







本文介绍C++ 原子操作、内存模型相关知识,包含几种常见的内存访问策略。
一、原子操作和原子类型
1.什么是原子操作
原子操作是一类不可分割的操作,当这样操作在任意线程中进行一半的时候,你是不能查看的;它的状态要不就是完成,要不就是未完成。如果从对象中读取一个值的操作是原子的,并且对对象的所有修改也都是原子的话,那么加载操作要不就会检索对象初始化的值,要不就将值存在某一次修改中。
说白了原子操作就是不可中断的操作,要么被执行要不不被执行。
2.原子类型分类
标准原子类型的定义位于头文件<atomic>内。我们可以通过atomic<>模板定义一些原子类型的变量,如atomic<bool>,atomic<int> 这些类型的操作全是原子化的,支持load()和store()、exchange()、compare_exchange_weak()和compare_exchange_strong()等操作。
从C++17开始,所有的原子类型(atomic_flag 除外)都包含一个静态常量表达式成员变量atomic:;is_always_lock_free。该表达式表明:执行该原子类型X的程序运行所在硬件都以无锁结构形式实现,true表示支持,false表示不支持。
atomic_flag不提供is_lock_free()\is_always_lock_free成员,
atomic_flag在对象初始化的时候清零,通过其成员函数test_and_set检查并设置。或由clear()清零。
std::atomic_flag调用test_and_set成员函数使用:
1) 如果没被设置过(初始化以后或调用clear()后,将
atomic_flag设置为true,函数返回false.2) 如果被设置过则直接返回true。
3.原子操作使用及注意
3.1 原子操作不能拷贝
只要是原子操作,都不能进行赋值和拷贝(因为调用了两个对象,破坏了原子性--拷贝构造和拷贝赋值都会将第一个对象的值进行读取,然后再写入另外一个。对于两个独立的对象,这里就有两个独立的操作了,合并这两个操作必定是不原子的。因此,操作就不被允许。
#include <iostream>
#include <atomic>
int main() {
std::atomic<int> atomicValue(10);
// 不能进行赋值操作
std::atomic<int> anotherAtomicValue = atomicValue; // 编译错误
// 不能进行拷贝操作
// std::atomic<int> copiedAtomicValue(atomicValue); // 编译错误
return 0;
}
3.2 做自旋锁
自旋锁是一种在多线程环境下保护共享资源的同步机制。它的基本思想是,当一个线程尝试获取锁时,如果锁已经被其他线程持有,那么该线程就会不断地循环检查锁的状态,直到成功获取到锁为止。
std::atomic_flag spinLock = ATOMIC_FLAG_INIT; // 初始化自旋锁(自旋锁也用的锁)
void foo() {
while (spinLock.test_and_set(std::memory_order_acquire)) {} // 尝试获取锁
cout<<"thread "<<this_thread::get_id()<<" get spinlock!!!"<<endl;
this_thread::sleep_for(chrono::seconds(10)); //先获取锁的线程延时,查看另一个线程CPU占用率
spinLock.clear(std::memory_order_release); // 释放锁
}
int main() {
std::thread t1(foo);
std::thread t2(foo);
t1.join();
t2.join();
return 0;
}自旋锁使用的时候虽然占用CPU资源(线程在获取锁时会一直循环检查锁是否可用,这会导致线程不断占用CPU时间),但是也有一定的优点:适用于锁被占用时间非常短暂的情况,因为在这种情况下,线程不需要长时间等待锁的释放,使用自旋锁可以避免线程切换带来的开销,提高性能。
二、内存模型
