




内存泄漏和内存溢出的区别
对比项 内存泄漏(Memory Leak) 内存溢出(Memory Overflow) 本质 对象无法被回收,资源浪费 内存不足,无法分配新对象 表现 内存使用缓慢增长 程序崩溃,抛出 OutOfMemoryError原因 无用的强引用、资源未关闭等 内存泄漏、配置过小、需求过大等 关系 可能导致内存溢出 是内存泄漏的可能结果之一 内存泄漏指的是程序中已经不再使用的对象,由于某些原因无法被垃圾回收器(GC)回收,导致这些对象一直占用内存,造成内存资源的浪费。
- 核心问题:对象本该被回收,但由于存在“无用”的强引用,导致无法回收。内存使用量会缓慢、持续地增长。
常见原因:
- 静态集合类持有对象引用
public class MemoryLeakExample { private static List<Object> cache = new ArrayList<>(); public void addToCache(Object obj) { cache.add(obj); // 如果不清除,对象永远不会被回收 } }
未正确移除监听器或回调。GUI编程中,监听器注册后未注销。
内部类持有外部类引用。非静态内部类会隐式持有外部类的引用,可能导致外部类无法被回收。
WeakHashMap 使用不当。如果用强引用作为 key,即使 WeakHashMap 的 key 是弱引用,也无法被回收。
资源未关闭(如IO流、数据库连接)。虽然不直接导致Java对象泄漏,但会占用本地资源。
内存溢出是指JVM在尝试分配内存时,堆内存或其它内存区域(如元空间)已满,且无法通过垃圾回收释放足够空间,最终抛出
java.lang.OutOfMemoryError错误。核心问题:内存需求 > 可用内存。JVM无法继续分配新对象或执行操作。
错误信息 含义 可能原因 OutOfMemoryError: Java heap space堆内存溢出 - 内存泄漏
- 堆内存设置过小(-Xmx)
- 程序需要处理大量数据OutOfMemoryError: Metaspace元空间溢出 - 加载了过多的类(如动态生成类、反射)
- 元空间大小设置过小OutOfMemoryError: GC Overhead limit exceededGC开销过大 - 堆内存几乎耗尽,GC频繁但回收效果差(通常是内存泄漏的征兆) OutOfMemoryError: unable to create new native thread无法创建新线程 - 线程数过多
- 系统内存不足
如何应对内存泄漏和内存溢出?
问题 解决方法 内存泄漏 - 使用内存分析工具定位泄漏源
- 检查集合类、监听器、内部类等
- 使用弱引用(WeakReference)、软引用(SoftReference)
- 及时关闭资源(try-with-resources)内存溢出 - 增加堆内存( -Xmx)
- 优化代码,减少内存占用
- 检查是否存在内存泄漏
- 调整元空间大小(-XX:MaxMetaspaceSize)
- 优化数据处理逻辑(如分页、流式处理)
java引用类型有哪些?有什么区别?
强引用(Strong Reference)
- 定义:最常见的引用类型,通过关键字
new创建的对象赋值给变量时即建立了强引用。- 特点:只要强引用存在,垃圾回收器就永远不会回收被引用的对象。当内存不足时,JVM宁愿抛出
OutOfMemoryError错误,也不会回收强引用对象。软引用(Soft Reference)
- 定义:通过
SoftReference类实现,用于创建软引用对象。- 特点:
- 当内存充足时,软引用对象不会被垃圾回收。
- 当内存不足时,垃圾回收器会回收软引用对象。
- 常用于实现内存敏感的缓存,可以在内存紧张时自动释放部分缓存数据。
弱引用(Weak Reference)
- 定义:通过
WeakReference类实现,用于创建弱引用对象。- 特点:
- 无论内存是否充足,只要弱引用对象是垃圾回收器扫描到的唯一引用,就会被回收。
- 常用于避免内存泄漏,例如在
WeakHashMap中,键使用弱引用,当键对象不再被其他强引用引用时,可以被自动删除。虚引用(Phantom Reference)
- 定义:通过
PhantomReference类实现,必须配合引用队列(ReferenceQueue)使用。- 特点:
- 虚引用对对象生命周期没有任何影响,不能通过虚引用获取对象实例。
- 主要用于跟踪对象被垃圾回收的活动,当对象被垃圾回收时,虚引用会被加入到关联的引用队列中,可以在队列中检测到对象已被回收的信号。
软引用和弱引用的区别,和各自的应用场景
特性 软引用 (SoftReference) 弱引用 (WeakReference) 回收时机 内存不足时才被回收(在 OutOfMemoryError之前)。下一次垃圾回收时就会被回收,无论内存是否充足。 强度 比弱引用强,比强引用弱。 比软引用更弱。 是否影响生命周期 不影响,但延迟回收。 不影响,立即可回收。 典型用途 内存敏感的缓存。 自动清理的映射、避免内存泄漏。 软引用的应用场景
- 内存缓存(Memory-sensitive Caching)
- 适用于缓存大量数据(如图片、文件内容),当内存充足时保留,内存不足时自动释放。
- 示例:一个图片加载器缓存缩略图。
弱引用的应用场景
- WeakHashMap —— 自动清理的映射
WeakHashMap的键(key) 是弱引用。- 当外部不再引用某个 key 时,该 key-value 对会自动从 map 中移除。
- 适合做与对象生命周期绑定的元数据存储。
避免内存泄漏
- 在观察者模式或监听器机制中,如果监听器持有被监听对象的引用,可能导致对象无法释放。
- 使用弱引用可以避免这种“悬挂引用”。
临时跟踪对象生命周期
- 结合
ReferenceQueue,可以监听对象何时被回收,用于资源清理或日志记录。
堆分为哪几部分呢?
