







unsloth相关简介
Unsloth 凭借其高效的训练优化和低资源需求,成为微调领域的热门工具,尤其适合中小团队和个人开发者,而其他方法如 LoRA、蒸馏和强化学习,则在特定场景(如模型压缩或对齐优化)中表现突出, 选择时需结合任务需求、硬件条件及开发周期综合考量。
一、Unsloth 的核心特点与优势
(1)训练速度与显存优化
Unsloth 通过 Triton 优化的 GPU 内核 和 低秩适配器(LoRA/QLoRA) 技术,实现了训练速度提升 2-5 倍,显存占用减少 60%-80%。例如,微调 Llama3-8B 模型时,训练时间减少 30.72%,显存占用降低 42.58%。支持 4 位量化(4-bit quantization),可在 16GB 显存的 GPU 上运行大规模模型(如 32B 参数的 Qwen1.5),显著降低了硬件门槛。
(2)技术实现细节
手写 GPU 内核:通过手动推导数学计算步骤并重写核心算子(如 RoPE 和注意力机制),减少冗余计算,提升效率。
动态上下文长度支持:支持超长上下文微调(如 Gemini 的百万级 Token),且通过梯度检查点技术优化内存管理。
(3)易用性与兼容性
无缝集成 Hugging Face 生态,支持 Llama3、Mistral、Gemma、Qwen1.5 等主流模型。
提供自动化的数据集处理工具(如多轮对话扩展和提示模板标准化),简化数据准备流程。
(4)应用场景
领域知识灌注:通过少量领域数据(如医疗、法律)快速适配模型。
对话风格定制:优化模型在客服、虚拟助手等场景的交互体验。
二、其他主流微调方法
除 Unsloth 外,以下方法在 LLM 微调中广泛应用:
全量微调(Full Fine-Tuning)
特点:调整模型全部参数,适合需要深度适应特定任务的场景(如复杂推理或专业领域知识学习)。
缺点:计算资源消耗大,通常需多卡并行或高性能 GPU。
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
LoRA(Low-Rank Adaptation):通过引入低秩矩阵调整部分参数,显存占用减少 4-10 倍,适合资源有限场景。
QLoRA(Quantized LoRA):结合 4 位量化与 LoRA,进一步降低显存需求,支持在消费级 GPU 上微调 70B 参数模型。
Adapter:在模型层间插入小型网络模块,仅训练适配器参数,保留原始权重6。
模型蒸馏(Knowledge Distillation)
原理:将大型教师模型的知识迁移到小型学生模型,实现模型压缩。例如,DeepSeek-R1 通过蒸馏技术将模型推理需求降至 7GB 显存。
应用:适用于边缘设备部署或低延迟场景。
强化学习微调(RLHF)
流程:基于人类反馈的奖励模型优化生成策略,提升模型对齐性(如 ChatGPT 的训练)。
挑战:需构建复杂的奖励机制和交互环境。
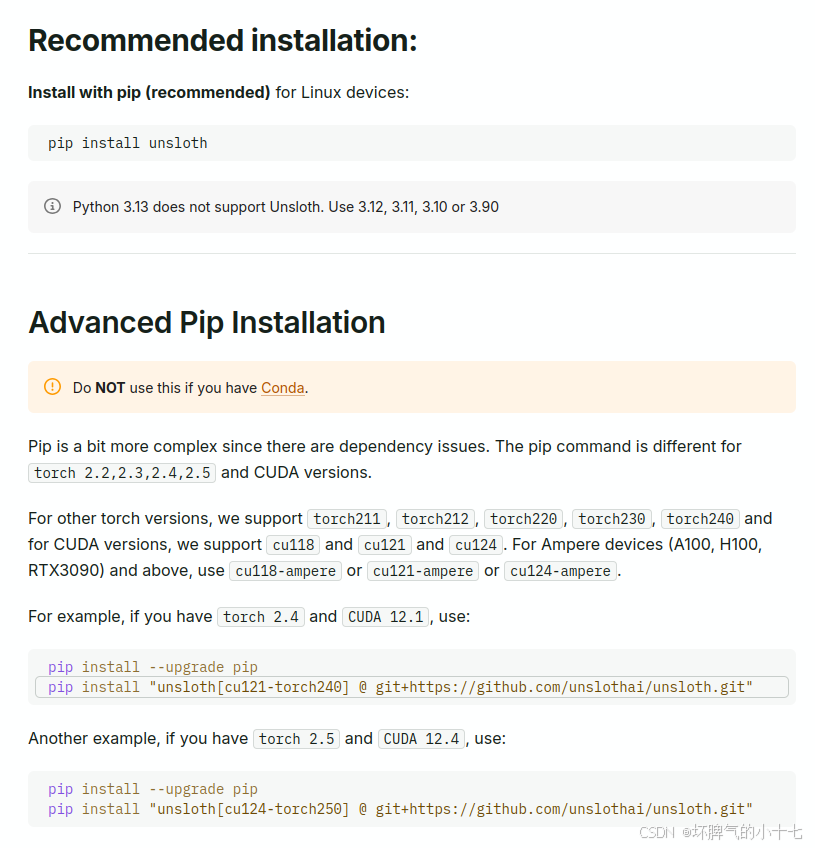
Unsloth安装教程
根据链接中信息可知:unsloth支持python3.9/3.10/3.11/3.12,因此在实际使用中需要注意python版本,且对应的torch及cuda版本也有要求,因此需要注意自身设备及环境版本,最好的方法是创建新的虚拟环境,使用以下命令安装,若无法调用,则根据自身设备情况对torch版本进行微调即可,需要提前安装git环境
conda create -n aa python=3.10
pip install --upgrade pip
pip install "unsloth[cu121-torch240] @ git+https://github.com/unslothai/unsloth.git"
https://docs.unsloth.ai/get-started/installing-±updating/pip-install
Unsloth微调实践
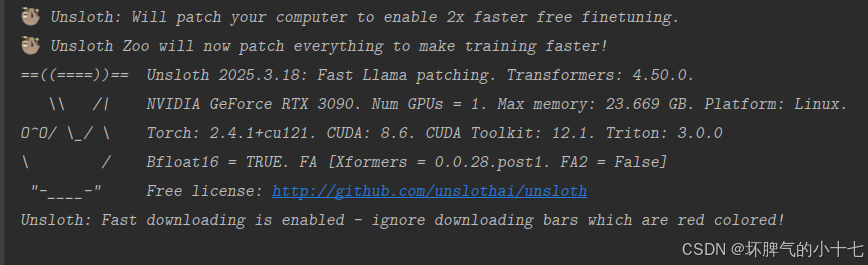
1、导入 Unsloth 提供的 FastLanguageModel 类,用于加载和操作高效的大型语言模型
import torch
from datasets import load_dataset
from unsloth import FastLanguageModel
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
from modelscope import snapshot_download
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
)
此处可能遇到以下问题,这是由于你的服务器没有办法连接huggingface的原因,你可以直接在你的服务器上尝试能否直接ping进行测试:
ping huggingface.co
