






 本文介绍了Python编程的基本概念,包括变量、数据类型、字符串编码、控制结构、函数、字典和列表等。讲解了如何使用Python进行算术运算、字符串操作、循环结构、函数定义和调用,以及字典和列表的创建、遍历和修改。此外,还探讨了异常处理、面向对象编程、文件操作和模块导入。通过实例,深入理解Python编程的核心概念和技巧。
本文介绍了Python编程的基本概念,包括变量、数据类型、字符串编码、控制结构、函数、字典和列表等。讲解了如何使用Python进行算术运算、字符串操作、循环结构、函数定义和调用,以及字典和列表的创建、遍历和修改。此外,还探讨了异常处理、面向对象编程、文件操作和模块导入。通过实例,深入理解Python编程的核心概念和技巧。
目录
1.print()
可以输出数字print(520)
可以输出字符串print('hello word')
含有运算符的表达式print(3+1)#会计算表达式的结果
将数据输出到文件中
fp=open('D:/text.txt','a+')#a+以读写的方式打开文件,a+如果文件不存在就创建,存在就打开继续追加
print('Hello world',file=fp)#要使用file=fp
fp.close()#关闭不进行换行输出(输出内容在一行当中)
print("hello","world","HFF")2.转义字符
转义字符就是:反斜杠+想要实现的转义功能首字母
换行\n 回车\r 水平制表符\t 退格\b
print("hello \nworld")
print("hello \tworld")#四个字符一个表格 0_ _ _
print("helloooo \tworld")#_ _ _ _ 看\t之前是否占满制表位,占满就重新开一个,没占满接着用
print("hello\rworld") #回车,world把hello覆盖掉了
print('hello\bworld')#退一个格,把o退掉了\\第一个斜线是反斜线,第二个相当于转义字符但又不是
print("http:\\www.baidu.com")http:\www.baidu.com#少了一个斜线
print(http:\\\\www.baidu.com)
http:\\www.baidu.com#两个\\会转出一个\
print(”老师说:\"大家好\"")\"表示这不是”不再是字符串的边界而是 字符串中应该输出的内容
原字符,不希望字符串中的转义字符起作用,就是在字符串之前加上r或R
print(r"hello\nworld")#最后一个字符不能是反斜杠
print(r"hello\nworld\\")#两个可以3.二进制与字符编码
8个位置(bit)为一个字节,1024个字节等于1KB(千),1024KB=1MB(兆),1024MB=1GB(吉)1024GB=1TB(太)
print(chr(0b100111001011000))#乘 0b-二进制
print(ord(乘))#0rd十进制4.标识符和保留字
严格区分大小写
import keyword
print(keyword.kwlist)#查看保留字5.变量的定义和使用
变量由三部分组成:
标识:表示对象所存储的内存地址,使用内置函数id(obj)来获取
类型:表示的是对象的数据类型,使用内置函数type(obj)来获取
值:表示对象所存储的具体数据,使用print(obj)可以将值进行打印输出
name='懒羊羊' print(name) print('标识',id(name)) print('类型',type(name)) print('值',name)
6.变量的多次赋值
多次赋值以后,变量名会指向新的空间,原来name id指向的空间变成了内存垃圾
name='懒羊羊'
name='灰太狼'
print(name)7.数据类型
整数类型——>int——>100
浮点数类型——>float——>3.14156
布尔类型——>bool——>True,False
字符串类型——>str——>'朝闻道,夕死可矣'
8.整数类型
十进制——默认进制,取值0-9
二进制——以0b开头,取值0-1
八进制——以0o开头,取值0-7
十六进制——以0x开头,取值0-9和A-F
print('二进制',0b10101111)9.浮点类型
浮点数存储不精确性
使用浮点数进行计算时,可能会出现小数位数不确定的情况
n1=1.1
n2=2.2
print(n1+n2)解决方案:导入模块decimal