堆的划分方式也有所不同,主要分为经典分代模型和现代G1等新型垃圾收集器模型。
经典分代模型(适用于Serial, Parallel, CMS等收集器)
新创建的对象首先被分配在此区域。新生代又进一步细分为三个区:
1. 新生代(Young Generation)
- Eden区:绝大多数新对象都会被分配到Eden区。当Eden区空间不足时,会触发一次Minor GC(年轻代GC),对新生代进行垃圾回收。
- Survivor区(From区和To区):两个大小相等、角色互换的区域。在Minor GC后,仍然存活的对象会被移动到其中一个Survivor区(From区)。经过多次GC后依然存活的对象,最终会被晋升到老年代。每次GC后,From和To的角色会交换。
2. 老年代(Old Generation / Tenured Generation)
- 存放从新生代中经过多次GC后仍然存活下来的“长寿”对象。
- 当对象过大(超过一定阈值)时,也可能直接分配到老年代(避免在新生代频繁复制大对象)。
- 老年代的空间通常比新生代大得多。
- 当老年代空间不足时,会触发Full GC或Major GC(老年代GC),这类GC通常耗时较长。
3. 永久代(Permanent Generation) - 已废弃
- 在JDK 8之前,永久代用于存放类的元数据信息(如类名、方法信息、常量池等)、静态变量和即时编译后的代码。
- 注意:从JDK 8开始,永久代被元空间(Metaspace) 取代,元空间使用本地内存(Native Memory),不再属于堆的一部分。
现代模型(以G1收集器为例)
G1(Garbage-First)收集器改变了传统的分代模型,它将整个堆划分为多个大小相等的Region(区域),每个Region可以是以下类型之一:
- E(Eden):对应传统Eden区的Region。
- S(Survivor):对应传统Survivor区的Region。
- O(Old):对应老年代的Region。
- H(Humongous):专门用于存储巨型对象(大小超过一个Region一半的对象)。
- Free:空闲的Region。
G1通过这种化整为零的方式,可以更灵活地进行垃圾回收,优先回收垃圾最多的Region,从而实现可预测的停顿时间。
方法区中有哪些东西?
方法区(Method Area)是JVM中一个重要的内存区域,用于存储已被虚拟机加载的类型信息。
内容 示例 类/接口的结构信息 类名、父类、字段、方法声明 运行时常量池 字符串常量、符号引用 静态变量 static int count;JIT编译后的代码 热点方法的本地机器码 反射相关数据 Class对象、方法表方法区主要存储以下内容:
1. 类的元数据(Class Metadata)
这是方法区最核心的内容,包括:
- 类的全限定名(Fully Qualified Name)
- 父类的全限定名
- 类的访问修饰符(如
public、final、abstract等)- 接口列表:该类实现的接口
- 字段信息:包括字段名称、类型、访问修饰符(
public、private等)、是否为静态(static)、是否为常量(final)等。- 方法信息:包括方法名称、返回类型、参数列表、访问修饰符、异常表等。
- 方法字节码:方法对应的Java字节码指令(
.class文件中的Code属性)。2. 运行时常量池(Runtime Constant Pool)
- 每个类或接口都有一个运行时常量池,它是类文件常量池的运行时表示。
- 存储编译期生成的各种字面量(Literal)和符号引用(Symbolic References),例如:
- 字符串常量(如
"Hello")- 基本类型的常量值(如
final int a = 100;)- 类和接口的全限定名
- 字段和方法的名称与描述符
- 在运行期间,这些符号引用会被解析为直接引用(如指向对象的指针),以支持动态链接。
3. 静态变量(Static Variables / Class Variables)
- 被
static修饰的变量,也称为类变量。- 这些变量属于类本身,而不是类的实例,因此存储在方法区中。
- 注意:虽然静态变量本身存储在方法区,但如果它是引用类型(如
static Object obj = new Object();),那么obj引用存储在方法区,而它指向的Object实例仍然存储在堆中。4. 即时编译器编译后的代码(JIT Code)
- JVM的即时编译器(Just-In-Time Compiler, JIT)会将热点代码(频繁执行的方法)从字节码编译成本地机器码。
- 这些编译后的本地代码也会被缓存到方法区中,以便后续直接执行,提高性能。
5. 其他运行时数据
- 域信息:与反射相关的数据,如
java.lang.Class对象。- 方法表:用于支持动态分派(方法重写),存储虚方法的地址,便于快速查找。
字符串常量池是在堆中吗
是的,从JDK 7开始,字符串常量池(String Table)被移到了堆(Heap)中。
- JDK 7 之前:字符串常量池在方法区(永久代)。
- JDK 7 及以后:字符串常量池被移到了堆(Heap)。
为什么移到堆中?
- 减少永久代压力:在JDK 6及之前,大量使用
String.intern()或加载大量字符串(如解析XML、JSON)容易导致永久代溢出。将其移到堆中,可以利用堆更大的内存空间和更成熟的垃圾回收机制。- 统一内存管理:堆是JVM管理对象的主要区域,字符串作为对象的一种,将其常量池放在堆中更符合逻辑。
- 提高灵活性:堆的大小通常比永久代大得多,且可以通过
-Xmx等参数灵活调整,减少了因字符串过多导致的内存溢出问题。
如果有个大对象一般是在哪个区域?
