







🌈 开篇:数据库的烦恼与索引的救赎
想象你去图书馆找《哈利波特》,没有目录只能挨个书架翻(全表扫描)?数据库也有同样的烦恼!索引就是数据库的“智能目录”,而B+树则是MySQL设计的终极答案。接下来带你层层拆解这个设计智慧!
🎯 一、索引存在的意义:速度就是王道
1.1 没有索引的世界(全表扫描)
- 场景:100万条数据中找一条,就像在无目录图书馆找书
- 代价:平均要查50万次,磁盘I/O操作巨多(慢如蜗牛)
1.2 索引的核心作用
- 提速原理:把无序数据变有序,快速定位(类似字典查字)
- 关键指标:减少磁盘I/O次数(磁盘比内存慢10万倍!)
🚫 二、Hash索引:快的刺客,但有硬伤
2.1 Hash的闪光点
// 理想情况:O(1)时间复杂度秒查
HashMap<String, Integer> map = new HashMap<>();
map.put("id=5", 数据地址);
map.get("id=5"); // 瞬间找到
2.2 为何MySQL忍痛放弃?
- 范围查询无能:找id>100的数据?只能全遍历!
- 排序头疼:ORDER BY age?Hash数据无序,需额外排序
- 联合索引失效:WHERE name=‘张三’ AND age=20?合并Hash无法拆分
- 重复值灾难:性别列建Hash?大量碰撞变链表查询(O(n))
总结:Hash像精确制导导弹,只适合等值查询(如缓存),不适合复杂数据库场景。
🌳 三、二叉搜索树:优雅但脆弱
二叉(搜索)树特点
- 一个节点只能有两个子节点(一个节点的度不能超过2)
- 左子节点<本节点;右子节点>=本节点,比我大的向右,比我小的向左
3.1 理想中的平衡树
30
/ \
20 40
/ \ \
10 25 50
查找逻辑:比节点小往左,否则往右(O(logN))
3.2 残酷的现实
- 退化成链表:连续插入1,2,3,4… → 树变“高瘦竹竿”
- 磁盘I/O暴增:100万数据树高20层,读20次磁盘(慢!)
3.3 AVL树(平衡二叉搜索树)
在二叉搜索树上加了约束: 是一颗空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树也是一颗平衡二叉树
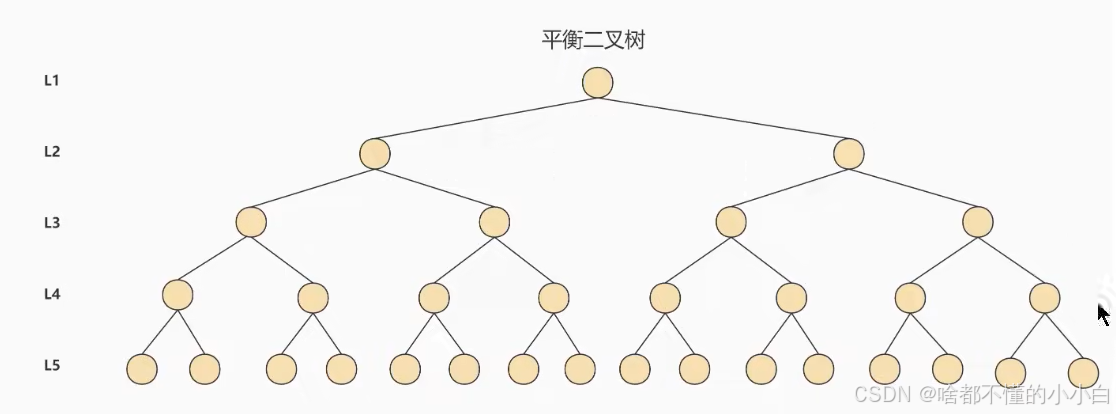
缺点:当数据量较大的时候,还是要经过很多磁盘IO,需要将二叉树变为M叉树
🌀 四、B树家族登场:矮胖才是正义
4.1 B树:多叉平衡术
[10|20|30]
/ | \
[1-9] [11-19] [21-29|31-...]
