







 该博客通过代码实例分析了 Apache Flink 中的 Aggregate 函数(聚合)与 minBy、maxBy 方法的区别。Aggregate 函数用于对数据进行聚合操作,如 SUM、MAX 和 MIN,但结果可能不保留原始键值对应关系。而 minBy 和 maxBy 在找到最小值或最大值时,会返回包含该值的完整元组,确保键值对应。这为数据分析提供了不同方式的选择。
该博客通过代码实例分析了 Apache Flink 中的 Aggregate 函数(聚合)与 minBy、maxBy 方法的区别。Aggregate 函数用于对数据进行聚合操作,如 SUM、MAX 和 MIN,但结果可能不保留原始键值对应关系。而 minBy 和 maxBy 在找到最小值或最大值时,会返回包含该值的完整元组,确保键值对应。这为数据分析提供了不同方式的选择。
Flink得Aggregate和minBy、maxBy的区别
直接代码结果分析说明
public class AggregateDemo {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource dataSource = env.readTextFile(“data/apache.log”);
MapOperator<String, Tuple2<String, Integer>> map = dataSource.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value.split(" ")[0], 1);
}
});
GroupReduceOperator<Tuple2<String, Integer>, Tuple2<String, Integer>> reduceOperator = map.groupBy(0).reduceGroup(new GroupReduceFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() {
@Override
public void reduce(Iterable<Tuple2<String, Integer>> values, Collector<Tuple2<String, Integer>> out) throws Exception {
String key = null;
int count = 0;
for (Tuple2<String, Integer> value : values) {
key = value.f0;
count += value.f1;
}
out.collect(Tuple2.of(key, count));
}
});
reduceOperator.print();
System.out.println("--------------------");
reduceOperator.aggregate(Aggregations.MAX,1).print();
reduceOperator.aggregate(Aggregations.MIN,1).print();
reduceOperator.aggregate(Aggregations.SUM,1).print();
}
}
这个代码运行结果如下:

根据结果可以看出,经过Aggregate.MAX和Aggregations.MIN和Aggregations.SUM处理的结果key和value是不对应的,比如原有数据value最大的应该是(10.0.0.1,7),但是Aggregate.MAX得出的数据是(83.149.9.216,7)。
然后再看maxBy和minBy的程序和结果:
reduceOperator.minBy(1).print();
reduceOperator.maxBy(1).print();
结果如图
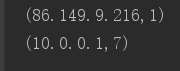
key和value是对应的;
所以两种都是求最值,但是内部计算逻辑不一样:
Min在计算的过程中,会记录最小值,对于其它的列,会取最后一次出现的,然后和最小值组合形成结果返回;
minBy在计算的过程中,当遇到最小值后,将第一次出现的最小值所在的整个元素返回。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