'(MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /bert-base-uncased/resolve/main/vocab.txt (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7f1320354880>, 'Connection to huggingface.co timed out. (connect timeout=10)'))"), '(Request ID: 625af900-631f-4614-9358-30364ecacefe)')' thrown while requesting HEAD https://huggingface.co/bert-base-uncased/resolve/main/vocab.txt
'(MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /bert-base-uncased/resolve/main/added_tokens.json (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7f1320354d60>, 'Connection to huggingface.co timed out. (connect timeout=10)'))"), '(Request ID: 1679a995-7441-4afe-a685-9a7bd6da9f2a)')' thrown while requesting HEAD https://huggingface.co/bert-base-uncased/resolve/main/added_tokens.json
'(MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /bert-base-uncased/resolve/main/special_tokens_map.json (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7f13202fb250>, 'Connection to huggingface.co timed out. (connect timeout=10)'))"), '(Request ID: 9af5b73e-5230-45d7-8886-5d37d38f09a8)')' thrown while requesting HEAD https://huggingface.co/bert-base-uncased/resolve/main/special_tokens_map.json
'(MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /bert-base-uncased/resolve/main/tokenizer_config.json (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7f13202fb730>, 'Connection to huggingface.co timed out. (connect timeout=10)'))"), '(Request ID: 12136040-d033-4099-821c-dcb80fb50018)')' thrown while requesting HEAD https://huggingface.co/bert-base-uncased/resolve/main/tokenizer_config.json
Traceback (most recent call last):
File "/tmp/pycharm_project_494/Zilean-Classifier/main.py", line 48, in <module>
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
File "/root/miniconda3/envs/DL/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1838, in from_pretrained
raise EnvironmentError(
OSError: Can't load tokenizer for 'bert-base-uncased'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'bert-base-uncased' is the correct path to a directory containing all relevant files for a BertTokenizer tokenizer.