from decimal import Decimal
print(Decimal('1.1')+Decimal('2.2'))10.布尔类型
布尔值可以转化为整数
True——1
False——0
f1=False
print(f1+1)#直接转11.字符串类型
字符串又称不可变的字符序列
可以使用单引号,双引号,三引号来定义
单引号和双引号定义的字符串必须在一行
三引号定义的字符串可以分布在连续的多行
str1='朝闻道,夕死可矣'
str2="朝闻道,夕死可矣"
str3="""朝闻道,
夕死可矣"""12.数据类型转换
将不同数据类型的数据拼接在一起
str() int() float()
name='懒羊羊'
age=8
print('我叫'+name+'今年'+str(age)+'岁')int() 1.文字类和小数类字符串,无法转化成整数 2.浮点数转成整数,抹0取整
float() 1.文字类无法转成浮点型,2.整数转为浮点型,末尾会加.0 3.小数类字符串可以转
13.注释
单行注释:以#开头,直到换行结束
多行注释:并没有单独的多行注释标记,将一对三引号之间的代码称为多行注释,不赋值给任何变量
中文编码声明注释:在文件开头加上中文声明,用于指定源码文件的编码格式
print('hello')
"""
我是懒羊羊,
我爱吃青草蛋糕
"""python默认的存储编码是utf-8
#coding:gbk
"""
我是懒羊羊,
我爱吃青草蛋糕
"""用记事本打开,另存为可以看到改为了
14.input函数的使用
作用:接收来自用户的输入·,结果是一个str类型
present=input('懒羊羊想要什么礼物呢?')
print(present)#从键盘中输入两个整数,计算两个整数的和
a=input('请输入一个加数:')
a=int(a)
b=input('请输入另一个加数:')
b=int(b)
print(a+b)
print('-'*30)
a=int(input('请输入一个加数:'))
b=int(input('请输入另一个加数:'))
print(a+b)15.运算符——算术运算符
标准算术运算符——加(+),减(-),乘(*),除(/),整除(//)
取余运算符——%
幂运算符——**
print(9//-4)#结果为-3,一正一负整除,向下取整
print(-9%4) # 3 -9-4*(-3)
print(9%-4) #-3 9-(-4)*(-3)
"""
看书
"""
16.赋值运算符
= 执行顺序:从右到左
支持链式赋值——a=b=c=20 #将20赋给 a,b,c,a=20,b=20.c=20
支持参数赋值——+=,-=,*=,/=,//=,%=
a=20 a+=30 #相当于a=a+30 print(a) #50 a-=10 #相当于a=a-10 print(a) #40 a*=2 #相当于a=a*2 a/=3 #相当于a=a/2 a//=2 #相当于a=a//2
支持系列解包赋值——a,b,c=20,30,40 a=20,b=30,c=40#等号左右个数相同都是3个
#交换两个变量的值 a,b=10,20 a,b=b,a
17. 比较运算符
对变量或表达式的结果进行大小,真假等比较;比较运算符的结果为bool类型
> ,< , >= , <=, !=
== “一个等号称为赋值运算符,两个等号称为比较运算符”
一个变量由三部分组成:标识,类型,值
== 比较的是值
比较对象的标识使用 is
a=10 b=10 print(a==b) #True 说明a与b的值相等 print(a is b) #True 说明a与b的ID标识相等 lst1 = [11,22,33,44] lst2 = [11,22,33,44] print(lst1==lst2) #true print(lst1 is lst2) #falseis not ID是不相等的
18.布尔运算符
对于布尔值之间的运算
and or not in not in
and 两个都是真,结果才为真
or 只要有一个为真,结果就为真
not 取反
f=True
print(not f)in 在不在当中
s='hello world'
print('w' in s)
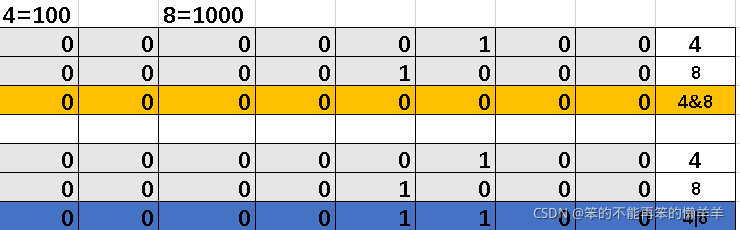
print('K' not in s)19.位运算符
将数据先转成二进制再进行计算
位与&——>对应位数都是1,结果数位才是1,否则为0
位或|——>对应位数都是0,结果数位才是0,否则为1