2.1 CPU和内存结构
转载于恋恋风辰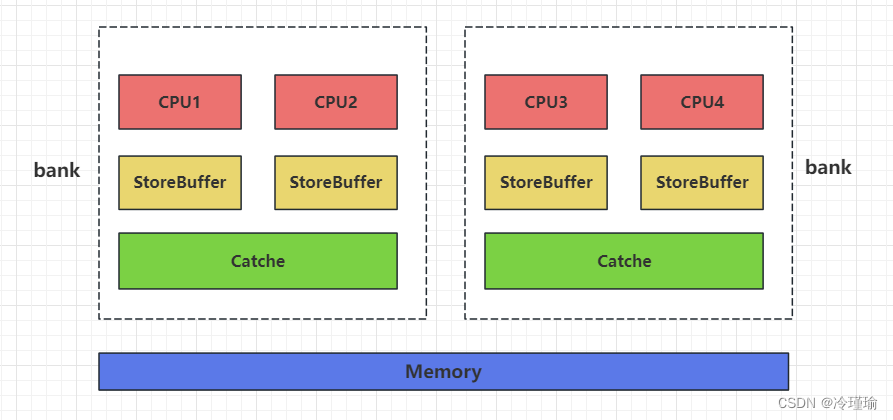
其中StoreBuffer就是一级Cache, Catche是二级Cache,Memory是三级Cache。
每个标识CPU的块就是core,上图画的就是4核结构。每两个core构成一个bank,共享一个cache。四个core共享memory。
每个CPU所作的store均会写到store buffer中,每个CPU会在任何时刻将store buffer中结果写入到cache或者memory中。
MESI 协议,是一种叫作写失效(Write Invalidate)的协议。在写失效协议里,只有一个 CPU 核心负责写入数据,其他的核心,只是同步读取到这个写入。在这个 CPU 核心写入 cache 之后,它会去广播一个“失效”请求告诉所有其他的 CPU 核心。
MESI 协议对应的四个不同的标记,分别是:
M:代表已修改(Modified)
E:代表独占(Exclusive)
S:代表共享(Shared)
I:代表已失效(Invalidated)
"已修改"用来告诉其他cpu已经修改完成,其他cpu可以向cache中写入数据。
"独占"表示数据只是加载到当前 CPU核 的store buffer中,其他的 CPU 核,并没有加载对应的数据到自己的 store buffer 里。
这个时候,如果要向独占的 store buffer 写入数据,我们可以自由地写入数据,而不需要告知其他 CPU 核。
那么对应的,共享状态就是在多核中同时加载了同一份数据。所以在共享状态下想要修改数据要先向所有的其他 CPU 核心广播一个请求,要求先把其他 CPU 核心里面的 cache ,都变成无效的状态,然后再更新当前 cache 里面的数据。
我们可以这么理解,如果变量a此刻在各个cpu的StoreBuffer中,那么CPU1核修改这个a的值,放入cache时通知其他CPU核写失效,因为同一时刻仅有一个CPU核可以写数据,但是其他CPU核是可以读数据的,那么其他核读到的数据可能是CPU1核修改之前的。这就涉及我们提到的改动序列.
2.2 改动序列术语
转载于恋恋风辰
先记住概念,在后续举例过程中会阐述。
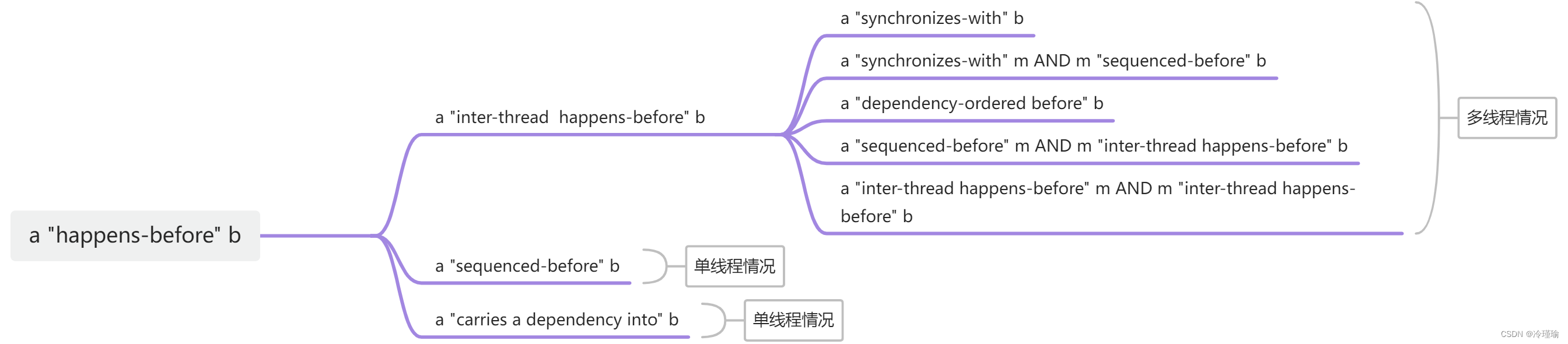

2.2.1 happens-before先行
"A happens-before B" 的意思是如果A操作先于B操作,那么A操作的结果对B操作可见。适用一个线程的两个操作之间, 也可以建立在不同的线程的两个操作之间。先行关系多数情况下描述对同一变量的先后操作,只有变量之间存在依赖关系才会有对不同变量的先后操作存在先行关系
Happens-before仅是C++语义层面的描述,表示 a "Happens-before" b仅能说明a操作的结果对b操作可见。Happens-before不代表指令执行顺序
int Add() {
int a = 0, b = 0;
a++; //1
b++; //2
return a + b; //3
}单线程下:
从C++语义层面,先执行a++,后执行b++, ‘a sequence-before b’.
从计算机指令来讲,可能一条C++语句对于多条计算机指令,会先将b放入寄存器写值+1,而后a写值加1.
但无论指令如何编排,最终由二级缓存写入Memory 的内存顺序一定是a优先于b
2.2.2 sequenced-before顺序先行(单线程)
单线程情况下前面的语句先执行,后面的语句后执行。操作a先于操作b,那么操作b可以看到操作a的结果。我们称操作a顺序先行于操作b。也就是"a sequenced-before b"。
2.2.3 carries dependency依赖(单线程)
单线程情况下a “sequenced-before” b, 且 b 依赖 a 的数据, 则 a “carries a dependency into” b. 称作 a 将依赖关系带给 b, 也理解为b依赖于a。
2.2.4 synchronizes-with同步(多线程)
