






 OpenAI的Sora视频生成技术利用了谷歌的Transformer和diffusion-Transformer模型,结合自然语言处理和扩散模型,实现了高质量的文本驱动图像和视频生成。文章探讨了这一技术的工作原理和谷歌未能广泛应用的原因。
OpenAI的Sora视频生成技术利用了谷歌的Transformer和diffusion-Transformer模型,结合自然语言处理和扩散模型,实现了高质量的文本驱动图像和视频生成。文章探讨了这一技术的工作原理和谷歌未能广泛应用的原因。
OpenAI在新年伊始便推出Sora视频生成技术,其逼真的视觉效果令人惊叹。若非经过精心编辑,恐怕难以让人置信。此番OpenAI可谓“抄袭”谷歌,偷家成功。
ChatGPT采用的核心技术Transformer架构最初源自谷歌研究团队撰写的相关学术论文。
Sora 背后的技术,你以为就不是谷歌的这个论文吗?其实也是 !!
Transformer 架构是基于一篇叫做 《attention is all you need》 的论文, Sora 背后的技术叫做《diffusion-Transformer model》。
猜猜这篇论文是谁发的?也是谷歌!
此次OpenAI发布的Sora亦不例外。它所依赖的主导技术即是同样基于Transformer架构的diffusion-Transformer模型,该模型源于谷歌2019年发表的名为“Photorealistic Text-to-lmage Diffusion Models with Deep Language Understanding”长篇论文。
论文以及相关网站地址如下:

[2205.11487] Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (arxiv.org)
Imagen: Text-to-Image Diffusion Models (research.google)
然而仔细阅读相关论文,便能迅速理解这项文生视频及文生图像技术的运作机制。该模型中用到的概念称为扩散模型(diffusion model),简单而言,其基本思想借鉴于物理中的扩散过程。设想往清水中滴入一滴墨水,墨水将随时间扩散至整个水面并改变水的颜色。与此同理,在此过程中,墨水的扩散路径为随机的,并且受到诸多因素影响,如环境温度、水中离子分布、水中其他成分浓度等等。

那么如何利用文本生成图像或视频呢?
首先需要掌握扩散模型的神经网络。然而,真正起决定作用的部分则在于训练数据——即图像完全模糊掉的路径。简单来说,操作步骤如下:首先准备大量带标签的图像库,如某张图片的描述为“小狗图片”。然后对每张图片加入带高斯分布噪声的复制品,每个像素点的颜色均值自原始RGB值进行随机增减,使其呈现出高斯分布。

在对原始图像增加一轮噪声后,改变明显,犹如清水滴入墨水中,随着时间流逝,不断添加噪声,直至无法辨别出其原本的形态。为此,将上述n张经过多次迭代的图片输入神经网络,由神经网络进行自我学习和分析。此过程的目的在于穷尽所有可能的变化路径,从模糊到清晰的转变实际上是一条空间矢量的点的路径集合。为了达到更好的效果,我们通常会使用大量的图片进行训练,例如成千上万亿张带标签的图片。

在训练完神经网络之后,如何通过文本生成图像呢?
对此过程的反向运用即可实现。当我们要求AI生成小狗的图片时,实际上是要得到根据语义在矢量空间中所定义的与小狗相关的路径信息,然后据此反推出生成图片所需的参数。
如果我要AI生成一只有两个头的鸡会发生什么呢?
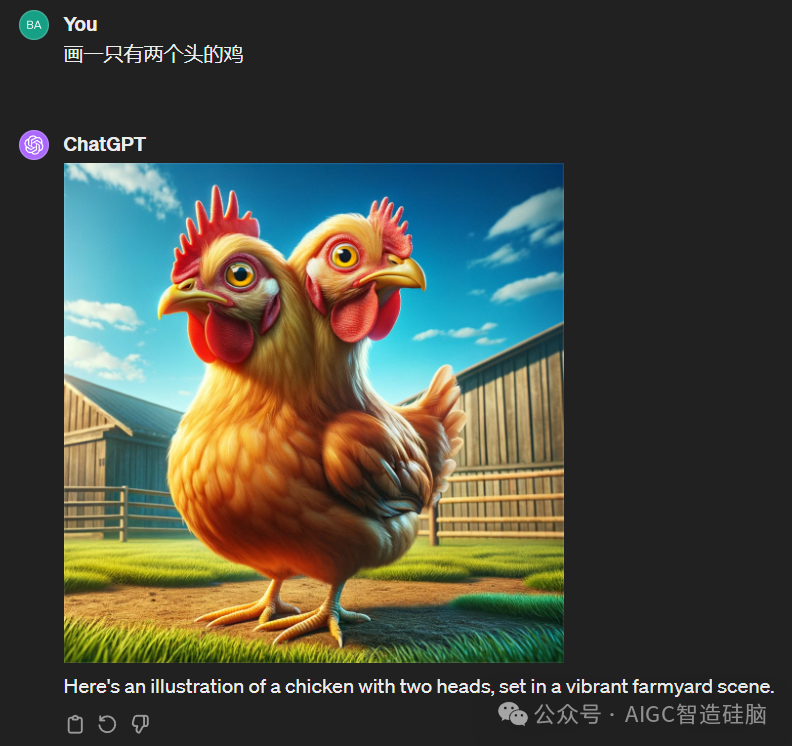
由于我们用于训练的图片并不包含两只头的鸡这种元素,因此需要借助OpenAI的文本处理技术来实现创造力。他们利用强大的中文处理技术,将人们的语句转化为矢量,并在相应的矢量空间中寻找对应的路径,最后通过调整权值使计算结果尽可能符合文意。这正是Sora能产生出色效果的原因,其优秀的自然语言处理能力是实现这一过程的重要保障。
至于视频,相较于图片仅缺少时间维度,即多了一个时间坐标。对于AI来说,处理视频的本质与处理图片无异,均采用向量方法,具体的执行操作可能涉及更多技术细节,此处暂不作详细探讨。Sara之所以能产生出色效果,主要源于其卓越的文本嵌入技术以及丰富优质的数据库资源,此两点对于模型的成功至关重要。虽然其核心算法仍基于扩散变换器,但在实际应用中的每个步骤都饱含着无数技术细节。

关于谷歌为何未能开发利用这些技术,根据我了解到的信息合理推测。
首先,Google作为一家大型公司,必须遵守各种规则,其中包括程序合规和数据隐私等繁琐规定,这些因素使得数据处理的效率降低。其次,作为上市公司,其内部治理结构复杂,涉及众多决策流程。若要实现某些新想法所需的资源相对不足,则可能需要依赖现有谷歌产品的基础加以构建,以最大化经济效益。据传,曾有一位研发人员将纹身视频动画技术路径研究完成后,因无法解决如何将此技术应用于油管的问题而被迫耗时两年。由此可见,大公司并不具有足够的灵活性,同时需面对科技领域激烈的竞争与盈利压力,从而导致了OpenAI的成功崛起。
对于Sora所产生的冲击,尚待深入探讨,但可预见将会对多个行业造成重大影响。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











