









 本文详细探讨了Spring框架中的Bean生命周期,包括XML配置文件、Bean的创建和初始化过程。重点讨论了Bean的三级缓存,分析了在解决循环依赖问题中的作用。此外,还解释了AWare接口的用途以及在AOP代理中对象版本控制的问题。
本文详细探讨了Spring框架中的Bean生命周期,包括XML配置文件、Bean的创建和初始化过程。重点讨论了Bean的三级缓存,分析了在解决循环依赖问题中的作用。此外,还解释了AWare接口的用途以及在AOP代理中对象版本控制的问题。
Spring 首先是一个框架,在整个开发流程中,所有的框架生产几乎都依赖与Spring,Spring帮我们起到了一个IOC容器的作用,用来承载我们整体的Bean对象,他帮我们继续了整个对象从创建到销毁的整个生命周期的管理,我们在使用Spring的时候,可以使用配置文件,也可以使用注解的方式来进行相关实现,当我们程序开始启动时,要把注解或者配置文件定义的Bean对象转为为BeanDefinition(bean的定义对象) 完成对整个BeanDefinition进行实例化操作,最简单的方式是通过反射的方式,创建好对象时,只是在堆中开辟了一段空间, 并没有完成一系列初始化操作,在后面会实现“啊为而”接口的一些相关操作,实现aop时,会实现一些“Beanpost死为..”,beanD.. 也会创建一起bean.
xml 配置文件(对象,构造器)
<bean id = person class=com.cy.Person>
<property name=id value =1>
<property name=name value=zhuangsan>
</bean>
<bean id=person class=com.cy.Person>
<Constructor-arg name=id value=1>
<Constructor-arg name=name value=zhangsan>