解决方案:
1、科学上网。
2、添加镜像源:
HF-Mirror🌟域名 hf-mirror.com,用于镜像 huggingface.co 域名,作为一个公益项目,致力于帮助国内AI开发者快速、稳定的下载模型、数据集,方法如下:
pip install -U huggingface_hub
- 设置环境变量,Linux,直接在~/.bashrc中添加以下内容:
export HF_ENDPOINT=https://hf-mirror.com
Windows Powershell
$env:HF_ENDPOINT = "https://hf-mirror.com"
- 下载
# 下载模型:
huggingface-cli download --local-dir-use-symlinks False --resume-download deepseek-r1*** --local-dir aa
# 下载数据集:
huggingface-cli download --local-dir-use-symlinks False --repo-type dataset --resume-download aa --local-dir aa
3、基于其他镜像网站进行下载:
pip install modelscope
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Llama-8B README.md --local_dir ./dir
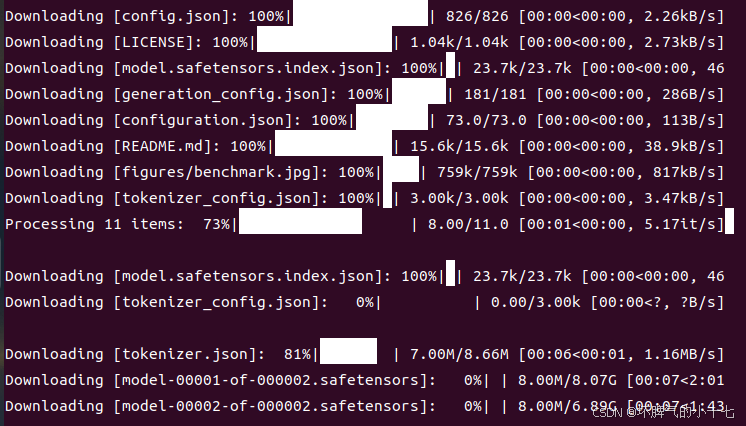
下载完成后将其放入对应路径,否则会提示以下错误:
OSError: Error no file named pytorch_model.bin, model.safetensors, tf_model.h5, model.ckpt.index or flax_model.msgpack found in directory ./huggingface/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit.
定义好训练数据,可以根据自身微调的实际场景进行定义
train_prompt_style = """******。。
# question:
{}
# answer:
{}
"""
EOS_TOKEN = tokenizer.eos_token # 定义结束标记(EOS_TOKEN)
