







参考链接
参考资料:
图像分割:https://zhuanlan.zhihu.com/p/70758906
阈值分割:https://blog.youkuaiyun.com/zhu_hongji/article/details/80967776
基于迭代的阈值分割:https://zhuanlan.zhihu.com/p/380931387
区域生长:https://www.guyuehome.com/41458
聚类算法:https://blog.youkuaiyun.com/google19890102/article/details/52911835
1.前言
图像分割是指将一幅图像划分成若干个互不重叠的区域的过程,每个区域内的像素具有相似的特征。常见的图像分割方法包括:
- 基于阈值的分割算法:通过将图像灰度值分成若干个区间,选择合适的阈值将像素分为两类或多类,适用于简单的分割任务。
- 基于边缘的分割算法:通过检测图像中的边缘信息来分割图像,典型的算法有Canny边缘检测和Sobel边缘检测等。
- 基于区域的分割算法:先将图像分成若干个相邻的区域,再通过某种准则将这些区域进一步合并或者分裂,直到达到预期的结果。典型的基于区域的分割算法有区域生长、区域分裂与合并等。
- 基于聚类的分割算法:将图像中的像素聚成不同的类别,从而实现图像分割,常用的聚类方法有K-Means、Mean Shift等。
- 基于水平集的分割算法:通过计算图像中的能量函数,将图像分成多个区域。常用的方法有水平集迭代、活动轮廓模型等。
- 基于深度学习的分割算法:利用深度学习技术训练出的神经网络对图像进行分割,常用的神经网络有FCN、U-Net等。
2.基于阈值的分割算法
阈值法的基本思想是基于图像的灰度特征来计算一个或多个灰度阈值,并将图像中每个像素的灰度值与阈值作比较,最后将像素根据比较结果分到合适的类别中。因此,该方法最为关键的一步就是按照某个准则函数来求解最佳灰度阈值。
阈值法特别适用于目标和背景占据不同灰度级范围的图。
- 单阈值分割:图像若只有目标和背景两大类,那么只需要选取一个阈值进行分割,此方法成为单阈值分割;
- 多阈值分割:但是如果图像中有多个目标需要提取,单一阈值的分割就会出现错误,在这种情况下就需要选取多个阈值将每个目标分隔开,这种分割方法相应的成为多阈值分割。
阀值分割方法的优缺点:
- 计算简单,效率较高;
- 只考虑像素点灰度值本身的特征,一般不考虑空间特征,因此对噪声比较敏感,鲁棒性不高。
最优阈值选择方法:
- 人工经验选择法:人工根据先验知识,对图像中的目标与背景进行分析。通过对像素的判断,图像的分析,选择出阈值值所在的区间,并通过实验进行对比,最后选择出比较好的阈值。这种方法虽然能用,但是效率较低且不能实现自动的阈值选取。对于样本图片较少时,可以选用。
- 利用直方图:利用直方图进行分析,并根据直方图的波峰和波谷之间的关系,选择出一个较好的阈值。这样方法,准确性较高,但是只对于存在一个目标和一个背景的,且两者对比明显的图像,且直方图是双峰的那种最有价值。
- 最大类间方差法(OSTU):是一种基于全局的阈值,使用最大类间方差自动确定阈值。
根据图像的灰度特性,将图像分为前景和背景两个部分。当取最佳阈值时,两部分之间的差别应该是最大的,在OTSU算法中所采用的衡量差别的标准就是较为常见的最大类间方差。前景和背景之间的类间方差如果越大,就说明构成图像的两个部分之间的差别越大,当部分目标被错分为背景或部分背景被错分为目标,都会导致两部分差别变小,当所取阈值的分割使类间方差最大时就意味着错分概率最小。
记T为前景与背景的分割阈值,前景点数占图像比例为w0,平均灰度为u0;背景点数占图像比例为w1,平均灰度为u1,图像的总平均灰度为u,前景和背景图象的方差g,则有:
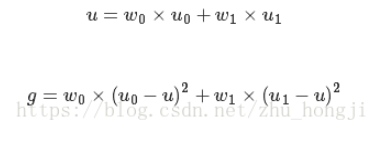
联立上式得:
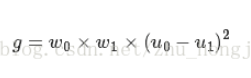
或:
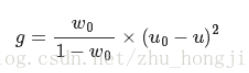