左移位运算符<< 高位溢出舍弃,低位补0
右移位运算符<< 低位溢出舍弃,高位补0
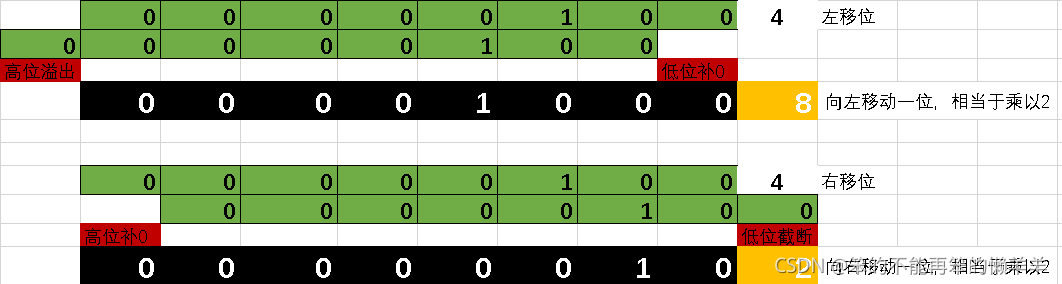
print(4<<1) #向左移动一个位置,相当于乘以2
print(4<<2) #向左移动两个位置
print(4>>1) #向右移动一个位置,相当于除以2
print(4>>2) #向右移动两个位置,相当于除以4
20.运算符的优先级
**
*,/,//,% 算术运算符:先算乘除再算加减,有幂最先
+,-
>> ,<<
& 位运算
I
> ,< ,>=,<=,==,!= 比较运算符 :结果true或者false
and
or 布尔运算
= 赋值运算
21.顺序结构
程序的组织结构:顺序结构,选择结构,循环结构
顺序结构:程序从上到下顺序的执行代码,中间没有任何的判断和跳转,直到程序的结束
22.对象的布尔值
python一切皆对象,所有的对象都有一个布尔值
获取对象的布尔值: 使用内置函数bool()
以下对象的布尔值为false
false 数值0 none 空字符串 空列表 空元组 空字典 空集合
#测试对象的布尔值
print(bool(False))
print(bool(0.0))
print(bool(None))
print(bool([])) #空列表【】
print(bool(list())) #空列表list()
print(bool(())) #空元组()
print(bool(tuple())) #空元组tuple()
print(bool({})) #空字典{}
print(bool(dict())) #空字典dict()
print(bool(set())) #空集合
其他对象的布尔值均为True
age=int(input("请输入你的年龄"))
if age:
print(age)
else:
print("年龄为:",age)23.分支结构
单分支结构
if 条件表达式:
条件执行体
money=1000 #余额
s=int(input('请输入取款金额')) #取款金额
#判断余额是否充足
if money>=s:
money=money-s
print('取款成功,余额为:',money)
双分支结构
if 条件表达式:
条件执行体1
else:
条件执行体2
#双分支结构
"""
从键盘录入一个整数,编写程序让计算机去判断是奇数还是偶数
"""
n=int(input("请输入一个整数"))
if n%2==0
print(n,'这是一个偶数')
else:
print(n,"这是一个奇数")多分支结构
if 条件表达式1:
条件执行体1
elif 条件表达式2:
条件执行体2
elif 条件表达式N:
条件执行体N
[else:]
条件执行体N+1
"""多分支结构,多选一执行
从键盘录入一个整数成绩
90-100 A
80-89 B
70-79 C
60-69 D
0-59 E
大于100或小于0 非法
0
"""
score=int(input("请输入一个成绩:"))
#判断
if 90<=score<=100 #python中可以这样写
print('A级')
elif score >=80 and score<=89
print("B级")
elif score >=70 and score<=79
print("C级")
elif score >=60 and score<=69
print("D级")
else
print("非法")嵌套IF
语法结构:
if 条件表达式1:
if 内层条件表达式:
内存条件执行体1
else
内存条件执行体2
else:
条件执行体
answer=input("您是会员吗?y/n")
money=float(input("请输入你的购物金额:"))
if answer=='y' : #会员
print("会员")
if money>=200:
print("打八折,付款金额为:",money*0.8)
elif money>=100:
print("打九折,付款金额为:",money*0.9)
else:
print("不打折,付款金额为:",money)
else: #非会员
print("非会员")
if money>=200:
print("打九五折,付款金额为:",money*0.95)
else
print("不打折,付款金额为:",money)
24.条件表达式
条件表达式是if.....else的简写
语法结构.