"A synchronizes-with B" 的意思就是 A和B同步,简单来说如果多线程环境下,有一个线程先修改了变量m,我们将这个操作叫做A,之后有另一个线程读取变量m,我们将这个操作叫做B,那么B一定读取A修改m之后的最新值。也可以称作 A "happens-before" B,即A操作的结果对B操作可见且A的执行顺序在B之前。强调操作之间的执行顺序和可见性
2.2.4 inter-thread-happens-before线程间先行
如果线程 1 中的操作 a “synchronizes-with” 线程 2 中的操作 b, 则操作 a “inter-thread happens-before” 操作 b.
2.2.5 dependency-ordered before依赖(多线程)
线程1执行操作A(比如对i自增),线程2执行操作B(比如根据i访问字符串下表的元素), 如果线程1先于线程2执行,且操作A的结果对操作B可见,但A的执行顺序不一定在B之前,我们将这种叫做 A "dependency-ordered before" B. 强调操作之间的依赖关系和可见性。
2.3 弱比较交换与强比较交换
参数:
a.compare_exchange_weak(x,y,z) :x:要修改的值
y:实际发生修改的值
z:内存顺序,不填写默认是memory_order_seq_cst
使用:当前值a与期望值(x)相等时,修改当前值为设定值(y),返回true
当前值a与期望值(x)不等时,将期望值(x )修改为当前值,返回false
缺点:
可能会在一些不支持硬件级别的原子操作的平台上失败,也可能会由于线程调度等因素而失败,这就是所谓的"伪失败"。(即使预期和实际相等,也会失败)
优点:
如果值计算和存储相对较容易,可以使用compare_exchange_weak来避免双重循环执行。
compare_exchange_strong:与弱比较使用方法一致缺点:
可能会导致线程阻塞(函数内部会尝试多次执行比较和交换操作,直到成功为止)这可能会导致性能损耗
优点:
compare_exchange_strong()更可靠,因为它提供了更强的保证,确保在比较和交换成功时,存储一定会成功。
#include <iostream>
#include <atomic>
#include <thread>
std::atomic<int> value(0); //a
void weak_example() {
int expected = 0; //x
int new_value = 1; //y
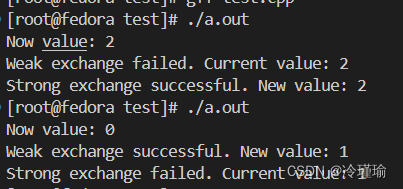
//比较当前值和期望值相等,返回true。将新值写入其中
std::cout << "Now value: " << value.load() << std::endl;
bool success = value.compare_exchange_weak(expected, new_value);
if (success) {
std::cout << "Weak exchange successful. New value: " << value.load() << std::endl;
} else {
std::cout << "Weak exchange failed. Current value: " << value.load() << std::endl;
}
}
void strong_example() {
int expected = 0;
int new_value = 2;
//比较当前值和期望值相等,返回true。将新值写入其中
bool success = value.compare_exchange_strong(expected, new_value);
if (success) {
std::cout << "Strong exchange successful. New value: " << value.load() << std::endl;
} else {
std::cout << "Strong exchange failed. Current value: " << value.load() << std::endl;
}
}
int main() {
std::thread t1(weak_example);