- 小对象:通常先分配在新生代的 Eden区。
- 大对象:为了避免在新生代频繁复制(影响性能),JVM会直接分配到老年代(Old Generation)。
为什么大对象直接进老年代? 新生代的GC(Minor GC)采用复制算法,需要将存活对象从Eden复制到Survivor区。如果一个大对象在每次GC时都要复制,开销非常大。因此,JVM倾向于让大对象“绕过”新生代,直接进入老年代。
垃圾回收
什么是Java里的垃圾回收?
垃圾回收(Garbage Collection, GC) 是Java虚拟机(JVM)自动管理内存的一种机制,其主要目的是:自动识别并回收不再使用的对象,释放内存空间,防止内存泄漏和内存溢出。
垃圾回收的基本原理
可达性分析(Reachability Analysis): JVM通过一系列称为“GC Roots”的对象(如正在执行的方法中的局部变量、静态变量、JNI引用等)作为起点,向下搜索对象引用链。
- 可达对象:能从GC Roots直接或间接访问到的对象,不会被回收。
- 不可达对象:无法从GC Roots访问到的对象,可以被回收。
回收过程:
- 标记:找出所有不可达对象。
- 清除/整理:释放这些对象占用的内存,可能还会进行内存整理(如压缩)以减少碎片。
如何触发垃圾回收?
在Java中,不能强制JVM立即执行垃圾回收,但可以通过以下方式建议JVM进行回收。
1. 自动触发(主要方式)
GC 类型 触发条件 Minor GC(年轻代GC) 当新生代(Eden区)空间不足时触发。 Major GC / Full GC(老年代/完全GC) - 老年代空间不足
- 方法区(元空间)空间不足
- 调用System.gc()(建议)
- Minor GC时发现老年代可能放不下晋升的对象2. 手动建议触发
Java提供了方法来“建议”JVM执行GC,但不保证立即执行。
// 建议JVM执行垃圾回收 System.gc(); // 或使用 Runtime Runtime.getRuntime().gc();
- 调用
System.gc()只是建议,JVM可以忽略。- 频繁调用会影响性能,不推荐在生产环境中使用。
- 可通过
-XX:+DisableExplicitGC参数禁用System.gc()。
| 问题 | 回答 |
|---|---|
| 什么是垃圾回收? | JVM自动回收不再使用的对象,释放内存。 |
| 如何触发? | 主要由JVM自动触发(如新生代满);可通过 System.gc() 建议触发,但不保证执行。 |
| 能否强制回收? | 不能。Java不提供强制GC的机制。 |
| 最佳实践 | 依赖JVM自动管理,合理设计对象生命周期,避免内存泄漏,通过JVM参数调优GC性能。 |
判断垃圾的方法有哪些?
引用计数算法:
- 给每个对象维护一个引用计数器。
- 每当有一个地方引用该对象时,计数器加1。
- 当引用失效时,计数器减1。
- 当计数器为0时,表示该对象不再被任何地方引用,可以被回收。
- 引用计数无法解决循环引用的问题。
可达性算法: 这是当前Java虚拟机(如HotSpot)实际使用的垃圾判断算法。
这种方式是在内存中,从根对象向下一直找引用,找到的对象就不是垃圾,没找到的对象就是垃圾。
垃圾回收算法是什么,是为了解决了什么问题?
JVM有垃圾回收机制的原因是为了解决内存管理的问题。
垃圾回收机制的主要目标是自动检测和回收不再使用的对象,从而释放它们所占用的内存空间。这样可以避免内存泄漏(一些对象被分配了内存却无法被释放,导致内存资源的浪费)。
通过垃圾回收机制,JVM可以在程序运行时自动识别和清理不再使用的对象,使得开发人员无需手动管理内存。这样可以提高开发效率、减少错误,并且使程序更加可靠和稳定。
JVM有哪些垃圾回收算法?
标记清除算法:
- a标记阶段:把垃圾内存标记出来
- b清除阶段:直接将垃圾内存回收。
- c这种算法是比较简单的,但是有个很严重的问题,就是会产生大量的内存碎片。
适用场景:CMS(Concurrent Mark-Sweep)收集器的老年代回收阶段。
复制算法:为了解决标记清除算法的内存碎片问题,就产生了复制算法。
- 复制算法将内存分为大小相等的两半,每次只使用其中一半。
- 垃圾回收时,将当前这一块的存活对象全部拷贝到另一半,然后当前这一半内存就可以直接清除。
- 这种算法没有内存碎片,但是他的问题就在于浪费空间。而且,他的效率跟存活对象的个数有关。
适用场景:新生代(Young Generation)的Minor GC,如Serial、Parallel、G1收集器的年轻代回收。
- 不适合老年代:老年代对象存活率高,复制开销大。
标记压缩算法:这种算法在标记阶段跟标记清除算法是一样的,但是在完成标记之后,不是直接清理垃圾内存,而是将存活对象往一端移动,然后将边界以外的所有内存直接清除。
- 标记(Mark):同标记-清除,标记所有存活对象。
- 整理(Compact):将所有存活对象向内存的一端移动,然后清理边界以外的内存。
优点:无碎片:整理后内存连续,利于大对象分配。不浪费内存:不像复制算法需要双倍空间。
缺点:效率较低:移动对象需要时间,且需要更新所有引用指针。
适用场景:老年代(Old Generation)的Major GC,如Serial Old、Parallel Old、CMS(备用方案)。
分代收集算法(Generational Collection):这不是一种独立的算法,而是现代JVM采用的综合策略,它结合了上述多种算法,根据对象的生命周期将堆分为新生代和老年代,并采用不同的回收策略:
代 特点 使用的算法 GC类型 新生代 对象存活率低,创建和死亡频繁 复制算法 Minor GC 老年代 对象存活率高,生命周期长 标记-清除 或 标记-整理 Major GC / Full GC 代收集是将内存划分成了新生代和老年代。分配的依据是对象的生存周期,或者说经历过的 GC 次数。对象创建时,一般在新生代申请内存,当经历一次 GC 之后如果对还存活,那么对象的年龄 +1。当年龄超过一定值(默认是 15,可以通过参数 -XX:MaxTenuringThreshold 来设定)后,如果对象还存活,那么该对象会进入老年代。