</bean>解析注解与解析配置文件的方式是否一样 不一样,但是最终由一个抽象接口约束BeanDefinitionReader读取,转化为BeanDefinition
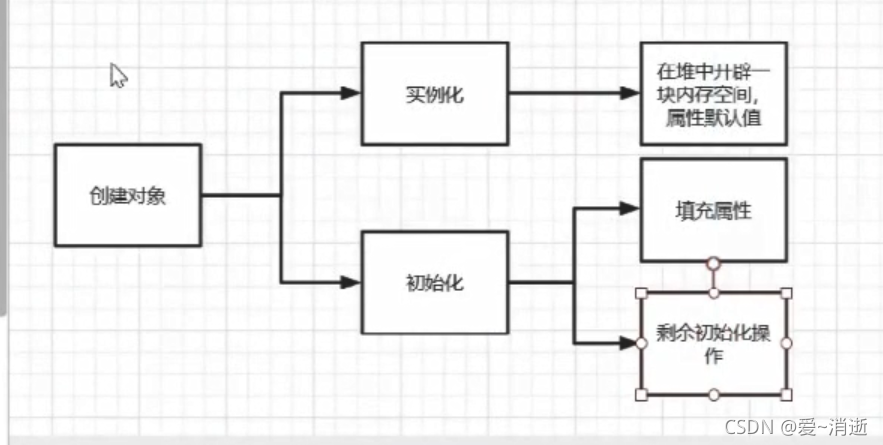
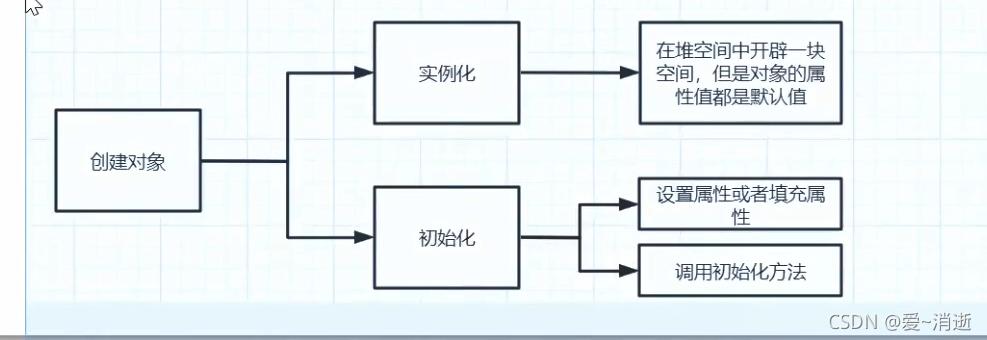
创建对象分为几个步骤
Bean的生命周期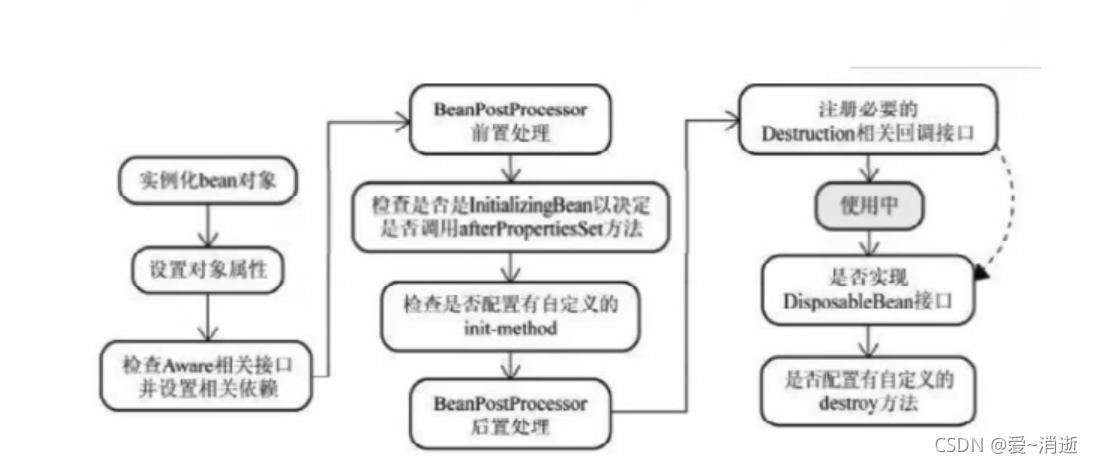
Bean的创建
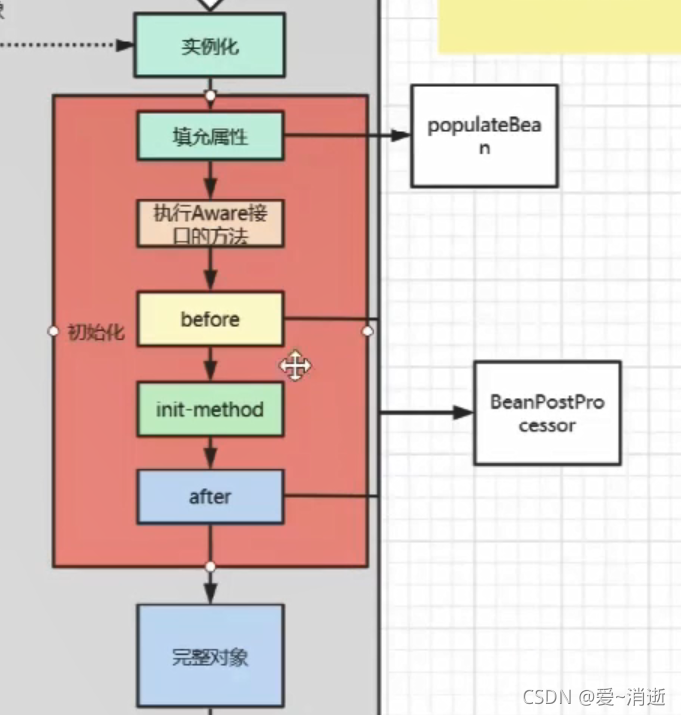
AWare接口是为了使某些自定义对象能获取到容器对象。
如果一个对象需要创建代理对象,是否会进行反射的普通创建(刚刚的实例化会不会操作)。
答:一定会
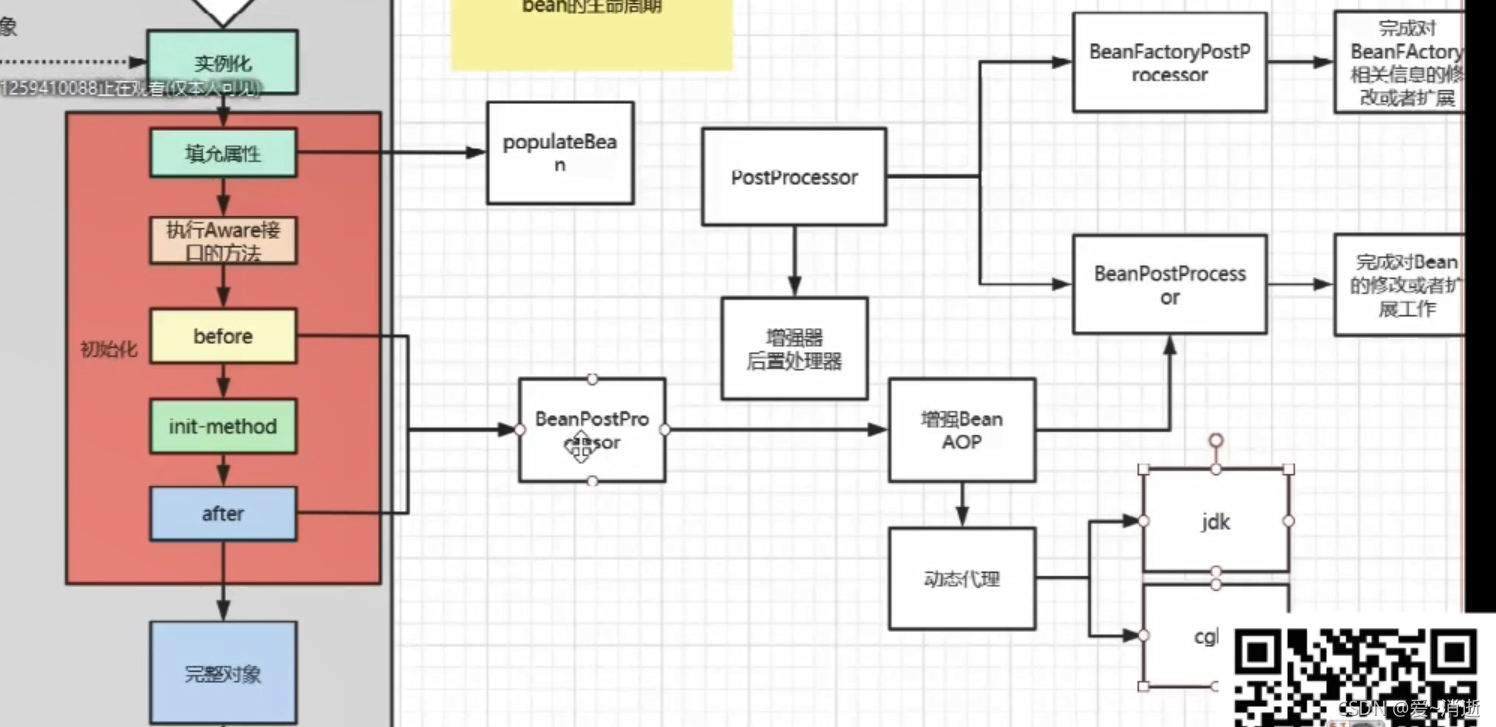
创建一个Bean对象
