







索引是帮助MySQL高效获取数据的排好序的数据结构
二叉树 --- 链表二叉树 与直接查询效果差不多
红黑树 --- 一种特殊的二叉树(二叉平衡树) --树散列不好,层次太多(高度等于查询次数)
B树 --- 没有冗余索引,每个索引下都自己的数据,叶子节点的指针为空
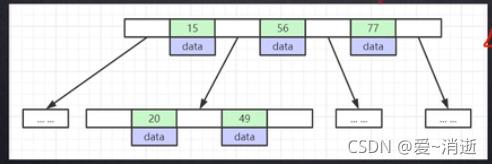
B+树 --- 1) 非叶子节点不存储data,只存储冗余索引(重复),可以放跟多的索引(索引(bigint = 8b) +
指针 = 6b) 一个pigesize为16kb 所以一页可放1170个索引
2) 叶子节点包含所有索引字段 (高度为3的B+树,可以放两千多万的数据)
3) 叶子节点用指针连接,提高区间访问的性能
当查询索引30时,应为冗余索引是由小到大的顺序结构,在内存(RAM)中折半查询到30所在的位置,查询高度次数后,高度次数IO后,查询到
MySQL 存储引擎都是表级别的
MyISAM索引文件与数据文件是分离的(非聚集) : .frm 表结构 .MYD 表数据 .MYI 索引
回表:非聚集索引:查到索引后到数据表中查询数据
innoDB存储引擎(聚集(聚簇)索引) : 聚集索引-叶子节点包含了完整的数据记录
.frm 表结构 .ibd 表数据 + 索引
主键索引:
二级索引:
为什么建议innoDB表必须建主键,并且推荐使用整型的自增主键(不用UUID)?
因为如果不使用主键,mySQL底层会自动维护一个主键,并使用自己维护的主键来构建B+树,而数据库的资源是珍贵的, 使用要自己建立一个主键,而uuid在比较时候,会增大运行速度,
Hash索引(数组 +链表 ):很多时候Hash索引要比B+ 树索引更高效,但是由于hash冲突问题(hash碰撞 : 2个数据进行一个hash计算得出一个相等的值.会在链表的后面加元素与地址值,产生hash碰撞后,会遍历链表,查询效率慢),最重要的是hash索引不能范围查询.
B+树:范围查找 : 因为在B+树中,每一层都是由小到大顺序排序的, 并且每一顺序组叶子节点集之间,都会存在一个指针.主键自增为了避免B+树多次分裂,如果多次分裂,效率必定不高
联合索引::
最左前缀原则:创建了一个索引后,必须顺序使用属性,不能跳着使用或者不使用最左端的属性,之间使用其他属性.
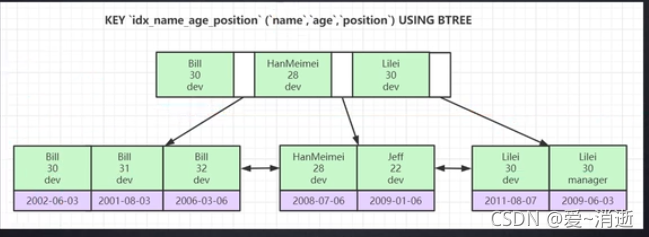
name属性是排序的,当跳过name时,age属性不是顺序排序的,只能进行全盘扫描,就没有使用索引.

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









