






一、实验步骤
1)导入需要用到的库
importpandasaspd
importmatplotlib.pyplotasplt
2)从电脑读取文件
dataDF=pd.ExcelFile("C:\\Users\\dell、\\Desktop\\药品销售情况.xlsx")
dataDF=dataDF.parse("Sheet1")
3)”购药时间“改为”销售时间“
changeName={"购药时间":"销售时间"}
dataDF.rename(columns=changeName,inplace=True)
4)删除空白行
dataDF=dataDF.dropna(axis=0,subset=["销售时间","商品名称"])
5)销售时间分割
defsplitTimeOperate(timeseries):
time_list=[]
forvalueintimeseries:
data=value.split('')[0]
time_list.append(data)
TimeSer=pd.Series(time_list)
returnTimeSer
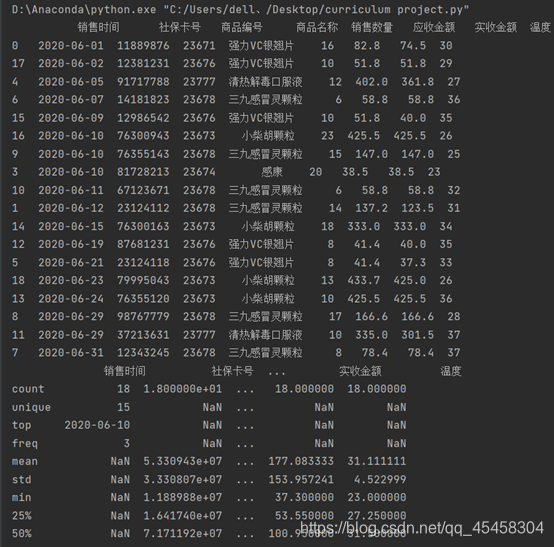
6)提取有效数据并按销售时间升序排列
query=dataDF.loc[:,"销售数量"]>=0
dataDF=dataDF.loc[query,:]
dataDF=dataDF.sort_values(by='销售时间',ascending=True,na_position="first")
print(dataDF)
salesData=dataDF["销售时间"]
dataDF["销售时间"]=splitTimeOperate(salesData)
dataDF=dataDF.dropna(axis=0,subset=["销售时间","商品名称"])
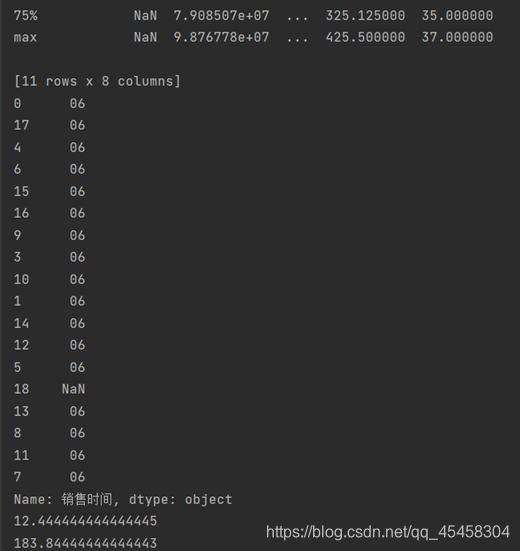
7)描述信息
Desc=dataDF.describe(include='all')
print(Desc)
8)获取月份,月平均销售次数
defsplitMonthOperate(timeseries):
time_list=[]
forvalueintimeseries:
data=value.split('-')[1]
time_list.append(data)
MonthSer=pd.Series(time_list)
returnMonthSer
MonthsData=dataDF["销售时间"]
dataDF["销售时间"]=splitMonthOperate(MonthsData)
Num=dataDF["销售时间"]
print(Num)
Avg_num=dataDF['销售数量'].mean()
print(Avg_num)
Avg_money=dataDF['应收金额'].mean()
print(Avg_money)
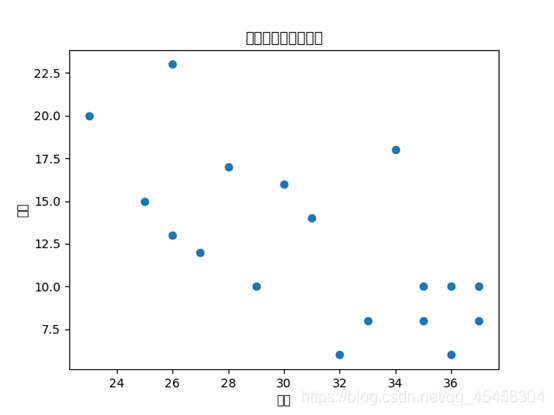
9)绘制散点图
温度=dataDF['温度']
销售量=dataDF['销售数量']
#设置x,y轴的取值范围
plt.scatter(温度,销售量)
#标签
plt.title('温度与销售量的关系')
plt.xlabel("温度")
plt.ylabel("销量")
plt.show()
二、运行截图
三、实验心得
pandas是一个基于numpy的功能非常强大的数据分析工具,主要提供了dataframe和series两种数据类型。通过本次实验,我开始上手并且熟悉pandas,更加认识到了pandas和python的强大,本次实验只是使用了pandas功能中的很小的一部分,要想运用好pandas来做数据分析还有一段路要走。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