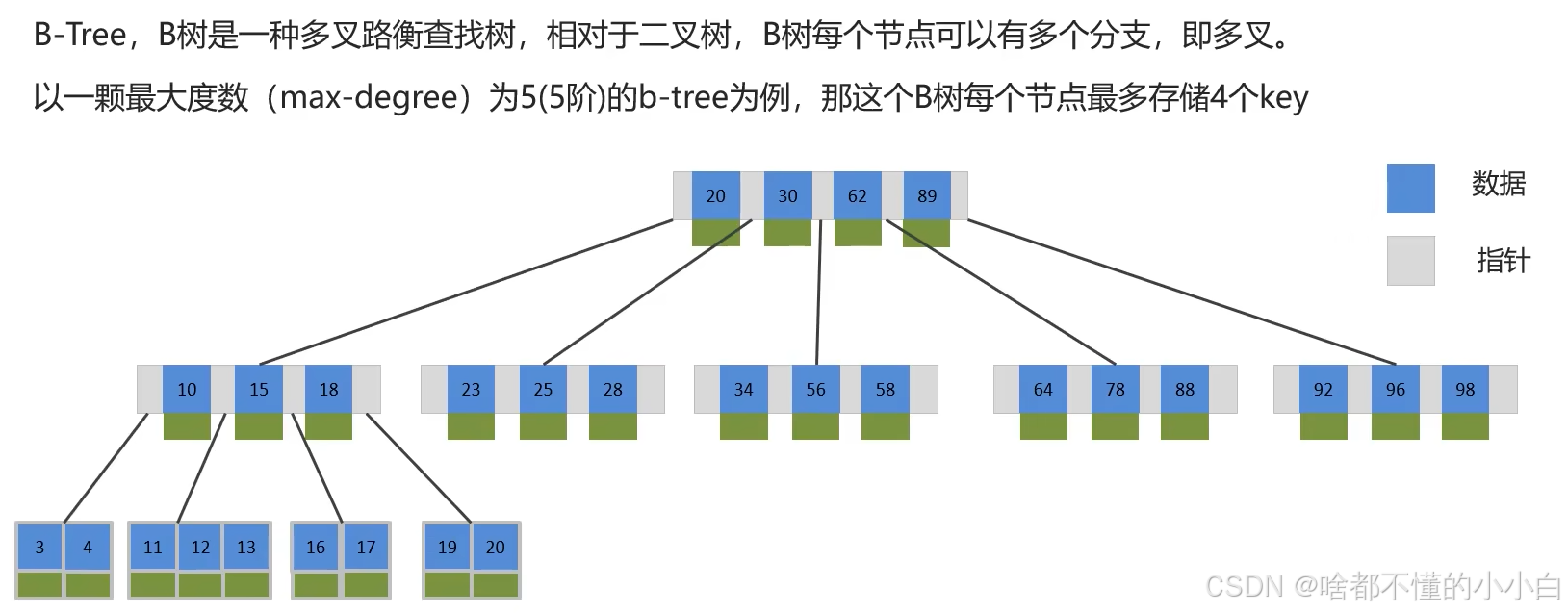
tip:
- b树在插入和删除节点时若导致树不平衡,会自动调节节点的位置保持树的平衡。
- 关键字集合分布在整颗树中,叶子节点和非叶子节点都会存放数据。
优势:
- 一个节点存多个值(类似文件柜多个抽屉)
- 树高仅3层就能存百万数据(磁盘I/O骤减)
4.2 B+树:青出于蓝
[10|20] → 指针层
/ | \
[1-10)→[10-20)→[20-∞)
tip:MySQL索引数据结构对经典的B+Tree进行了优化。在B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能
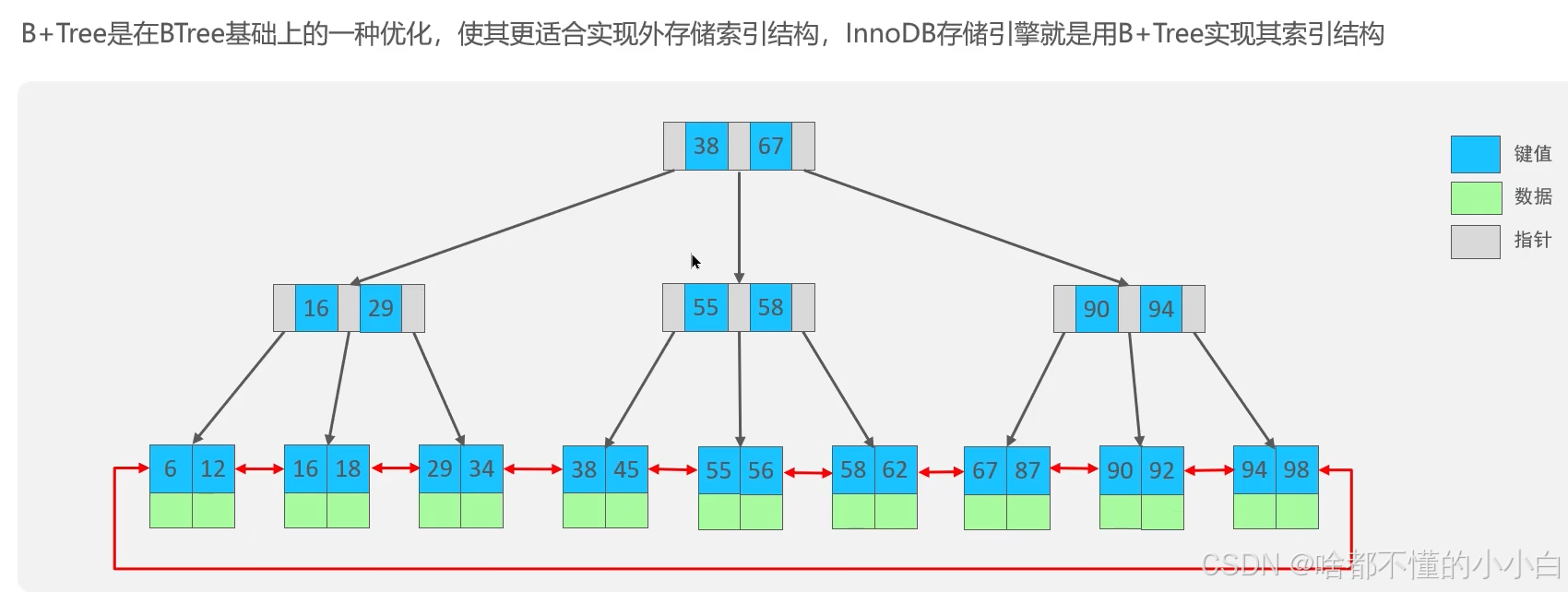
核心改进:
- 数据全在叶子节点:非叶子节点只做导航
- 叶子节点双向链表:范围查询直接遍历
- 更矮更胖:相同数据量,树高比B树更低
📊 五、B+树 VS B树:关键对决
| 特性 | B树 | B+树 |
|---|---|---|
| 数据存储位置 | 非叶子节点存数据 | 仅叶子节点存数据 |
| 查询稳定性 | 可能中途找到数据(波动) | 必须到叶子节点(稳定) |
| 范围查询 | 需要复杂回溯 | 链表直接遍历(超高效) |
| 空间利用率 | 节点分裂频繁 | 节点更紧凑(存更多键值) |
🛠 六、B+树在MySQL的终极优化
6.1 页式存储:批量读取更高效