std::thread t2(strong_example);
t1.join();
t2.join();
return 0;
}
2.4 原子操作的内存顺序
Memory Order是用来用来约束同一个线程内的内存访问排序方式
| 内存模型 | 使用解读 | 内存序列选项 | 意义 |
| 排序一致性 | 如果不指定内存序列选项,默认都是该项 | ① memory_order_seq_cst | 提供了最强的内存排序保证。 提供原子操作全局一致性,要求原子操作必须按照程序中出现的顺序执行,不会重新排序。 优点:确保顺序执行 缺点:为全局顺序一致,每次写操作必须同步给其他核心,引入系统开销 |
| 获取-释放序列(非一致) | 用程序对性能有更高的要求,并且可以容忍一定程度的松散的内存排序. | ②memory_order_consume | 确保consume操作读取的值是最新,但是不会像acquire-release构成关系,是一种弱同步内存序i限制(只限制与consume有关原子操作) 由于memory_order_consume在实践中很难正确实现,并且在大多数处理器架构上性能表现不佳,因此在C++20中被取消了 |
| ③ memory_order_acquire | 用于读操作,其确保在读操作之前,所有先前的写操作(使用release)的结果都对当前线程可见。使得编译器对该部分操作不会重排序,而是按照顺序读取。 | ||
| ④ memory_order_release | 确保其余操作在执行release之前完成且对其他线程可见(使用release操作后其余线程读取之前会等待同步cache,确保数据同步) 注意:其他线程可见并不能保证其他线程读取成功!正因为如此才引入consume请参考2.2.4章节 | ||
| ⑤ memory_order_acq_rel | 确保前面的读取操作不会被后续的写入操作重排序,同时也确保后续的读取操作不会被前面的写入操作重排序,但不能强制像release一样保证写入操作的完成顺序 | ||
| 自由序列 (非一致) | 宽松的内存序列,它只保证操作的原子性,并不能保证多个变量之间的顺序性,也不能保证同一个变量在不同线程之间的可见顺序。 | ⑥ memory_order_relaxed | 只关心某个变量是否被修改,不关心修改发生的时间。 优点:提高性能 缺点:不明确执行顺序 场景:多应用于无依赖原子操作、事件通知等 |
2.2.1 memory_order_relaxed
memory_order_relaxed是宽松的内存序列,它只保证操作的原子性,并不能保证多个变量之间的顺序性,也不能保证同一个变量在不同线程之间的可见顺序。
#include <iostream>
#include <thread>
#include <memory>
#include <atomic>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true, std::memory_order_relaxed); // 1
y.store(true, std::memory_order_relaxed); // 2
}
void read_y_then_x()
{
while (!y.load(std::memory_order_relaxed)) { // 3
std::cout << "y load false" << std::endl;
}
if (x.load(std::memory_order_relaxed)) { //4
++z;
}
}
int main()
{
std::thread t1(write_x_then_y);
std::thread t2(read_y_then_x);
t1.join();
t2.join();
assert(z.load() != 0); // 5
} 上面的代码load和store都采用的是memory_order_relaxed。线程t1按次序执行1和2,但是线程t2看到的可能是y为true,x为false。这是由于memory_order_relaxed无法保证x还是y先同步到memory中,进而触发断言z为0.