算法 核心思想 优点 缺点 典型应用 标记-清除 标记后直接清除 简单 产生碎片 CMS老年代 复制 存活对象复制到新区 无碎片、高效 浪费空间 新生代GC 标记-整理 存活对象向一端移动 无碎片、不浪费空间 移动开销大 老年代GC 分代收集 按生命周期分代处理 综合高效 实现复杂 现代JVM主流
minorGC、majorGC、fullGC的区别
. Minor GC(年轻代GC)
- 回收区域:只针对新生代,包括Eden区和两个Survivor区(From和To)。
- 触发时机:当Eden区空间不足,无法为新对象分配内存时就会触发。
- 特点:
- 非常频繁,因为大多数对象都是“朝生夕死”的短期对象。
- 速度快,通常在几毫秒内完成。
- 使用复制算法,将存活的对象从Eden复制到Survivor区。
- 属于Stop-The-World事件,但停顿时间很短,对应用影响较小。
✅ 简单说:Minor GC是“小扫除”,清理新生代的垃圾,发生频繁但很快。
Major GC(老年代GC)
- 回收区域:主要针对老年代。
- 触发时机:
- 老年代空间不足。
- Minor GC后有对象需要晋升到老年代,但老年代空间不够。
- 特点:
- 频率低于Minor GC。
- 速度较慢,因为老年代更大,且对象存活率高。
- 通常使用标记-清除或标记-整理算法。
- 停顿时间较长,可能影响应用响应。
🔔 注意:Major GC有时会伴随Minor GC一起发生,但不是绝对的。
Full GC(完全GC)
- 回收区域:整个堆内存(新生代 + 老年代)以及方法区/元空间(Metaspace)。
- 触发时机:
- 显式调用
System.gc()(建议JVM执行)。- 老年代或元空间空间不足。
- Minor GC后晋升失败(担保失败)。
- CMS收集器出现“并发模式失败”。
- 特点:
- 范围最大,影响最广。
- 停顿时间最长,可能导致应用“卡顿”甚至超时。
- 是一次全局性的Stop-The-World事件。
- Full GC会包含Minor GC和Major GC。
⚠️ 频繁的Full GC通常是性能问题的信号,比如内存泄漏或JVM参数配置不合理。
类型 回收区域 频率 停顿时间 是否包含其他GC Minor GC 新生代 高 短 否 Major GC 老年代 中 中 有时伴随Minor GC Full GC 整个堆 + 元空间 低 长 包含Minor和Major GC
垃圾回收器有哪些?
回收器 适用代 线程模型 目标 适用场景 JDK默认 Serial 新生代/老年代 单线程 简单高效 客户端、小内存 ❌ Parallel 新生代/老年代 多线程 高吞吐量 后台计算、批处理 JDK 8 默认 CMS 老年代 并发 低停顿 Web服务器(已废弃) ❌ G1 整个堆 并发+并行 可控停顿、大堆 通用服务器 JDK 9+ 默认 ZGC 整个堆 并发 <10ms停顿 超大堆、低延迟 ❌ Shenandoah 整个堆 并发 低延迟 低延迟应用 ❌ 随着JVM的发展,出现了多种不同的垃圾回收器,它们在吞吐量、停顿时间、适用场景等方面各有侧重。
经典/早期回收器(适用于小内存、单核CPU)
1. Serial 收集器
- 新生代:使用 复制算法
- 老年代:使用 标记-整理算法
- 特点:
- 单线程执行,GC时会 Stop-The-World。
- 简单高效,适合客户端应用(如桌面程序)。
- 使用参数:
-XX:+UseSerialGC2. Parallel(并行)收集器(吞吐量优先)
- 新生代:Parallel Scavenge,使用复制算法
- 老年代:Parallel Old,使用标记-整理算法
- 特点:
- 多线程并行执行,充分利用多核CPU。
- 目标是最大化吞吐量(
吞吐量 = 用户代码运行时间 / (用户代码时间 + GC时间))。- 适合后台计算、批处理等对延迟不敏感的场景。
- 使用参数:
-XX:+UseParallelGC并发低延迟回收器
3. CMS(Concurrent Mark-Sweep)收集器(已废弃)
- 老年代专用,新生代仍用ParNew或Serial。
- 算法:标记-清除(会产生碎片)。
- 特点:
- 以最短停顿时间为目标。
- 大部分阶段与用户线程并发执行(如并发标记、并发清除)。
- 缺点:
- 会产生内存碎片,可能导致“并发模式失败”而触发Full GC。
- CPU资源占用高。
- 在JDK 14中被标记为废弃,JDK 17+已移除。
- 使用参数:
-XX:+UseConcMarkSweepGC现代回收器(适用于大内存、多核服务器)
4. G1(Garbage-First)收集器(JDK 9+ 默认)
- 适用范围:整个堆(不分新生代/老年代,而是划分为多个Region)。
- 特点:
- 面向大堆内存(>4GB)设计。
- 将堆划分为多个大小相等的 Region。
- 可预测的停顿时间模型:通过
-XX:MaxGCPauseMillis设置最大停顿时间目标。- 回收时优先选择垃圾最多的Region(Garbage-First)。
- 支持并发标记和部分并发清理。
- 使用 标记-整理 算法,避免碎片。
- JDK 9 及以后版本的默认GC。
- 使用参数:
-XX:+UseG1GC5. ZGC(Z Garbage Collector)(JDK 11+,生产可用 JDK 15+)
- 目标:实现极低停顿(<10ms),且停顿时间不随堆大小增长。
- 特点:
- 支持超大堆(TB级)。
- 大部分工作(标记、转移)与用户线程并发执行。
- 使用着色指针(Colored Pointers) 和 读屏障(Load Barriers) 技术。
- 停顿时间几乎恒定,适合对延迟极度敏感的系统(如金融交易)。
- 使用参数:
-XX:+UseZGC6. Shenandoah GC(JDK 12+)
- 与ZGC类似,目标也是低延迟、短停顿。
- 使用 Brooks Pointer 技术实现并发压缩。
- 停顿时间也非常短,与堆大小无关。
- 使用参数:
-XX:+UseShenandoahGC
什么是 Stop The World?
