






目录
一、什么是哈希表?
哈希表也叫散列表,哈希表是一种数据结构,它提供了快速的插入操作和查找操作,它的本质就是支持随机查询的数组,即可以根据关键字快速查找值的一种数组,也就是散列表。哈希表实现的关键就是哈希函数,所谓的哈希函数是一种建立查询表的方法,它将key值映射为一种索引号的方法。
二、哈希表有什么缺点?
哈希表是基于数组的,我们知道数组创建后扩容成本比较高,所以当哈希表被填满时,性能下降的比较严重。
三、哈希表在Java中的体现
在Java中哈希表被应用在Map集合的编写中,我们所学的LinkedHashMap,Hashtable,HashMap,在set集合中也有哈希表的体现,如LinkedHashset,Hashset,他们的底层都使用了哈希表。
1、哈希表在Map集合中的体现
Map<K,V>接口:
特点:1.一个元素由K,V两个部分组成
2.K,V可以是任意的引用数据类型
3.K不能重复HashMap:无序。底层的数据结构是哈希表
构造方法:
public HashMap();
LinkedHashMap:有序。底层的数据结构是链表+哈希表
构造方法:
public LinkedHashMap();
2、哈希表在Set集合中的体现
Set接口:
特点:1.没有索引值
2.不能重复HashSet:无序:新增顺序和取出顺序不一定一致
构造方法:
public HashSet();
底层数据结构:哈希表(数组+链表/红黑树)LinkedHashSet:有序
构造方法:
public LinkedHashSet();
底层数据结构:链表+哈希表
3、HashSet底层其实是HashMap
四、为什么Map集合和Set集合存入数据不会重复?
通过上面对于哈希表在Map集合和Set集合中的体现,我们可以发现他们在存入数据的时候,不会重复存入相同的元素,这是为什么呢?我们需要通过底层的源码来弄明白是为什么。
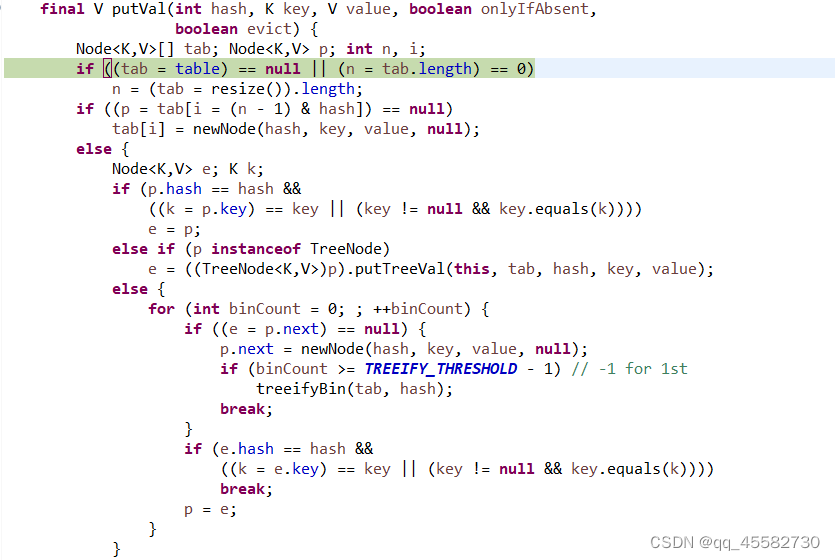
其中我们需要重点关注这一段代码:

它是判断录入元素是否重复的关键,判断该位置的元素和要添加的元素的哈希值是否相同,并且该位置的元素是否地址相同,或者该位置的元素和要添加的元素值是否相同。
五、总结
新增过程:
a.计算新增元素的哈希值
b.(假设数组已经创建出来),通过 hash%数组长度
c.如果该位置为null:则直接新增
如果该位置不为null:
c1.判断该元素是否重复:
c11.如果不重复,则新增到该索引值位置链表的最后面
c12.如果重复:则不新增String覆盖重写了HashCode方法,只要内容相同,哈希值一定相同。
如何判断新增的两个元素是否重复:
比较两个对象的哈希值 && (地址值相同 || equals相同) //规则
六、补充:扩容规则
影响哈希表扩容的因素有两个,本身的容量Capacity和负载因子LoadFactor,当前的哈希表大小大于Size>Threshold=Capacity∗LoadFactor的时候,哈希表就需要扩容。
在JDK1.8之前:哈希表底层实现是数组+链表,在JDK1.8之后:底层实现是数组+链表/红黑树
什么情况下链表会转红黑树:
a.当同一索引值下元素个数>8,并且数组长度>=64
什么情况下会扩容:
a.当同一索引值下元素个数>8,并且数组长度<64
b.数组的索引值,占有>到0.75,会扩容
注意:同一索引值下元素不能超过8个,如果超过
1.扩容,把元素分开,让其小于8个
2.把链表结构转换成红黑树
新容量 = 旧容量<<1;
可以通过构造方法指定加载因子。
可以通过构造方法指定哈希表数组的长度:
实际的长度>=传入容量,则最近2的次方的值。

















 4973
4973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









