




 本文探讨了数据结构中的散列表(哈希表)如何使用链地址法处理冲突。通过建立一个一维数组,将相同散列地址的元素链接成单链表,实现了高效的数据存储和查找。文中包含存储结构的定义、相关操作函数以及具体实例演示。
本文探讨了数据结构中的散列表(哈希表)如何使用链地址法处理冲突。通过建立一个一维数组,将相同散列地址的元素链接成单链表,实现了高效的数据存储和查找。文中包含存储结构的定义、相关操作函数以及具体实例演示。
散列表链地址法基本思想是将相同散列地址的元素放在同一个单链表中,即称同义词链表。例如此时我们设一个散列函数H(key)=key%n,则可以定义一个一维数组,大小为n,数组元素对应关键字模n所得的数字。
如下图:n为13,各关键字模13后插入对应值的表中。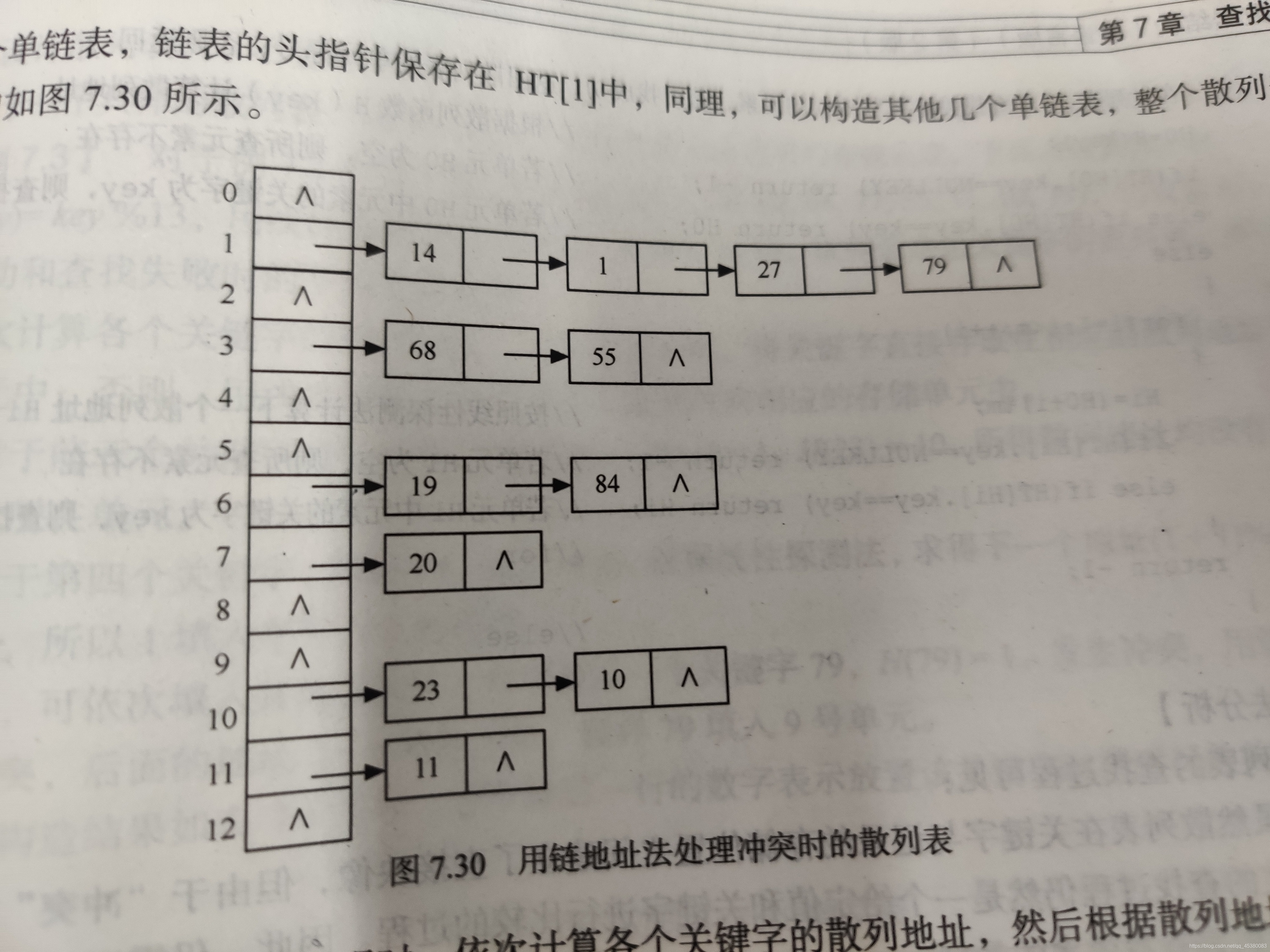
代码部分
存储结构:
typedef struct hashnode
{
int data;
struct hashnode* next;
}hashnode,*hashbit;
data存元素值,next指向冲突元素地址。
相关函数:
void inithash(hashbit H[],int n) //初始化
{
int i;
for(i=0;i<n;i++)
{
H[i]=new hashnode;
H[i]->data=i;
H[i]->next=NULL;
}
}
void inserthash(hashbit H[],int x,int n) //插入
{
int i=x%n;
hashbit p=new hashnode;
hashbit q=new hashnode;
q->data=x;
p=H[i];
while(p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