dataset = load_dataset("json", data_files="./data/train_data.json", split="train[0:5000]", trust_remote_code=True)
def formatting_prompts_func(examples):
inputs = examples["course_code"]
cots = examples["question"]
outputs = examples["answer"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
进行模型微调训练:
dataset = dataset.map(formatting_prompts_func, batched=True)
FastLanguageModel.for_training(model)
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)
training_args = TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=75,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=1,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
report_to="none",
)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
packing=False,
args=training_args,
)
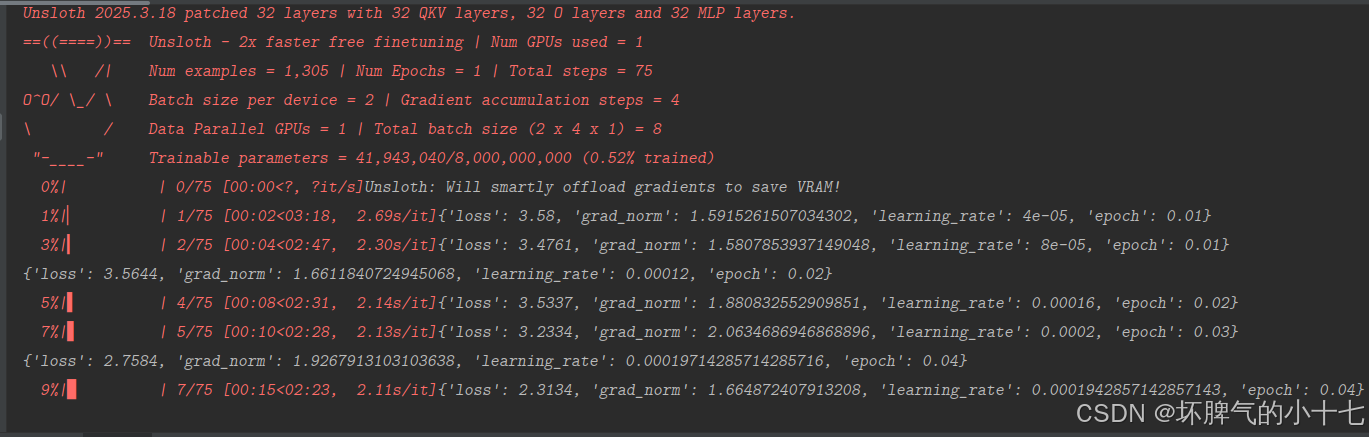
trainer.train()
model.save_pretrained("lora_model")
model.save_pretrained_merged("outputs", tokenizer, save_method = "merged_16bit")
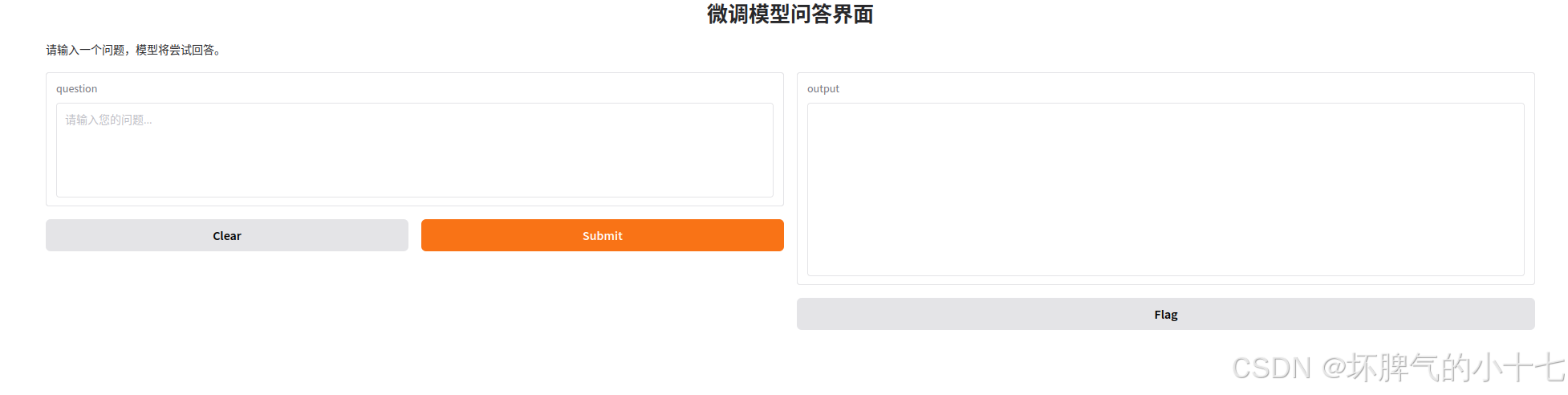
 最后我们就可以利用微调的模型进行测试啦~
最后我们就可以利用微调的模型进行测试啦~
 感谢您阅读到最后!😊总结不易,希望多多支持~🌹 点赞👍收藏⭐评论✍️,您的三连是我持续更新的动力💖~
感谢您阅读到最后!😊总结不易,希望多多支持~🌹 点赞👍收藏⭐评论✍️,您的三连是我持续更新的动力💖~



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











