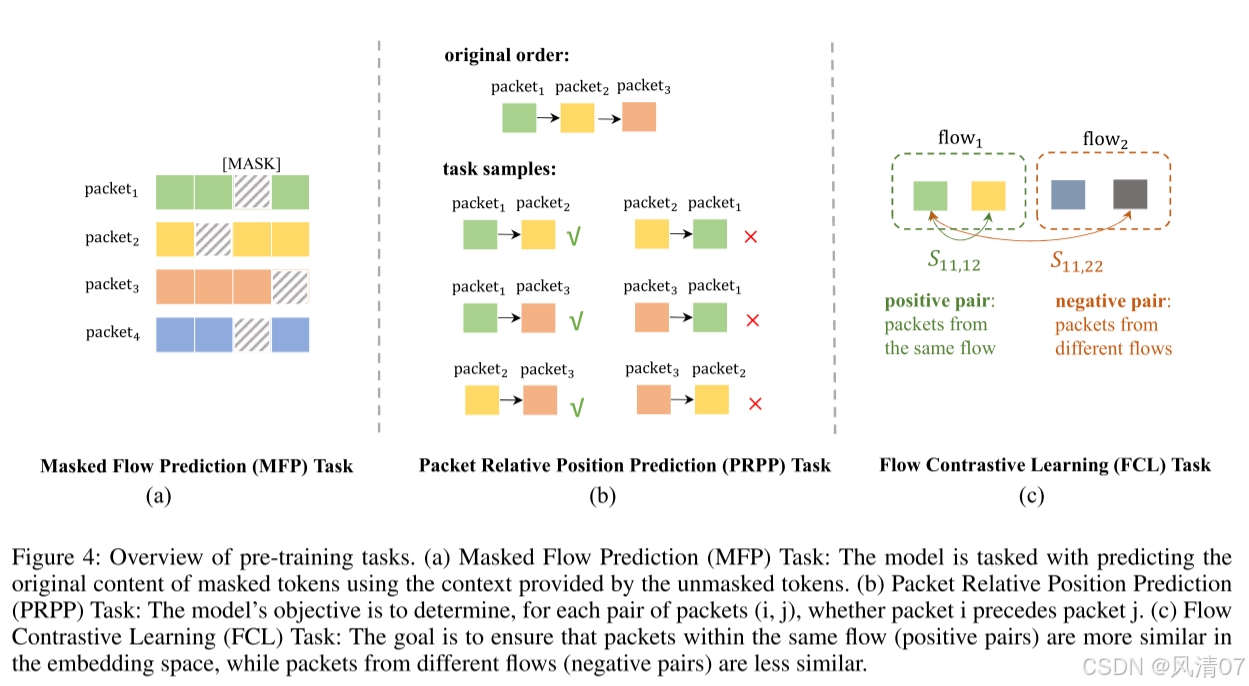
流对比学习(Flow Contrastive Learning, FCL)任务 流对比学习任务旨在通过学习鲁棒的特征表示,增强模型区分不同流量的能力。
其目标是确保同一流中的数据包(正样本对)在嵌入空间中具有更高的相似度,而来自不同流的数据包(负样本对)则相似度更低。
值得注意的是,正负样本对均通过在各自流中使用相同的数据包位置构建,从而在比较过程中保持一致性。
给定一个批次的输出流表示,设
O
f
l
o
w
∈
R
B
S
×
N
×
d
O^{flow} \in \mathbb{R}^{BS \times N \times d}
Oflow∈RBS×N×d
表示批次中所有流中各数据包 [CLS] 词元的嵌入,
其中 BS 表示批量大小(batch size),N 表示每个流的数据包数量,d 为嵌入维度。
首先,对每个 [CLS] 词元应用多层感知机(MLP)变换:
C
=
L
a
y
e
r
N
o
r
m
(
G
E
L
U
(
O
f
l
o
w
W
3
+
b
3
)
)
(9)
C = LayerNorm(GELU(O^{flow} W_3 + b_3)) \tag{9}
C=LayerNorm(GELU(OflowW3+b3))(9)
C
=
C
W
4
+
b
4
(10)
C = C W_4 + b_4 \tag{10}
C=CW4+b4(10)
其中
(W_3 \in \mathbb{R}^{d \times d}),
(b_3 \in \mathbb{R}^d),
(W_4 \in \mathbb{R}^{d \times d}),
(b_4 \in \mathbb{R}^d)
均为可学习参数,输出 (C \in \mathbb{R}^{BS \times N \times d})。
接下来,使用余弦相似度计算两个数据包之间的相似性:
S
i
1
j
1
,
i
2
j
2
=
C
i
1
j
1
T
C
i
2
j
2
∥
C
i
1
j
1
∥
∥
C
i
2
j
2
∥
(11)
S_{i_1 j_1, i_2 j_2} = \frac{C^{T}_{i_1 j_1} C_{i_2 j_2}}{\|C_{i_1 j_1}\| \, \|C_{i_2 j_2}\|} \tag{11}
Si1j1,i2j2=∥Ci1j1∥∥Ci2j2∥Ci1j1TCi2j2(11)
其中 (i_1, i_2) 表示批次中流的 ID,(j_1, j_2) 表示流内数据包的位置,(C_{ij} \in \mathbb{R}^d)。
最后,使用相似度矩阵 S 计算对比损失:
L
F
C
L
=
−
∑
i
1
,
j
1
,
j
2
,
j
1
≠
j
2
log
exp
(
S
i
1
j
1
,
i
1
j
2
)
exp
(
S
i
1
j
1
,
i
1
j
2
)
+
∑
i
2
≠
i
1
exp