- 默认页大小16KB:一次I/O读取多个键值(类似一次搬一箱书)
- 页内二分查找:内存中快速定位(0.1秒找到目标)
6.2 自适应哈希索引
如果某个数据经常被访问,当满足一定条件的时候, 就会将这个数据页的地址存放到Hash表中。这样下次查询的时候,就可以直接找到这个页面的所在位置。这样让B+树也具备了Hash索引的优点。
SHOW VARIABLES LIKE '%adaptive_hash_index%'; -- 默认开启
热数据自动Hash缓存:频繁访问的数据,B+树也能享受Hash速度!
🌟 七、为什么必须是B+树?
- IO次数最少:3层树高支撑2000万数据(3次I/O找到数据)
- 范围查询无敌:叶子节点链表直接扫区间
- 适合磁盘特性:顺序读取比随机快100倍
- 高并发优化:页分裂比B树更可控
🔍 八、其他树结构的陪跑故事
- 红黑树:频繁旋转调整,适合内存(如Java HashMap)
- R树:专精地理空间数据(找“附近3公里的奶茶店”)
- Trie树:处理字符串前缀(如自动补全)
📝 总结:B+树的胜利方程式
[减少I/O]
⬆️
[多叉平衡 → 树高降低]
⬆️
[叶子链表 → 范围无敌]
⬆️
[数据分离 → 查询稳定]
选择B+树,就是选择在磁盘I/O、范围查询、高并发之间找到最佳平衡! 🏆
参考:黑马程序员视频


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