Stop-The-World(STW) 是指在垃圾回收过程中,JVM暂停所有应用线程(用户线程)的执行,只保留必要的GC线程进行垃圾回收操作。
核心特点:
- 全局暂停:所有正在运行的Java线程都会被冻结,应用程序暂时“卡住”。
- GC专用时间:在此期间,只有GC线程在工作,确保堆内存状态一致,避免在回收过程中对象引用关系发生变化。
- 影响用户体验:STW的时间长短直接影响应用的延迟(Latency)和响应性。停顿时间越长,用户体验越差(如Web请求超时、界面卡顿)。
垃圾回收算法哪些阶段会stop the world?
不同的垃圾回收算法和阶段,其STW的频率和持续时间不同。
1. Serial / Parallel 收集器
- Minor GC(新生代):
- 发生 STW。
- 使用复制算法,需要暂停所有应用线程以确保Eden区对象状态一致。
- Major GC / Full GC(老年代):
- 发生 STW。
- 使用标记-整理或标记-清除,整个过程完全暂停应用。
⚠️ 特点:简单高效,但停顿时间较长,适合吞吐量优先的场景。
2. CMS(Concurrent Mark-Sweep)收集器(已废弃)
- 初始标记(Initial Mark):
- ✅ 发生 STW(短暂)。
- 仅标记从GC Roots直接可达的对象。
- 并发标记(Concurrent Mark):
- ❌ 不发生 STW。
- 和应用线程并发执行。
- 重新标记(Remark):
- ✅ 发生 STW(比初始标记长)。
- 修正并发标记期间因对象变化导致的标记误差。
- 并发清除(Concurrent Sweep):
- ❌ 不发生 STW。
✅ 目标:减少停顿时间,适合低延迟应用(如Web服务器)。
3. G1(Garbage-First)收集器
- 年轻代GC(Young GC):
- ✅ 发生 STW。
- 类似Parallel,暂停应用线程回收新生代。
- 混合GC(Mixed GC):
- ✅ 发生 STW。
- 回收新生代 + 部分老年代Region。
- 初始标记(Initial Mark):
- ✅ 发生 STW(伴随Young GC)。
- 并发标记(Concurrent Mark):
- ❌ 不发生 STW。
- 最终标记(Final Remark):
- ✅ 发生 STW。
- 筛选回收(Cleanup):
- ✅ 部分 STW。
✅ 特点:可预测停顿,适合大堆、低延迟场景。
4. ZGC / Shenandoah(超低延迟收集器)
- 目标是将STW时间控制在10ms以内。
- 大部分标记和整理工作与应用线程并发执行。
- 仅有极短的STW阶段(如根扫描),且时间固定,不随堆大小增长。
✅ 适用于对延迟极度敏感的系统(如金融交易、实时游戏)。
总结:常见算法的STW情况对比
收集器 Minor GC Major GC Full GC 并发阶段 Serial ✅ STW ✅ STW ✅ STW 无 Parallel ✅ STW ✅ STW ✅ STW 无 CMS ❌(正常) ✅(初始标记、重新标记) ✅ 并发标记/清除 G1 ✅ STW ✅ STW(混合GC) ✅ 并发标记 ZGC/Shenandoah 极短STW 极短STW 极短STW 大部分并发
类初始化和类加载
创建对象的过程?