(
S
i
1
j
1
,
i
2
j
2
)
(12)
L_{FCL} = - \sum_{i_1, j_1, j_2, j_1 \neq j_2} \log \frac{ \exp(S_{i_1 j_1, i_1 j_2}) }{ \exp(S_{i_1 j_1, i_1 j_2}) + \sum_{i_2 \neq i_1} \exp(S_{i_1 j_1, i_2 j_2}) } \tag{12}
LFCL=−i1,j1,j2,j1=j2∑logexp(Si1j1,i1j2)+∑i2=i1exp(Si1j1,i2j2)exp(Si1j1,i1j2)(12)
其中 (i_1, i_2 \in [1, BS]) 表示批次中的流 ID,(j_1, j_2 \in [1, N]) 表示流内的数据包位置。
结论(Conclusion)
总体而言,预训练阶段的最终损失为上述三种损失的加权和:
L
p
t
=
L
M
F
P
+
α
L
P
R
P
P
+
β
L
F
C
L
(13)
L_{pt} = L_{MFP} + \alpha L_{PRPP} + \beta L_{FCL} \tag{13}
Lpt=LMFP+αLPRPP+βLFCL(13)
其中,α 和 β 为超参数。
微调任务(Fine-Tuning Task)
微调任务的目标是将给定的流分类到特定的类别中。
在流经过多个 TLA 层处理后,我们通过提取所有数据包的 [CLS] 词元嵌入获得流的表示。
这些嵌入表示每个数据包的特征,随后通过 平均池化(mean pooling) 进行聚合,以形成整个流的综合表示。
该平均池化后的流表示被输入到一个 多层感知机(Multi-Layer Perceptron, MLP) 中,用于生成最终的分类输出,从而预测该流所属的类别。
在此阶段,整个模型(包括在预训练阶段被冻结的包编码器和流编码器)都会被联合微调。
微调过程通过最小化交叉熵损失来优化模型:
L f t = − ∑ c y c log ( y ^ c ) (14) L_{ft} = - \sum_c y_c \log(\hat{y}_c) \tag{14} Lft=−c∑yclog(y^c)(14)
其中,(y_c) 为真实标签,(\hat{y}_c) 为类别 (c) 的预测概率。
实验(Experiments)
实验设置(Experiment Setup)
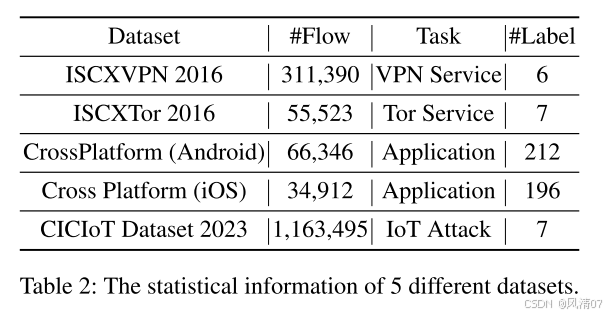
数据集与基准(Datasets and Benchmarks) 在加密流量分类任务中,我们在五个数据集上评估了所提出的方法:
ISCXVPN 2016(Draper-Gil 等人,2016)、ISXTor 2016(Lashkari 等人,2017)、CrossPlatform(Van Ede 等人,2020)数据集(包括 Android 与 iOS 两个子集),以及 CIC IoT Dataset 2023(Neto 等人,2023)。
