







 本文详细介绍了JVM的架构,包括内存区域、类加载子系统和执行引擎。深入探讨了垃圾回收机制,如可达性算法、复制算法、标记清除和标记整理算法。此外,还讲解了JMM(Java内存模型)及其解决的原子性、可见性和有序性问题。最后讨论了JVM内存的初始分配和硬件内存架构的关系。
本文详细介绍了JVM的架构,包括内存区域、类加载子系统和执行引擎。深入探讨了垃圾回收机制,如可达性算法、复制算法、标记清除和标记整理算法。此外,还讲解了JMM(Java内存模型)及其解决的原子性、可见性和有序性问题。最后讨论了JVM内存的初始分配和硬件内存架构的关系。
0 JVM和Java的关系
- JDK = JRE + Java开发工具(java,javac,javadoc,javap…)
- JRE = JVM + Java核心类库
即: JDK = JVM + Java核心类库 + Java开发工具
1 JVM架构(JVM内存区域)
1-1 JVM位置在哪里?
- 硬件——>OS——>JVM
- 即:JVM在操作系统之上。
1-2 JVM架构
- 分三大块:
- Class Loader Subsystem 类加载子系统
- Runtime Data Area 运行时数据区
- Execution Engine 执行引擎
- 画图:
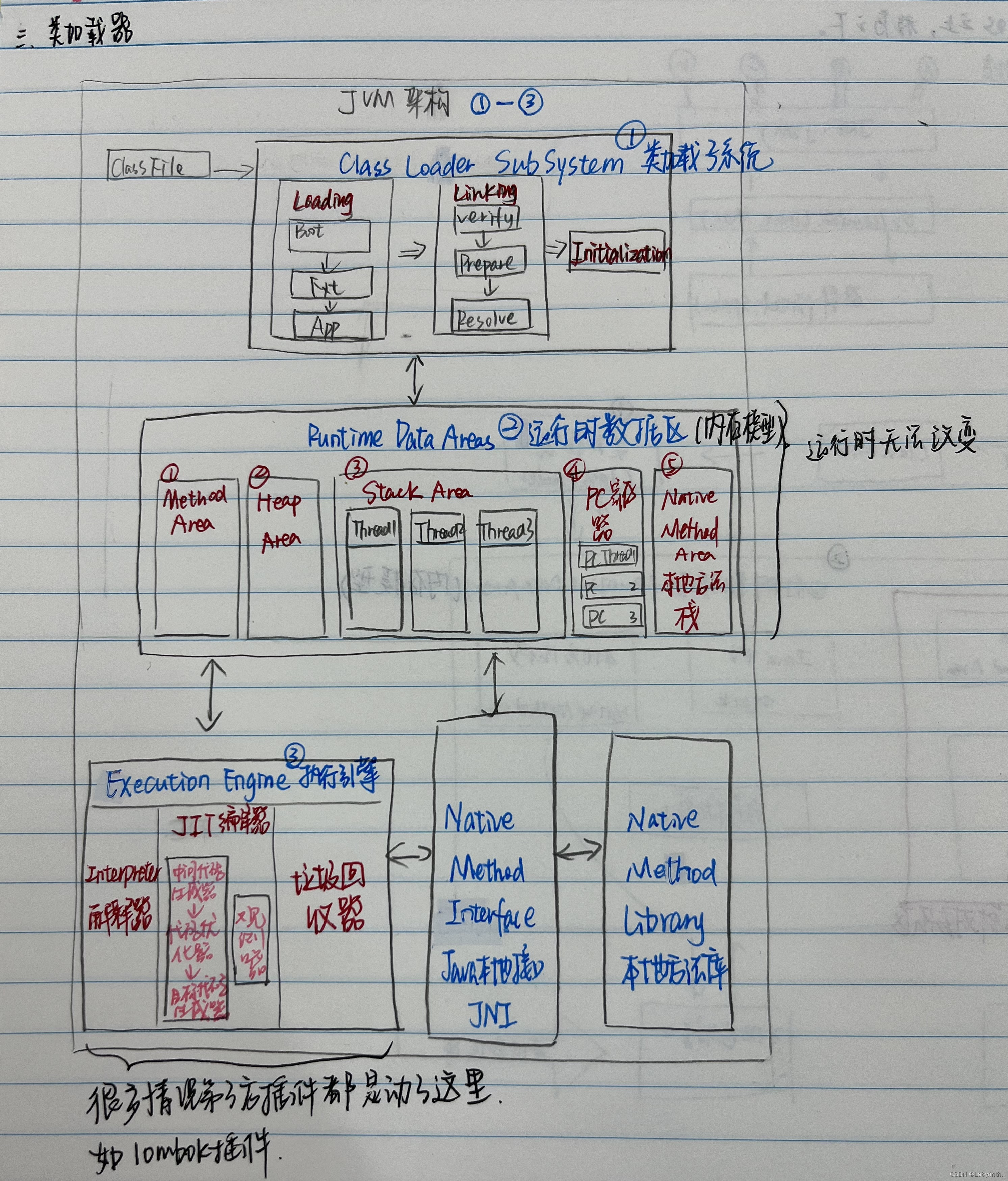
1-3 类加载器
- 位置:在类加载子系统。