创建一个Java对象的过程包括以下5个核心步骤:
- 类加载检查:确保类已加载并初始化。
- 内存分配:在堆中分配空间(指针碰撞或空闲列表),通过TLAB或CAS保证线程安全。
- 内存初始化:将内存空间清零。
- 设置对象头:填充哈希码、GC年龄、锁状态、类型指针等信息。
- 执行构造函数:调用
<init>方法,完成对象的初始化。1. 检查类是否已加载(Class Loading)
当JVM遇到
new指令时,首先会检查该对象的类是否已经被加载、解析和初始化。
- 如果类未加载:
- JVM会触发类加载过程,通过类加载器(ClassLoader)加载
.class文件。- 执行连接(验证、准备、解析)和初始化(执行
<clinit>方法,如静态变量赋值、静态代码块)。- 如果类已加载:跳过此步骤。
2. 为对象分配内存(Memory Allocation)
类加载完成后,JVM需要在堆(Heap) 中为新对象分配内存。
由于对象创建非常频繁,多个线程可能同时分配内存,因此需要保证线程安全。JVM通过以下方式解决:
- CAS + 失败重试:使用原子操作保证指针更新的原子性。
- TLAB(Thread Local Allocation Buffer):为每个线程分配一块私有内存缓冲区,线程在自己的TLAB中分配内存,减少竞争。只有TLAB用完时才需要同步。
✅ TLAB是JVM的默认优化,可通过-XX:-UseTLAB关闭。3. 初始化内存空间(Zeroing)
JVM会将分配到的内存空间初始化为零值(如
0、null、false),确保对象的实例字段在未显式初始化时有确定的默认值。4. 设置对象头(Object Header)
JVM为对象设置对象头(Object Header),包含元数据信息:
- 哈希码(HashCode)
- GC分代年龄(用于新生代GC)
- 锁状态标志(无锁、偏向锁、轻量级锁、重量级锁)
- 类型指针(指向类元数据的指针)
- 数组长度(如果是数组对象)
5. 执行构造函数(Initialization)
最后,JVM调用对象的构造函数(
<init>方法),执行:
- 实例变量的显式初始化
- 构造代码块
- 构造方法中的代码
此时,对象才真正“初始化完成”,可以被程序使用。
对象的生命周期
对象的生命周期包括创建、使用和销毁三个阶段:
- 创建:对象通过关键字new在堆内存中被实例化,构造函数被调用,对象的内存空间被分配。
- 使用:对象被引用并执行相应的操作,可以通过引用访问对象的属性和方法,在程序运行过程中被不断使用。
- 销毁:当对象不再被引用时,通过垃圾回收机制自动回收对象所占用的内存空间。垃圾回收器会在适当的时候检测并回收不再被引用的对象,释放对象占用的内存空间,完成对象的销毁过程。
Java中类加载器的作用
在Java中,类加载器(ClassLoader) 是负责将
.class文件加载到JVM内存中的组件。它决定了类的加载方式、作用域和隔离机制。Java采用双亲委派模型(Parent Delegation Model),通过多层次的类加载器协作完成类的加载。
Java中有哪些类加载器
Java中有三种系统内置的类加载器:bootstrap ClassLoader、ExtClassLoader、AppClassLoader。
Bootstrap ClassLoader(启动类加载器)
- 作用:负责加载JVM核心类库。
- 加载路径:
$JAVA_HOME/jre/lib目录下的核心类(如rt.jar、tools.jar)。- 例如:
java.lang.*、java.util.*、java.io.*等所有以java.开头的类。- 实现语言:C/C++(是JVM的一部分,不是Java对象)。
- 父加载器:
null(它是所有类加载器的最终父辈)。- 特点:
- 最顶层的类加载器。
- 无法被Java代码直接引用。
✅ 示例:
String.class.getClassLoader()返回null,因为它由Bootstrap加载。Extension ClassLoader(扩展类加载器)
- 作用:负责加载Java的扩展类库。
- 加载路径:
$JAVA_HOME/jre/lib/ext目录。- 或系统属性
java.ext.dirs指定的路径。- 实现类:
sun.misc.Launcher$ExtClassLoader- 父加载器:Bootstrap ClassLoader
- 特点:
- 允许开发者将通用的第三方库放入此目录,自动被加载。
- 在JDK 9之后,随着模块化(JPMS)的引入,其作用减弱。
Application ClassLoader(应用程序类加载器 / 系统类加载器)
- 作用:负责加载用户自定义的类和第三方依赖。
- 加载路径:
- 类路径(
classpath)下的所有类。- 包括项目中的
.class文件、jar包等。- 实现类:
sun.misc.Launcher$AppClassLoader- 父加载器:Extension ClassLoader
- 特点:
- 是默认的类加载器。
- 可以通过
ClassLoader.getSystemClassLoader()获取。✅ 示例:你写的
com.example.MyClass就是由 Application ClassLoader 加载的。自定义类加载器(Custom Class Loader):
- 继承
java.lang.ClassLoader,开发者可以自定义加载逻辑。自定义类加载器可以用来扩展Java应用程序的灵活性和安全性,是Java动态性的一个重要体现。- 常见用途:
- 从网络、数据库、加密文件中加载类。
- 实现热部署、插件化、类隔离(如OSGi)。
什么是双亲委派模型?