1 创建beanFactory容器
2 加载配置文件,解析bean的定义信息,包装为BeanDefinition
3 执行BeanFactoryPostProcessor
准备工作:准备BeanPostProessor,广播器,监听器
4 实例化操作
6 初始化操作
6 获取对象
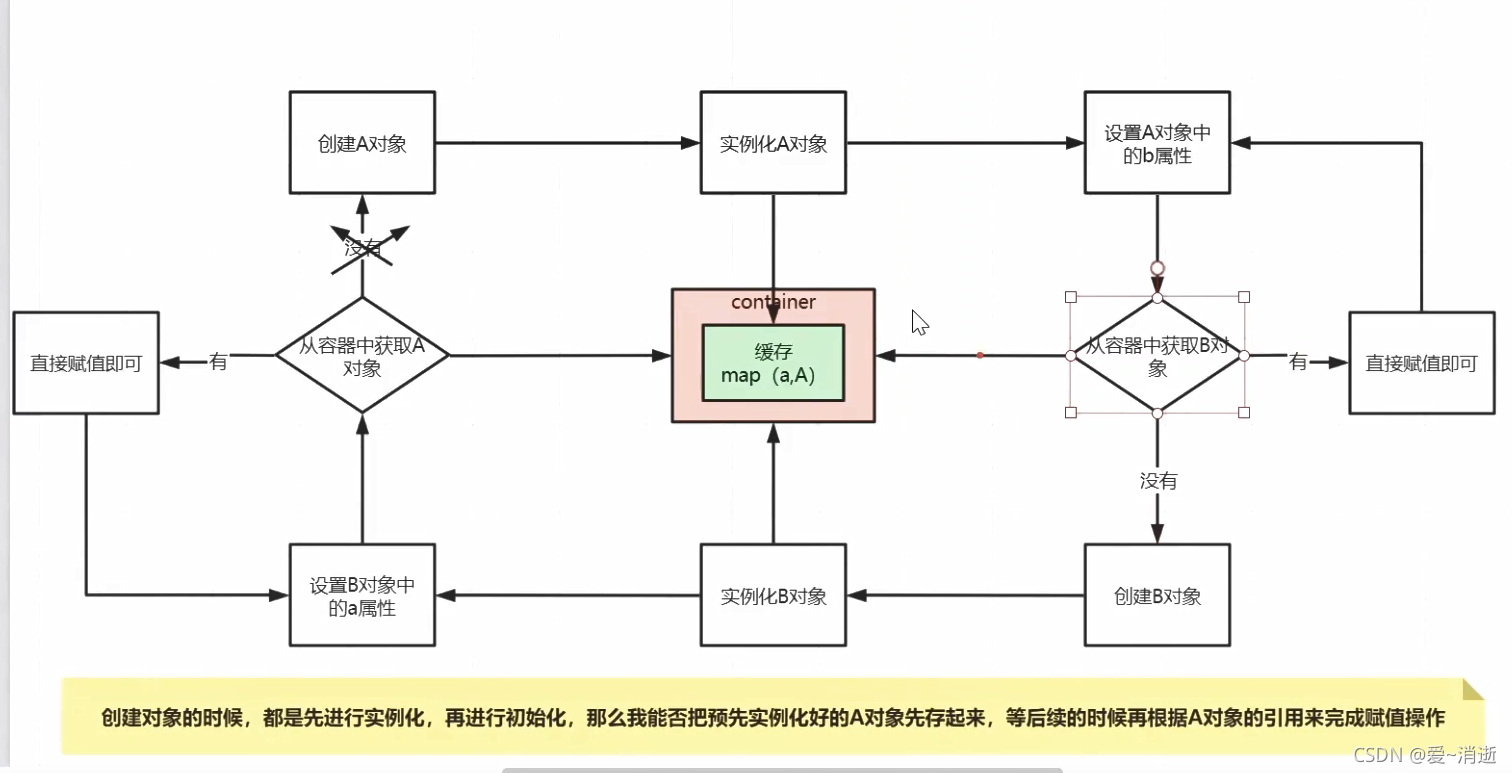
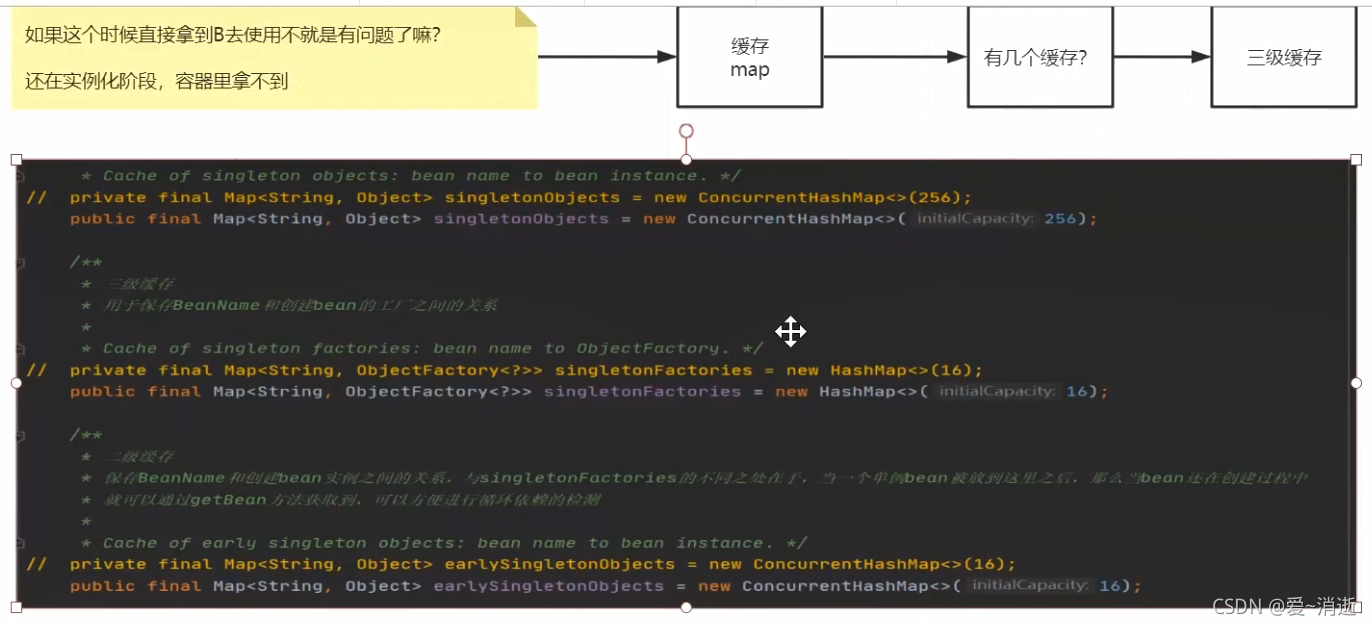
1 2 3 级缓存区别主要在于value值,12 为Object 3 为ObjectFunctory 是函数方法接口

refresh : 源码中最终重要的代码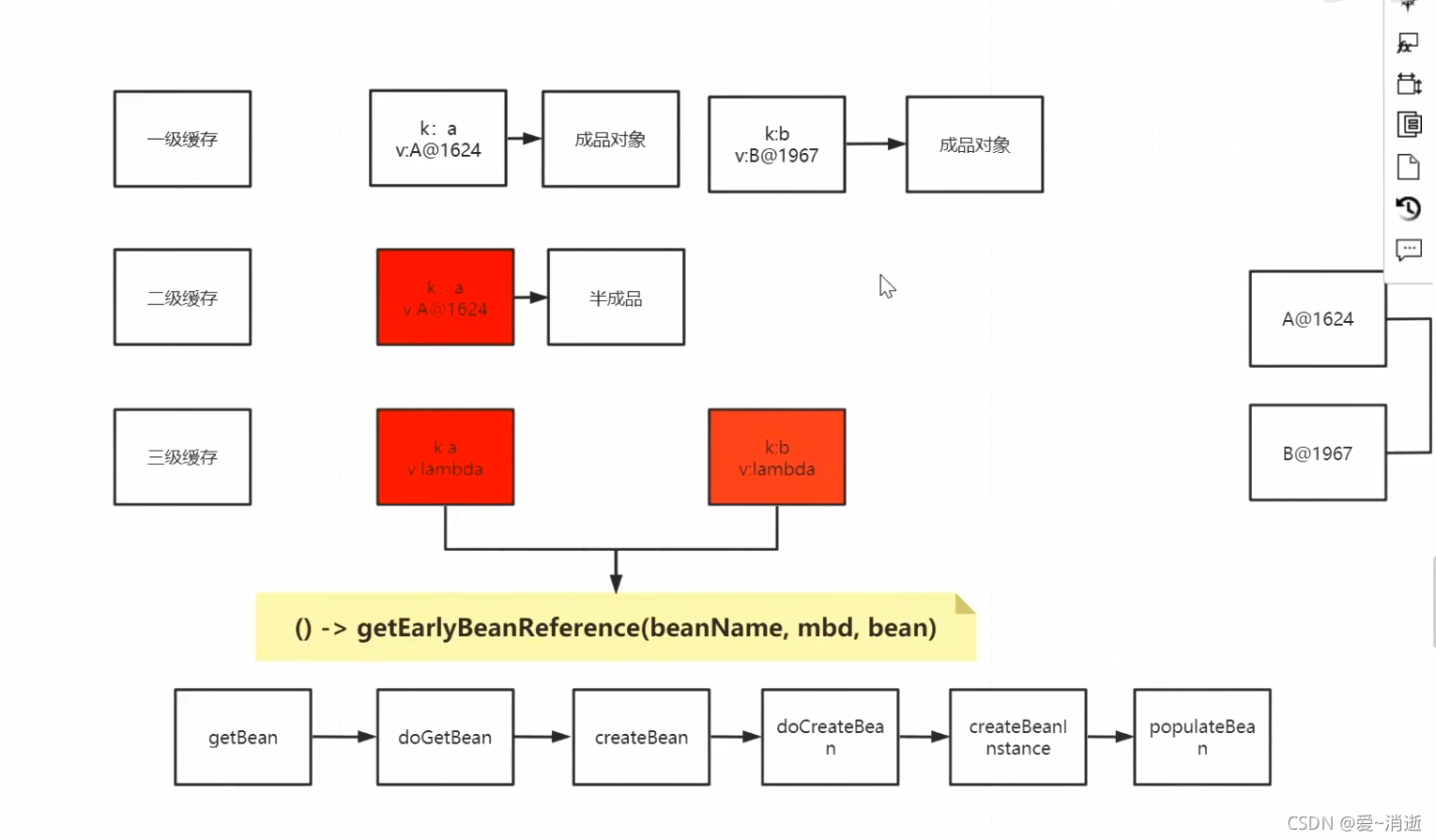
问题:
1 一二三级缓存分别存放什么状态的对象
三级缓存:map集合 k:a , v: lambda表达式
二级缓存:半成品对象
一级缓存: 成品对象