2.2.2 memory_order_seq_cst
#include <iostream>
#include <thread>
#include <memory>
#include <atomic>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true, std::memory_order_seq_cst); // 1
y.store(true, std::memory_order_seq_cst); // 2
}
void read_y_then_x()
{
while (!y.load(std::memory_order_seq_cst)) { // 3
std::cout << "y load false" << std::endl;
}
if (x.load(std::memory_order_seq_cst)) { //4
++z;
}
}
int main()
{
std::thread t1(write_x_then_y);
std::thread t2(read_y_then_x);
t1.join();
t2.join();
assert(z.load() != 0); // 5
} 如果换成memory_order_seq_cst则能保证所有线程看到的执行顺序是一致的。 所以当线程t2执行到3处并退出循环时我们可以断定y为true,因为是全局一致性顺序,所以线程t1已经执行完2处将y设置为true,那么线程t1也一定执行完1处代码并对t2可见,所以当t2执行至4处时x为true,那么会执行z++保证z不为零,从而不会触发断言。
2.2.3 memory_order_acquire与memory_order_release
获取-释放队列序列
#include <atomic>
#include <thread>
#include <iostream>
#include <cassert>
std::atomic<int> x(0);
std::atomic<bool> ready(false);
void Thread1()
{
x.store(42, std::memory_order_relaxed);
ready.store(true, std::memory_order_release);
}
void Thread2()
{
while (!ready.load(std::memory_order_acquire));
assert(x.load(std::memory_order_relaxed));
}
int main()
{
std::thread t1(Thread1);
std::thread t2(Thread2);
t1.join();
t2.join();
return 0;
}在Thread1函数中,首先将x的值设为42,使用了memory_order_relaxed内存顺序,表示对x的操作不需要特定的内存顺序。然后将ready设为true,使用了memory_order_release内存顺序,表示对ready的操作需要在之后的操作中保持一定的顺序。
在Thread2函数中,通过循环等待ready变为true,使用了memory_order_acquire内存顺序,表示对ready的操作需要在之前的操作中保持一定的顺序。然后通过assert断言来验证x的值是否为非零,使用了memory_order_relaxed内存顺序。
这样通过两个原子变量x和ready来实现线程之间的同步,确保Thread2在Thread1完成写操作之后才能读取x的值。
如果不使用memory_order_acquire,而是单独使用memory_order_release,那么虽然写操作的结果最终会对其他线程可见,但是对于其余原子变量的值,没有一个明确的内存顺序来确保在读操作时能够读取到最新的值。这可能导致其他线程在读取别的原子变量时错过了最近的写操作,从而读取到了过时的值。
多释放-单获取序列:
多个线程对同一个变量release操作,另一个线程对这个变量acquire,那么只有一个线程的release操作喝这个acquire线程构成同步关系。
#include <atomic>
#include <thread>
#include <iostream>
#include <cassert>
int main()
{
std::atomic<int> xd{0}, yd{ 0 };
std::atomic<int> zd;
std::thread t1([&]() {
xd.store(1, std::memory_order_release); // (1)
yd.store(1, std::memory_order_release); // (2)
});
std::thread t2([&]() {
yd.store(2, std::memory_order_release); // (3)
});
t1.join();
t2.join();
std::thread t3([&]() {
while (!yd.load(std::memory_order_acquire)); //(4)
assert(xd.load(std::memory_order_acquire) == 1); // (5)
});
t3.join();
return 0;
}我们可以看到t3在yd为true的时候才会退出,那么导致yd为true的有两种情况,一种是1,另一种是2, 所以5处可能触发断言。

2.2.4 memory_order_consume
release-consume模型是对release-acquire模型的改进,它在保证数据一致性的同时,尝试减少不必要的同步开销,提高程序性能
代码来自于《Concurrency in Action C++》相应章节。
#include <atomic>
#include <cassert>
#include <string>
#include <thread>
struct X {
int i_;