- 类加载过程:加载——>链接(验证、准备、解析)——>初始化
- 双亲委派机制:保证类加载和程序的安全。
- 1)类加载器收到类的请求
- 2)将这个请求向上委托给父类,一直向上委托(此时在最老)。(加载器:APP->EXC->BOOT)
- 3)启动加载器检查是否能加载当前类,能就结束,并使用当前加载器;不能就抛异常通知子加载器进行加载
- 4)重复3
- 总结:在继承关系中,最老的类优先选择。
1-4 沙箱安全机制
- 作用:Java安全的核心,限制程序运行环境。
1-5 栈stack
- 特点:先进后出,后进先出。
- 作用:主管程序的运行,生命周期和线程同步。线程结束栈内存就释放,不存在垃圾回收问题。
- 栈存什么?
- 八大基本数据类型
- 对象的引用
- 实例的方法
1-6 方法区
- 特点:被所有线程共享。
- 方法区存什么?
- 所有字段和方法字节码。
- 静态变量,常量,类信息,即时编译器编译后放入的代码。
1-7 PC寄存器
- 每个线程都有一个程序计数器,是线程私有的,就会一个指针(我们接触不到),指向方法区中的方法字节码,在执行引擎读取下,加一。
- 它占用的内容空间几乎忽略不计。
1-8 堆heap(需要垃圾回收)
- 分区:
- 1.8之前:新生区(伊甸园区,幸存区),老年区
- 1.8之后:
- 堆中存什么?
- 对象实例和数组。
2 JVM垃圾回收机制——针对 堆
2-1 如何判断对象是不是垃圾?
