







浅谈backpropagation
backpropagation学习体会
学习了一段时间的deep learn,较早的接触到了反向传播算法,但是脑子里对BP的印象就是“链式法则”,再没有对它其他的理解。所以在后续学习中,也会有很多困惑,所以攻克BP势在必行 !!!
BP的固有印象

第一次提及反向传播时的样子。包括我看了很多资料,许多公式推导,图片解释,字母太多,始终都是云里雾里。那不如从最简单的开始,不去制造额外的符号,借助链式法则,来进一步理解。
一些想法的产生
当然,反向传播与链式法则密切相关,但BP不等同于链式法则。所以,我脑袋里感觉像突然长了脑子一样,产生了一系列问题。首先想到的问题是:反向传播算法(以下用BP代指)是什么?BP与正向传播算法有什么关系?BP算法可以用来干什么?反向传播传播的是什么?BP与梯度下降是什么关系? …
离开了前向传播的反向传播都是耍流氓(反向传播传播的是什么???)
首先,来看看前向传播的一些知识
前向传播
- 前向传播,它传播的是输入数据,权值参数。
- 它将输入数据逐层传递并经过一系列线性变换和非线性激活函数的操作,最终计算出网络的输出结果。
- 以及计算loss
反向传播
反向传播传播的是各层权重参数的梯度信息
反向传播通过计算梯度,将梯度信息从输出层逐层传播回输入层,以确定如何调整权重参数
梯度的简要介绍
梯度,就是导数变化最快的方向的反方向,也就是使得数据下降最快的方向
二维理解
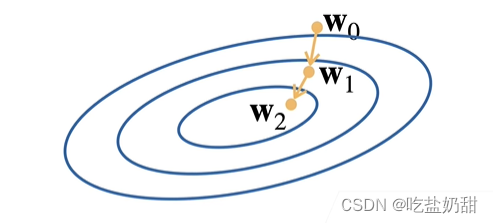
三维理解
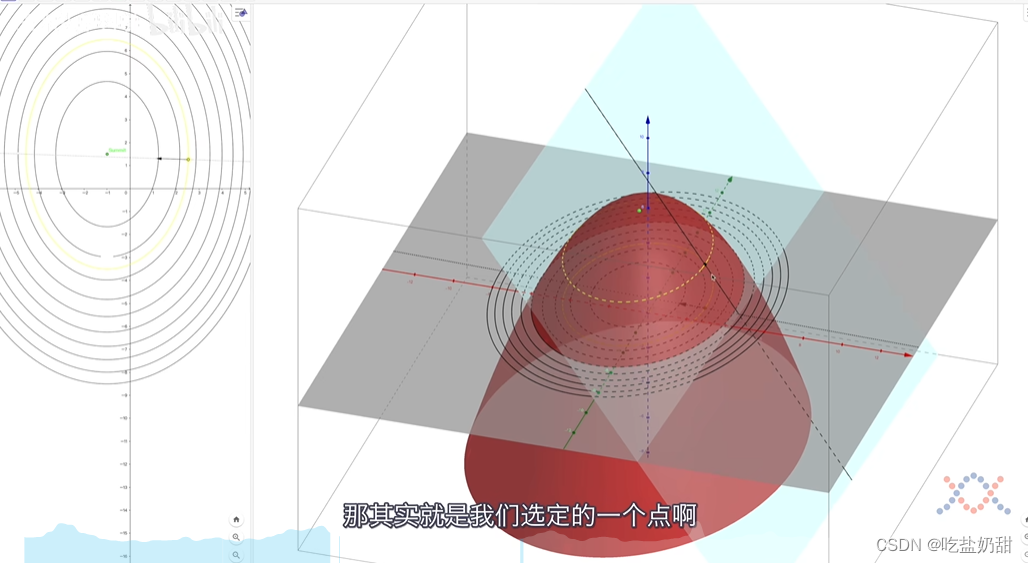
在学习到优化算法时,学习到了梯度下降这个概念,似乎反向传播和梯度下降有着某种联系。事实证明,学习梯度下降,有助于我们理解反向传播。
反向传播与梯度下降的关系
先看梯度下降的概念
梯度下降:
- 梯度下降是一种优化算法,用于更新神经网络中的权重参数,以最小化损失函数。
- 它的核心思想是根据损失函数对权重参数的梯度信息,以负梯度方向来调整权重参数,以减小损失函数的值。
- 梯度下降的目标是找到使损失函数达到最小值的权重参数
关系
- BP:计算并传播梯度的信息
- 梯度下降:更新权重参数
- 关系:反向传播提供了梯度的信息,梯度下降利用这些信息来不断调整模型参数,以最小化损失函数。
梯度下降如何更新

- η是学习率
- L关于Wt-1的梯度,其实是一个复合函数,这里就用到了反向传播。(这点很重要)
到这里许多问题迎刃而解
反向传播,只是传播梯度嘛?
答案是:yes!!! 权值参数的更新由梯度下降算法来负责。梯度下降算法中,需要反向传播里计算的梯度。
计算梯度和更新权重什么关系
答:就是反向传播和梯度下降算法的关系。
到这里,我似乎明白了,反向传播算法是什么,它用来干什么的,为什么和梯度下降有关系,二者之间是为什么有联系的。甚至弄清楚了权重是如何更新的细节。
现在,我反向传播的理解已经不再是“链式求导”了!!!
而是:
BP算法,负责传递梯度的信息,为权重的更新做准备,而这个操作是由梯度下降算法来完成的。怎么更新,请参照上面的公式哟!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