我们使用了 NetBench(Qian 等人,2024)提供的预处理数据。用于预训练的数据由 NetBench 中所有五个数据集的训练集组成,且不包含标签。数据集统计信息与微调任务描述详见表 2。数据划分比例为训练集、验证集、测试集 = 8:1:1。
对比方法(Compared Methods) 我们将所提方法与 7 种基于负载(payload-based)的方式进行比较,包括以下深度学习方法:
Datanet(Wang 等人,2018)、Fs-Net(Liu 等人,2019)、BiLSTM ATTN(Yao 等人,2019)、DeepPacket(Lotfollahi 等人,2020)、TSCRNN(Lin, Xu, and Gao, 2021),以及基础模型 ET-BERT(Lin 等人,2022)和 YaTC(Zhao 等人,2023)。
实现细节(Implementation Details) 在预训练阶段,训练步数设为 150,000,并随机选取前 10 个数据包中的 5 个用于训练。
掩码流预测(MFP)任务的掩码比例设为 15%。
数据包相对位置预测(PRPP)与 MFP 任务的权重均设为 0.2。
在微调阶段,使用前 5 个数据包训练 30 个 epoch。
在两个阶段中,数据包长度(L)设为 128,数据包数量(N)设为 5,嵌入维度(d)设为 768,双层注意力(TLA)层数设为 12。
学习率设为 2 × 10⁻⁵,并使用 AdamW 优化器。
所有实验均在搭载两张 NVIDIA RTX A6000 GPU 的服务器上进行。
主要结果(Main Results)
主要比较指标包括 准确率(Accuracy) 与 F1-Score。
Accuracy 衡量预测正确的比例,而 F1-Score 平衡了精确率与召回率。
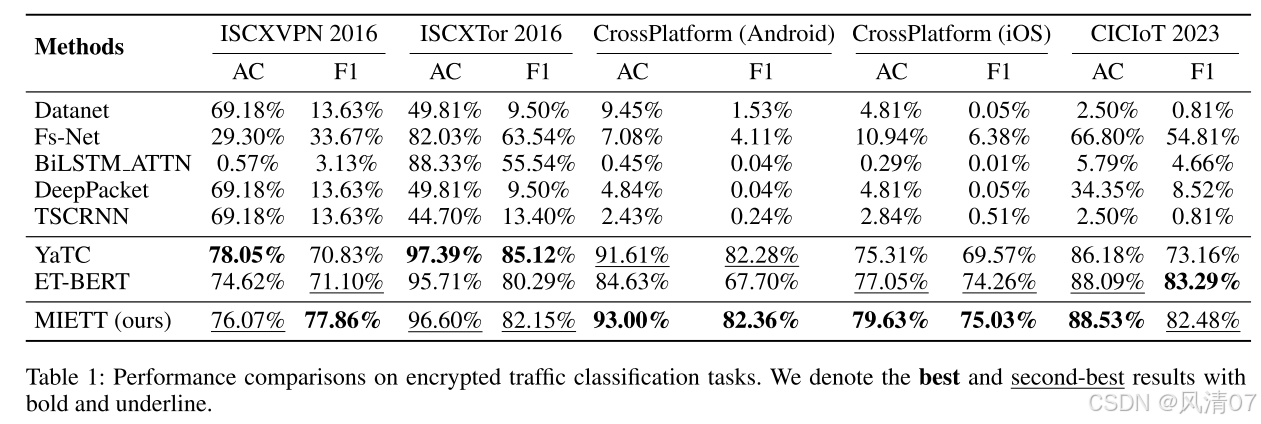
表 1 展示了在加密流量分类任务上的各模型性能比较,基线结果来自 NetBench(Qian 等人,2024)。
结果表明,传统深度学习方法(如 DataNet、DeepPacket、FS-Net、TSCRNN 和 BiLSTM ATTN)在复杂数据集上难以有效泛化。
这些模型往往对主导类别存在偏倚,导致在诸如 CrossPlatform(Android)与 CrossPlatform(iOS)等数据集上 F1-Score 一贯偏低。
相比之下,我们的 MIETT 模型 在准确率与 F1-Score 上均表现出显著提升,展现了其在应对加密流量复杂性方面的优势。
特别地,在 CrossPlatform(Android)数据集中,MIETT 相较于 ET-BERT 的准确率提升 8.27%,F1-Score 提升 14.66%,突显了流注意力机制的有效性。
消融实验(Ablation Study)
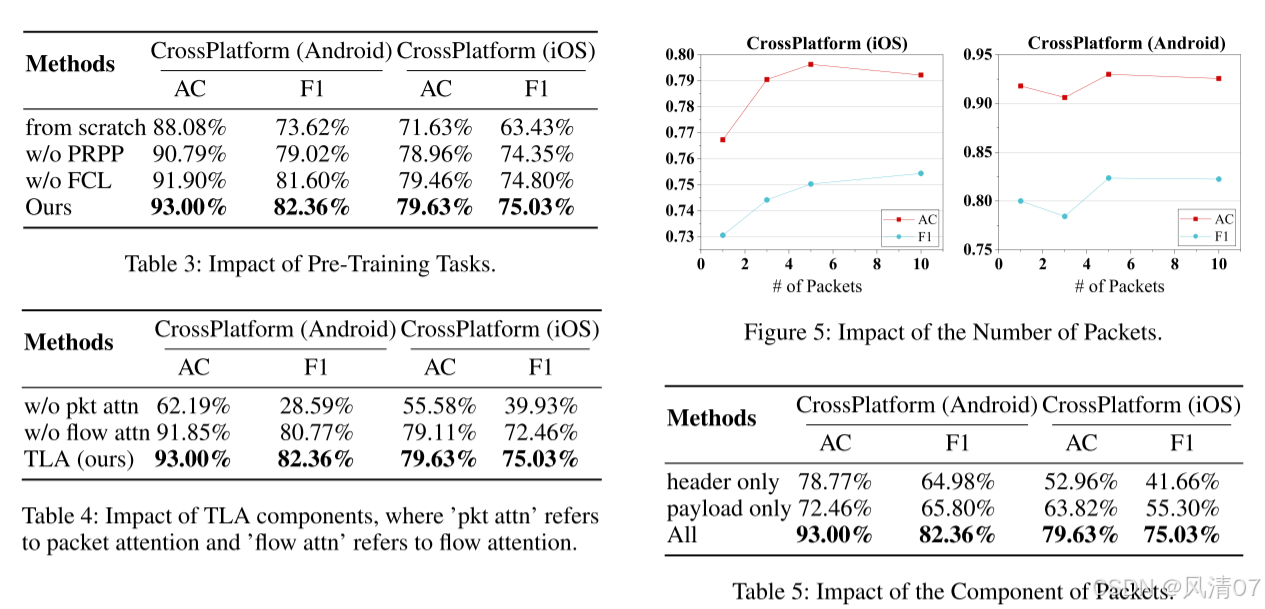