当方差g最大时,可以认为此时前景和背景差异最大,此时的灰度T是最佳阈值。类间方差法对噪声以及目标大小十分敏感,它仅对类间方差为单峰的图像产生较好的分割效果。当目标与背景的大小比例悬殊时(例如受光照不均、反光或背景复杂等因素影响),类间方差准则函数可能呈现双峰或多峰,此时效果不好。
- 自适应阈值:它的思想不是计算全局图像的阈值,而是根据图像不同区域亮度分布,计算其局部阈值,所以对于图像不同区域,能够自适应计算不同的阈值,因此被称为自适应阈值法。(其实就是局部阈值法)
具体操作步骤如下:
(1) 对某个像素值,原来为 S,取其周围的 n×n 的区域,求区域均值或高斯加权值,记为 T
(2) 对 8位图像,如果 S>T,则该像素点二值化为 255,否则为 0 - 基于迭代的阈值分割

3.基于区域的图像分割方法
基于区域的分割方法是以直接寻找区域为基础的分割技术,基于区域提取方法有两种基本形式:
- 一种是区域生长,从单个像素出发,逐步合并以形成所需要的分割区域;
- 另一种是从全局出发,逐步切割至所需的分割区域。
区域生长
区域生长算法的基本思想是将有相似性质的像素点合并到一起。对每一个区域要先指定一个种子点作为生长的起点,然后将种子点周围领域的像素点和种子点进行对比,将具有相似性质的点合并起来继续向外生长,直到没有满足条件的像素被包括进来为止。这样一个区域的生长就完成了。这个过程中有几个关键的问题:
- 给定种子点(种子点如何选取?)
种子点的选取很多时候都采用人工交互的方法实现,也有用其他方式的,比如寻找物体并提取物体内部点作为种子点。 - 确定在生长过程中能将相邻像素包括进来的准则
灰度图像的差值;彩色图像的颜色等等。都是关于像素与像素间的关系描述。 - 生长的停止条件
区域分裂与合并
区域分裂合并法与区域生长法略有相似之处,但无需预先指定种子点,而是按某种一致性准则分裂或者合并区域。分裂合并法对分割复杂的场景图像比较有效。
区域生长是从某个或者某些像素点出发,最终得到整个区域,进而实现目标的提取。而分裂合并可以说是区域生长的逆过程,从整幅图像出发,不断的分裂得到各个子区域,然后再把前景区域合并,得到需要分割的前景目标,进而实现目标的提取。
总的来说,就是先把图像分成4块,若这其中的一块符合分裂条件,那么这一块又分裂成4块,就这样一直分裂。分裂到一定数量时,以每块为中心,检查相邻的各块,满足一定条件,就合并。
如此循环往复进行分裂和合并的操作。
最后合并小区,即把一些小块图像的合并到旁边的大块里。
区域分裂合并算法优缺点:
(1)对复杂图像分割效果好;
(2)算法复杂,计算量大;
(3)分裂有可能破怪区域的边界。
在实际应用当中通常将区域生长算法和区域分裂合并算法结合使用,该类算法对某些复杂物体定义的复杂场景的分割或者对某些自然景物的分割等类似先验知识不足的图像分割效果较为理想。
4.基于聚类的图像分割方法
K-Means算法是基于距离相似性的聚类算法,通过比较样本之间的相似性,将形式的样本划分到同一个类别中,K-Means算法的基本过程:
- 初始化常数 ,随机初始化k个聚类中心
- 重复计算以下过程,直到聚类中心不再改变
- 计算每个样本与每个聚类中心之间的相似度,将样本划分到最相似的类别中
- 计算划分到每个类别中的所有样本特征的均值,并将该均值作为每个类新的聚类中心
- 输出最终的聚类中心以及每个样本所属的类别
在K-Means算法中,需要随机初始化k个聚类中心,而K-Means算法对初始聚类中心的选取较为敏感,若选择的聚类中心不好,则得到的聚类结果会非常差,因此,对K-Means算法提出了很多的改进的方法,如K-Means++算法,在K-Means++算法中,希望初始化的k个聚类中心之间的距离尽可能的大,其具体过程为:
- 在数据集中随机选择一个样本点作为第一个初始化的聚类中心
- 选择出其余的聚类中心:
- 计算样本中的每一个样本点与已经初始化的聚类中心之间的距离,并选择其中最短的距离
- 以概率选择距离最大的样本作为新的聚类中心,重复上述过程,直到 个聚类中心都被确定
- 对k个初始化的聚类中心,利用K-Means算法计算最终的聚类中心。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