2-1-1 引用计数法
- 用计数器记录对象的引用次数,为0的就是垃圾。
- 缺点:难以解决对象之间相互循环引用问题,所以不用。
- PS:现在基本不用了。
2-2-2 可达性算法
- 将GC Roots对象作为起点,从这些节点向下搜索引用的对象,找到对象都标记为非垃圾对象,其余是垃圾对象。
- GC Roots根节点:线程栈的本地变量,静态变量本地方法栈的变量等等。
- 优点:解决了引用计数法的对象之间相互循环引用问题。
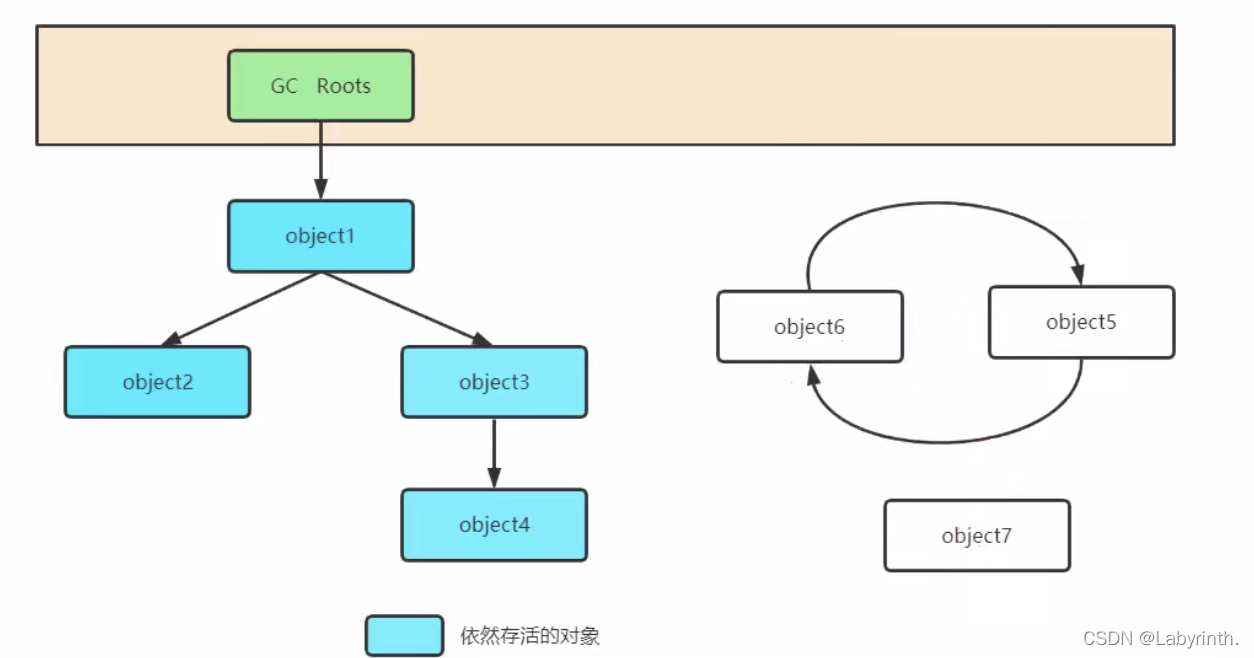
3 垃圾回收算法
3-1 复制算法
- gc时把依然存活的对象复制到两个幸存区之一的to幸存区域(谁空谁是to)。当达到15次(默认)时,认为这个对象有很强的生命力,放到
- 缺点:浪费一个幸存区空间。
- 优点:不产生碎片。
3-2 标记清除算法
- 直接回收垃圾对象,保留存活对象。
- 位置不连续,产生碎片。
3-3 标记整理算法/标记压缩算法
- 回收之后,整理空间。
- 优点:不产生碎片。
- 缺点:效率变低。
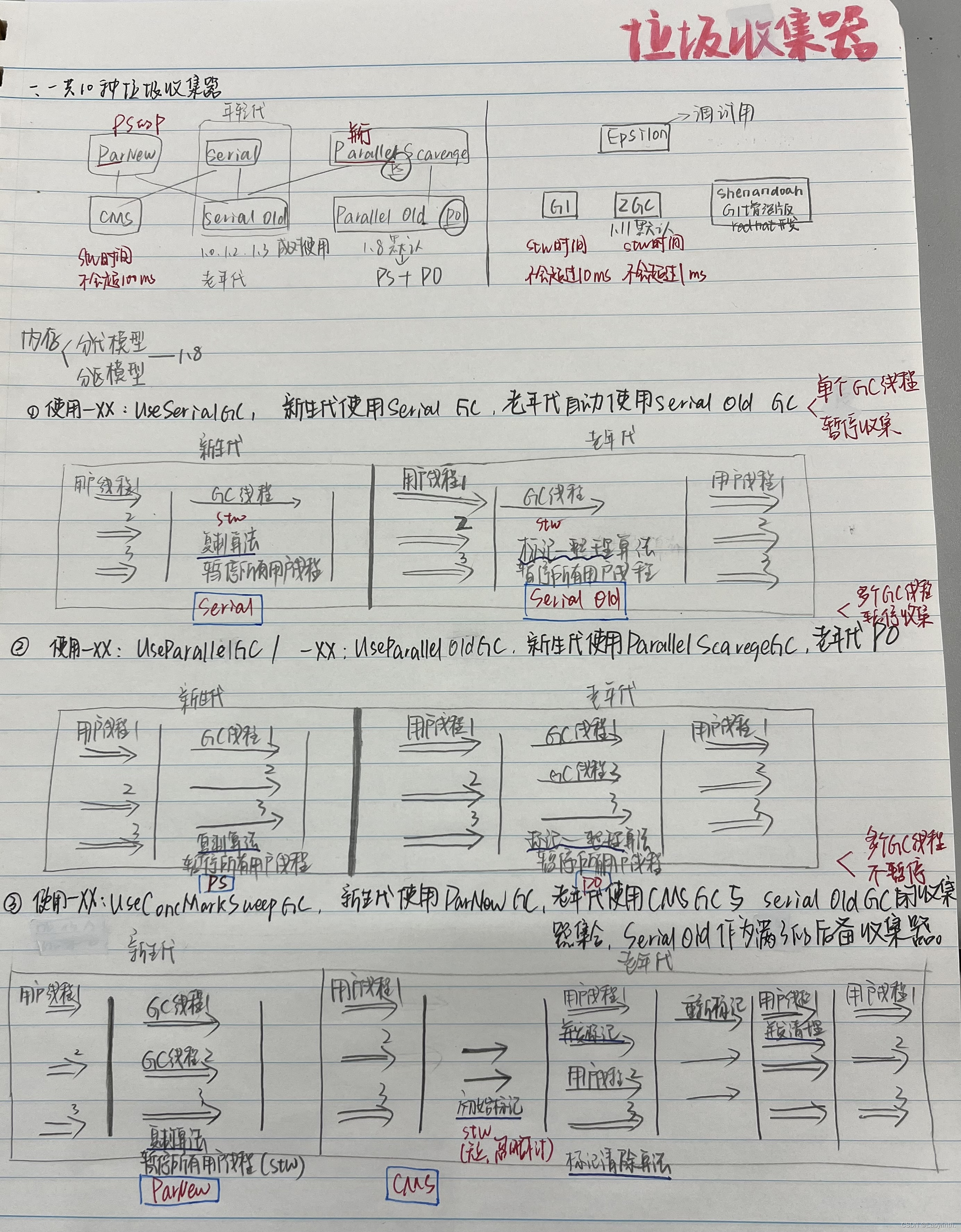
4 垃圾回收器(10种…)
5 JMM(Java内存模型)
- JMM定义了线程工作内存与主内存(线程之间的共享变量)的抽象关系。并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
- JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),用于存储线程私有的数据。Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问。