x if 判断条件 else y t条件执行正确,往前运行,错误往后运行
运算规则
如果判断条件的布尔值是True,条件表达式的返回值为x,否则条件表达式的返回值为False
"""
从键盘录入两个整数,比较两个整数的大小
"""
num_a=int(input('请输入第一个整数'))
num_b=int(input('请输入第二个整数'))
#比较大小
if num_a>=num_b:
print(num_a,"大于等于",num_b)
else:
print(num_a,'小于',num_b)
print('+'*30)
#使用条件表达式
print( print(num_a,"大于等于",num_b) if num_a>=num_b else (num_a,'小于',num_b) )
print( print(str(num_a)+"大于等于"+str(num_b) if num_a>=num_b else ....)
25.pass语句
语句什么都不做,只是一个占位符,用在语法上需要语句的地方
什么时候用:先搭建语法结构,还没想好代码怎么写的时候
if语句的条件执行体
for——in语句的循环体
定义函数时的函数体
answer=input("您是会员吗?y/n")
money=float(input("请输入你的购物金额:"))
if answer=='y' : #会员
pass
else: #非会员
pass
26.range函数
range(stop):创建一个[ 0,stop)之间的整数序列,步长为1
range(start,stop):创建一个[ start,stop)之间的整数序列,步长为1
range(start,stop,step):创建一个[ start,stop)之间的整数序列,步长为step
返回值是一个迭代器对象
r=range(10)
print(r) #range(0,10)查看不了
print(list(r)) #用于查看range对象中的整数序列range的优点:不管range对象表示的整数序列有多长,所有的range对象占用的内存空间都是相同的,因为仅仅需要存储star,stop和step,只有当用到range对象时,才会去计算序列中的相关元素
in 和not in 判断整数序列中是否存在(不存在)指定的整数
r=range(1,10,2)
print(10 in r)27.循环结构
while 条件表达式:
循环体(条件执行体)
当条件表达式的值为False的时候,退出循环
while是判断N+1次,条件为True执行N次
if是判断一次,条件为True执行一次
四布循环法:初始化变量 条件判断 条件执行体(循环体) 改变量