双亲委派模型(Parent Delegation Model) 是 Java 类加载器(ClassLoader)在加载类时遵循的一种层次化、委派式的加载机制。它的核心思想是:
当一个类加载器收到类加载请求时,它不会立即自己去加载,而是先将请求委派给它的父类加载器去完成,只有当父类加载器无法完成该请求时,子类加载器才会尝试自己加载。
这个“父”不是指Java中的继承关系(
extends),而是类加载器内部维护的一个父委派引用。
双亲委派模型的目的
1. 保证类的唯一性(避免重复加载)
- 通过“向上委派”机制,确保同一个类只会被同一个类加载器加载一次。
- 例如:
java.lang.Object无论在哪个地方被引用,都由 Bootstrap ClassLoader 加载,避免了不同ClassLoader多次加载导致的类冲突或类型转换异常(ClassCastException)。- 实现了 JVM 中类的“全局唯一性契约”。
2. 保障核心类库的安全性(防止恶意篡改)
- Java 核心类(如
java.lang.String、java.lang.Object)由Bootstrap ClassLoader加载,它只从rt.jar等受信任路径加载。- 即使用户自定义一个
java.lang.String类,由于双亲委派,请求会先交给 Bootstrap,而 Bootstrap 已经加载了真正的String,因此自定义的 String 不会被加载。- 这种机制有效防止了“类污染”和“核心类伪造”攻击。
3. 简化加载流程,提升效率
- 类加载器无需关心所有类的来源,只需将请求“上交”给父类。
- 大部分核心类由顶层加载器快速处理,减少了底层加载器的查找负担。
- 避免了每个类加载器都要扫描整个类路径,提升了类加载的整体效率。
4. 支持层次化与隔离(模块化基础)
- 不同类加载器各司其职:
- Bootstrap:核心库
- Extension:扩展功能
- Application:应用代码
- 这种分层结构为 OSGi、Tomcat Web容器、插件系统、热部署 等提供了基础。
- 虽然默认是“委派”,但允许在必要时打破双亲委派(如SPI、热部署),实现灵活的类隔离与版本控制。
静态加载与动态加载
反射机制是 java 实现动态语言的关键,也就是通过反射实现类动态加载。
(1)静态加载:编译时加载相关的类,如果没有则报错,依赖性太强。
(2)动态加载:运行时加载需要的类,如果运行时不用该类,即使不存在该类,则不报错,降低了依赖性。
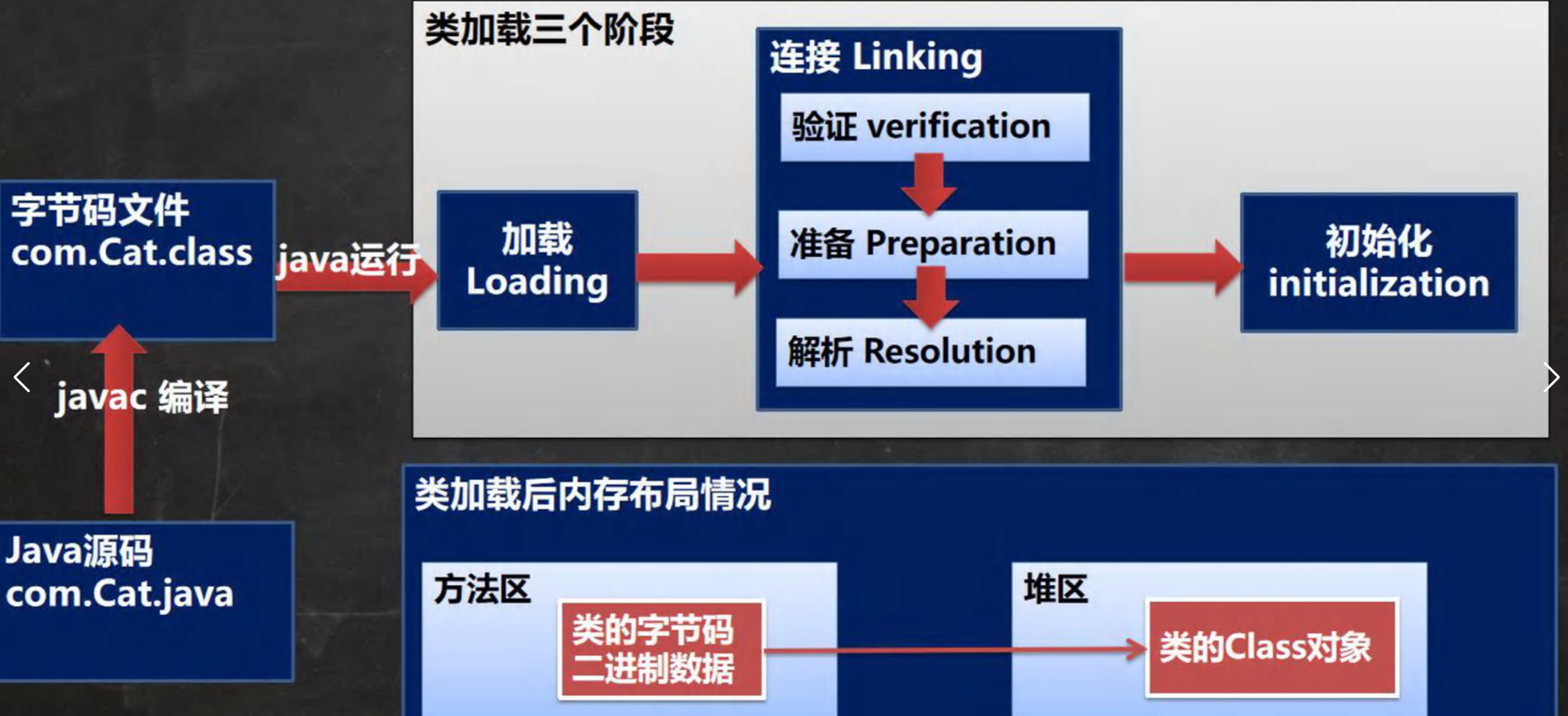