- 首先要将变量从主内存拷贝的自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,工作内存中存储着主内存中的变量副本拷贝,前面说过,工作内存是每个线程的私有数据区域,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成。
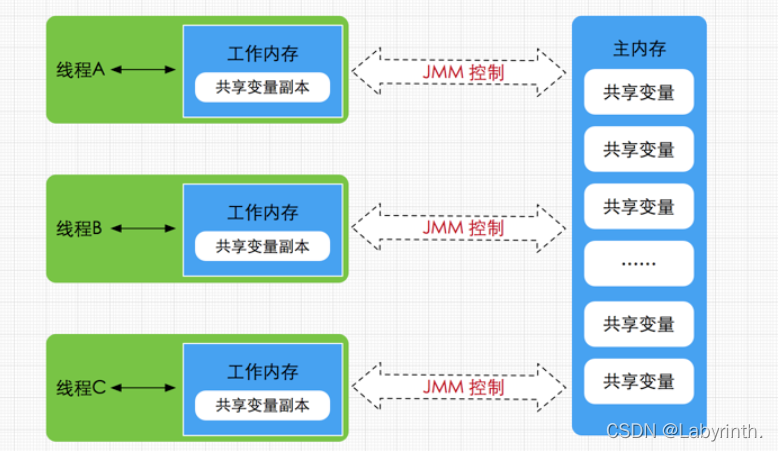
- JMM 与 Java内存区域 唯一相似点,都存在共享数据区域和私有数据区域:
- 在JMM中主内存属于共享数据区域,从某个程度上讲应该包括了堆和方法区;而工作内存数据线程私有数据区域,从某个程度上讲则应该包括程序计数器、虚拟机栈以及本地方法栈。
- 此处为什么包括本地方法栈?本地方法栈中的本地方法是怎么被线程调用的?:Java虚拟机栈用于管理Java方法的调用,而本地方法栈用于管理本地方法的调用。本地方法栈,也是线程私有的。如果线程请求分配的栈容量超过本地方法栈允许的最大容量,Java虚拟机将会抛出一个 StackOverflowError 异常。如果本地方法栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时没有足够的内存去创建对应的本地方法栈,那么Java虚拟机将会抛出一个 OutOfMemoryError 异常。本地方法栈是线程私有就是因为 只有线程调用时,线程的本地方法栈才会登记本地方法。
- 它的具体做法是Native Method Stack中登记native方法,在Execution Engine 执行时加载本地方法库。
- 当某个线程调用一个本地方法时,它就进入了一个全新的并且不再受虚拟机限制的世界。它和虚拟机拥有同样的权限。
- 本地方法可以通过本地方法接口来访问虚拟机内部的运行时数据区。
- 它甚至可以直接使用本地处理器中的寄存器。
- 直接从本地内存的堆中分配任意数量的内存。
- 或许在某些地方,我们可能会看见主内存被描述为堆内存,工作内存被称为线程栈,实际上他们表达的都是同一个含义。