#计算1:10之间的累加和
"""初始化变量"""
a=0
sum=0
"""条件判断"""
while a<11
"""条件执行体"""
sum+=a
"""改变变量"""
a+=1
print("和为:",sum)
for-in循环
for 自定义的变量 in 可迭代对象:
循环体
in ——表示从(字符串,序列等)中依次取值,又称遍历
for-in遍历的对象必须是可迭代对象
for item in "Python": # p y t h o n
print(item)range()产生一个整数序列,也可以是一个迭代对象
for i in range(10):
print(i)
如果在循环体中不需要使用带自定义变量,可以将自定义变量写为''_''
for i in range(5):
print('救命啊,喜羊羊') #救命啊,喜羊羊将运行五次"""
输出100到999之间的水仙花数
举例:
153=3*3*3+5*5*5+1*1*1
***
for item in range(100,1000)
ge=item%10
shi=item//10%10 #多看看
bai=item//100
#print(ge,shi,bai)
if ge**3+shi**3+bai**3==item
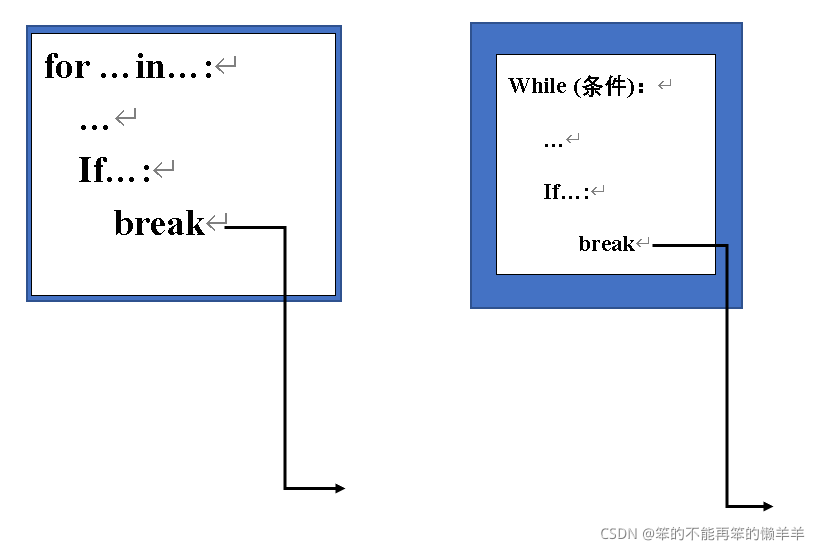
print(item)流程控制语句——break
用于结束循环结构,通常与分支结构if 一起使用
""" 从键盘录入密码,最多录入三次,如果正确就结束循环 """
for item in range(3):
pwd=input("请输入密码")
if pwd='8888'
print('密码正确')
break
else:
print('密码不正确')
a=0
while a<3:
pwd=input("请输入密码:")
if pwd='8888'
print('密码正确')
break
else:
print('密码不正确')
"""改变变量"""
a+=1
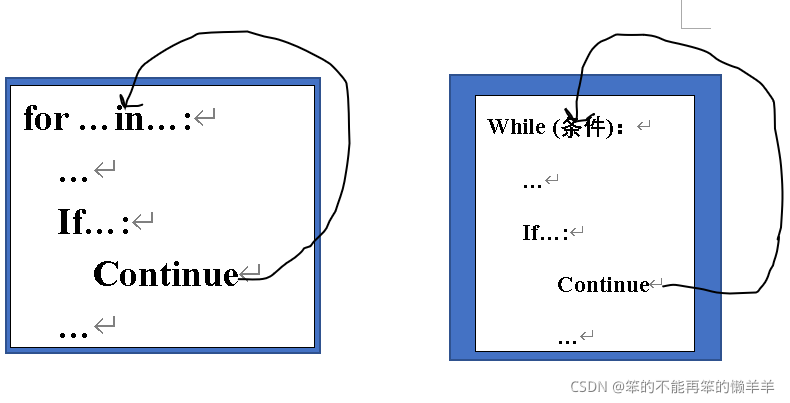
continue
用于结束当前循环,进入下一次循环,通常与分支if一起使用
""" 要求输出1到50之间的所有5的倍数"""
for item in range(1,51)
if item%5==0
print(item)
for item in range(1,51)
if item%5!=0
continue
print(item)28.else语句
else可以和if,while ,for搭配
for/while.....
....
else:
...