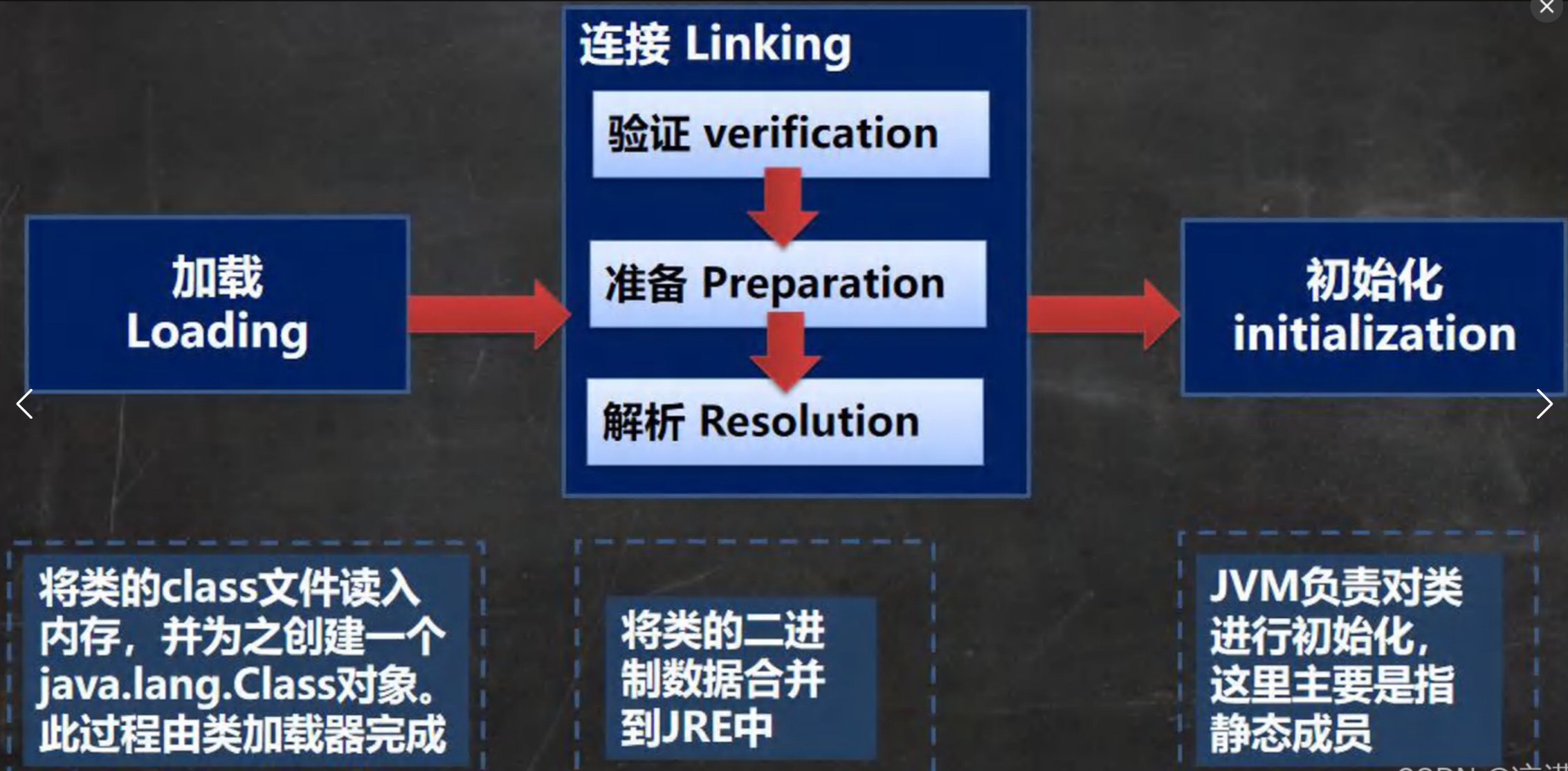
讲一下类加载过程?
一个类从被加载到JVM内存中,到可以被使用,需要经历 “加载 → 连接 → 初始化” 三个阶段,其中连接阶段又分为 验证、准备、解析 三个步骤。整个过程由类加载器(ClassLoader)和JVM协作完成。
加载阶段:JVM 在该阶段的主要目的是将字节码从不同的数据源(可能是 class 文件,也可能是 jar 包,甚至网络)转化为 二进制字节流加载到内存中,并生成一个代表该的 java.lang.Class 对象。
连接:验证、准备、解析 3 个阶段统称为连接。
- 连接阶段 - 验证
(1)目的是为了确保 Class 文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
(2)包括:文件格式验证(是否以魔数 oxcafebabe 开头)、元数据验证、字节码验证和符号引用验证。
(3)可以考虑使用 -Xverify:none 参数来关闭大部分的类验证措施,缩短虚拟机 类加载 的时间。- 连接阶段 - 准备
JVM 会在该阶段对静态变量,分配内存并 默认初始化(对应数据类型的默认初始值,如 0、0L、null、false 等)。
这些变量所使用的内存都将在 方法区 中进行分配。class A { //属性-成员变量-字段 //分析类加载的链接阶段-准备 属性是如何处理 //1. n1 是实例属性, 不是静态变量,因此在准备阶段,是不会分配内存 //2. n2 是静态变量,分配内存 n2 是默认初始化 0 ,而不是20 //3. n3 是static final 是常量, 他和静态变量不一样, 因为一旦赋值就不变 n3 = 30 public int n1 = 10; public static int n2 = 20; public static final int n3 = 30; }- 连接阶段-解析:虚拟机将常量池内的 符号引用 替换为 直接引用 的过程。
即:在Java虚拟机的运行时阶段,它会将常量池中的符号引用(如类、字段或方法的名称)替换为实际的直接引用(如内存地址或实际的对象引用)。Initialization(初始化)
- 执行类的初始化代码,真正为静态变量赋予程序中指定的值。
- 执行内容:
- 执行
static变量的显式赋值。- 执行
static代码块。- 调用类构造器
<clinit>()方法(由编译器自动收集所有static初始化代码生成)。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