个人理解:JMM只是用线程角度思考JVM;JVM架构(JVM内存区域)就是从物理角度。
- 在JMM中主内存属于共享数据区域,从某个程度上讲应该包括了堆和方法区;而工作内存数据线程私有数据区域,从某个程度上讲则应该包括程序计数器、虚拟机栈以及本地方法栈。
- 关于JMM中的主内存和工作内存说明如下:
- 主内存 存什么?:主要存储的是Java所有线程创建的实例对象(不管这个实例对象是成员变量还是方法中的本地变量(也叫局部变量)),当然也包括了类信息、常量、静态变量。
- 工作内存 存什么?:主要存储当前方法的所有本地变量信息(针对本线程说)(主内存中变量的拷贝副本),每个线程这能访问自己的工作内存(即线程中的本地变量对其他线程是不可见的,就算是两个线程执行同一段代码,他们也会各自在自己的工作内存中胡藏剑属于当前线程的本地变量,当然也包括了字节码行号指示器,相关Native方法的信息),由于工作内存是每个线程的私有数据,线程间无法相互访问工作内存,因此存储在工作内存的数据不存在线程安全问题。
- 作用:缓存一致性协议,用于定义数据读写的规则。
- 主内存与工作内存的数据存储类型以及操作方式:
- 对于一个实例对象中的成员方法而言,
- 如果方法中包含本地变量(局部变量)是基本数据类型(boolean,byte,short,char,int,long,float,double),将直接存储在工作内存的帧栈结构中,但倘若本地变量(局部变量)是引用类型,那么该变量的引用会存储在功能内存的帧栈中,而对象实例(在这个方法中新建的对象实例)将存储在主内存(共享数据区域,堆)中。
- 但对于实例对象的成员变量而言,
- 不管它是基本数据类型或者包装类型(Integer、Double等)还是引
- 对于一个实例对象中的成员方法而言,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