std::string s_;
};
std::atomic<int> a;
std::atomic<X*> p;
void create_x() {
X* x = new X;
x->i_ = 42;
x->s_ = "hello";
a.store(99, std::memory_order_relaxed);
p.store(x, std::memory_order_release);
}
void use_x() {
X* x;
while (!(x = p.load(std::memory_order_consume)));
assert(x->i_ == 42);
assert(x->s_ == "hello");
assert(a.load(std::memory_order_relaxed) == 99);
}
int main() {
std::thread t1(create_x);
std::thread t2(use_x);
t1.join();
t2.join();
return 0;
} p.store和while (!(x = p.load(std::memory_order_consume))) 形成dependence-ordered-before关系,但是 由于std::memory_order_consume具有弱的同步关系,只能保证p原子变量happens-before关系,虽然线程t1的a.store在p.store“强迫”情况下写入CPU,a.store(99, std::memory_order_relaxed)可以被线程t2可见,但是对于consume操作来说,并不能保证对a的写操作能被看到(正因为如此才引入acquire),只能确保p最新值。无法保证a的值为99,故触发断言。
其实说实话在x86下consume和acquire一个样子🤣
2.2.5 memory_order_acq_rel
#include <iostream>
#include <atomic>
#include <thread>
std::atomic<int> data(0);
std::atomic<bool> ready(false);
void producer_consumer() {
// 生产者线程
data.store(42, std::memory_order_acq_rel);
ready.store(true, std::memory_order_acq_rel);
// 消费者线程
while (!ready.load(std::memory_order_acq_rel)) {
std::this_thread::yield();
}
// 读取数据
std::cout << "The answer is " << data.load(std::memory_order_acq_rel) << std::endl;
}
int main() {
std::thread t(producer_consumer);
t.join();
return 0;
}
由于p.store(x, std::memory_order_acq_rel)和a.store(99, std::memory_order_relaxed)之间没有任何同步操作,因此不能保证a的写入操作在p的写入操作之后完成。这可能导致在use_x函数中断言a.load(std::memory_order_relaxed) == 99失败。
三.环形队列
本章节不在赘述,第七章节详细介绍。
四.栅栏操作
栅栏操作(Fence operation)是一种同步原语,用于控制内存访问的顺序和可见性。栅栏操作可以确保在栅栏之前的内存操作在栅栏之后的内存操作之前完成,从而避免了指令重排序和内存可见性问题。
栅栏操作可以分为两种类型:
- 内存屏障(Memory Barrier)用于控制内存操作的顺序和可见性,确保内存操作的顺序性。
- 编译器屏障(Compiler Barrier)用于阻止编译器对指令进行重排序优化,确保指令的执行顺序不被改变。
atomic_thread_fence是一个C++11中的原子操作函数,用于创建一个内存屏障,确保内存操作的顺序性和可见性。它有三种内存顺序选项
memory_order_relaxed:松散的内存顺序,不会对内存操作进行任何排序或同步。memory_order_acquire:确保本线程的读操作不会被后续的写操作重排序。memory_order_release:确保本线程的写操作不会被之前的读操作重排序。
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y_fence()
{
x.store(true, std::memory_order_relaxed); //1
std::atomic_thread_fence(std::memory_order_release); //2
y.store(true, std::memory_order_relaxed); //3
}
void read_y_then_x_fence()
{
while (!y.load(std::memory_order_relaxed)); //4
std::atomic_thread_fence(std::memory_order_acquire); //5
if (x.load(std::memory_order_relaxed)) //6
++z;
}
int main()
{
x = false;
y = false;
z = 0;
std::thread a(write_x_then_y_fence);
std::thread b(read_y_then_x_fence);
a.join();
b.join();
assert(z.load() != 0); //7
}示例比较简单,不在赘述。

















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