2 如果只设计一级缓存能否解决循环依赖问题
如果只设计一级缓存能否解决依赖循环问题
不能,如果只有一级缓存,那个意味着半成品与成品对象都要放在一级缓存中,那么就有可能获取到对象的非完整状态,不能使用
3 如果只有二级缓存,能否解决循环依赖问题
可以,但是是在没有使用AOP的情况下,不需要代理对象
为什么要使用三级缓存呢,为了解决代理过程中的循环依赖问题
4 那些地方用到了三级缓存
addSingleFactory: 向三级缓存中放置属性值
getSingleton;从三级缓存中获取属性值
5 如果一个对象需要被代理的话,在整个容器中,会存在几个当前对象的版本
2个:
一个为原始对象,直接通过反射创建出的对象
一个为通过cglib或者jdk的动态代理创建对象来的对象
6 到底哪里被代理了,当添加了aop后,和刚刚的处理步骤哪里不一样了
在getEarlyBeanReference方法中 是有可能吧之前的原始对象替换成代理对象的,所以此时会造成版本不一致,也就是无法使用的最终版本(原始版本被gc)
7 总结:每次我们在获取对象的时候,是通过对象的name来获取bean的,如果原始对象和代理对象同时存在时,那么通过name在进行获取时,应用那个? 无法选择 。最核心的是是,你则么确定对象什么时候需要被引用了?使用lambda(1.8之前,匿名内部类)表达式其实代表了一种回调机制,当需要时候当前对象时,通过lambda表达式最终返回一个确定的最终版本对象,而不需要判断有几个对象,因为是替换的过程,所以只可能是一个
8 这三级缓存的查找顺序?
在getSingleton方法中进行对象的查找
查找的时候先找SingletonObjects 然后在找earlySingonObjects 最后在找SingletFactory

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