预训练任务的影响(Impact of Pre-Training Tasks) 表 3 展示了在 CrossPlatform(Android)与 CrossPlatform(iOS)数据集上不同预训练任务组合的消融实验结果,用以评估各任务的贡献。
基线模型(“from scratch”)虽表现尚可,但结果表明预训练显著提升了模型对新任务的泛化能力。
进一步加入特定预训练任务(如 PRPP 与 FCL)可进一步增强模型性能。
TLA 组件的影响(Impact of TLA Components) TLA 同时捕获包内与包间依赖关系,有效应对跨包 token-to-token 建模挑战。
表 1 显示,仅使用 token-level 注意力的 ET-BERT 模型表现较差。
如表 4 所示,在 CrossPlatform(Android)上,移除流注意力导致错误率上升 16.4%,而使用 token-mean 作为包级嵌入则将准确率降低至 62.19%,这说明两级注意力机制缺一不可。
数据包数量的影响(Impact of the Number of Packets) 图 5 展示了不同数据包数量对性能的影响。
左图表明,随着数据包数量增加(提供更多信息),F1 分数随之上升,这符合预期。
然而,在 CrossPlatform(Android)数据集上,仅使用一个数据包的准确率(91.79%)甚至高于使用三个包的结果,且超过所有使用五个包的基线模型。
这表明在某些数据集中,初始数据包可能包含最关键信息,增加数据包数量未必总能带来性能提升。
如果包间关系未被有效建模,反而可能降低性能。
此外,这种现象可能归因于预训练阶段(使用五个包)与微调阶段(使用三个包)之间的数据分布不匹配。
数据包组成的影响(Impact of the Component of Packets) 表 5 展示了基于负载(payload-based)方法在流量分类中的优势。
当仅使用数据包头部(header)时,模型性能显著下降,说明头部信息不足以支持精确分类。
而当仅使用负载(payload)时,由于其包含了实际传输数据,模型的 F1-Score 提升明显,尤其在复杂数据集(如 CrossPlatform iOS)上更为突出。
这表明基于负载的方法在捕获流量关键特征方面更具优势,是加密流量分类的更优选择。
将 头部与负载信息结合使用 则能获得最佳结果。
结论
为了解决加密流量分类中的挑战,我们提出了MIETT模型。通过新颖的模型架构和预训练策略,MIETT能够有效学习时间和流量特定的动态特性。实验结果表明,MIETT在五个数据集上的表现优于现有方法。未来的工作将探索在资源受限场景下的流量分类(Zhou, 2024)。


















 3726
3726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