没有碰到break时执行else
for item in range(3):
pwd=input("请输入密码:")
if pwd=='8888'
print("密码正确")
break
else:
print("密码不正确")
else:
print ("对不起,三次密码均输入错误")
29.嵌套循环
在循环结构中又嵌套了另外的完整的循环结构,其中内层循环作为外层循环的循环体执行,
外层循环一次,内层循环一轮
"""输出一个三行四列的矩阵 """
for i in range(1,4) : #行数
for j in range(1,5):
print('*',end='\t') #不换行输出
print() #打行#9*9乘法表,第一行一个,第二行两个
for i in range(1,10):
for j in range(1,i+1):
print(i'*'j,'=',i*j,end='\t')
print()30.二重循环中的break和continue
二重循环中的break和continue用于控制本层循环
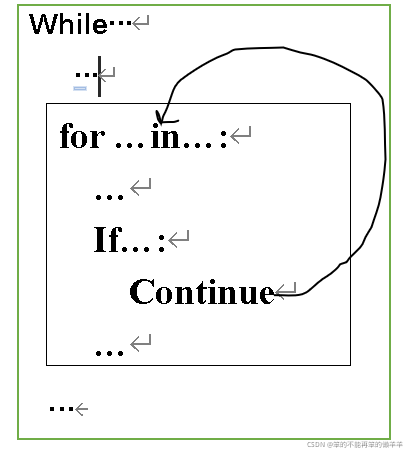

""" 流程控制语句break与continue在二重循环中的使用"""
for i in range(5): #代表外层循环要执行五次
for j in range(1,11):
if j%2==0:
break
print(j,end="\t")
#结果
1
1
1
1
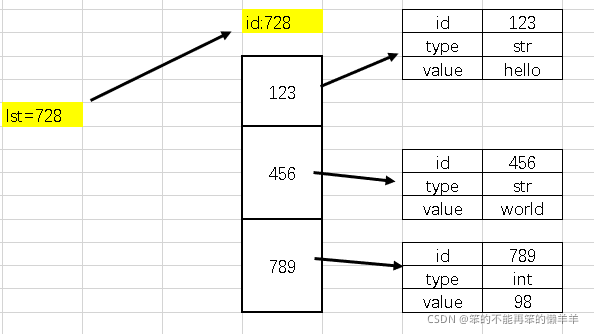
131.列表
变量可以存储一个元素,而列表是一个“大容器”可以存储N多个元素,程序可以方便地对这些数据进行整体操作
变量存储的是一个对象的引用(id)
list=['hello','world',98]
32.列表的创建
列表需要使用中括号【】,元素之间使用英文的逗号进行分隔
lst = ['l懒羊羊','喜欢','睡觉']
使用内置函数list()
lst2=list(['helo','world',98])
列表对象——赋给lst2 =id 987
ide:987 type:list value:'helo','world',98
列表的特点:
列表元素按顺序有序排列
索引映射唯一的数据
列表可以存储重复数据
任意数据类型混存
根据需要动态分配和回收内存——不用担心列表不够用

print(lst2[0],lst2[-3])
列表的查询操作
如果列表中存在N个相同元素,只返回相同元素中的第一个元素的索引
如果查询的元素在列表中不存在,则会抛出ValueError
还可以在指定的start和stop之间进行查找
lst=['hello','world',98,'hello']
print(lst.index('hello'))
#print(lst.index('python'))
print(lst.index('hello'.1,3)) #在'world',98,没有hello会报错
print(lst.index('hello',1,4)) #333.切片操作——获取列表中的多个元素
列表名[start:stop:step]
切片的结果:原列表片段的拷贝
切片的范围:[start,stop)
step默认为1 start默认是0 stop默认是最后一个元素(包含最后一个)
lst = [10,20,30,40,50,60,70,80]
print(lst[0:7])
print(lst[0::1])
"""
[10, 20, 30, 40, 50, 60, 70]
[10, 20, 30, 40, 50, 60, 70, 80]
"""lst = [10,20,30,40,50,60,70,80]
print(lst[1:6:1]) #[20 30 40 50 60]
print(lst[1:]) #[20 30 40 50 60 70 80]
切出来的是一个新的列表对象,ID不一样
step为负数,逆序
lst = [10,20,30,40,50,60,70,80]
print(lst[::-1]) #[80,70,60,50,40,30,20,10]
print(lst[7::-1]) #[80,70,60,50,40,30,20,10]
print(lst[6:0:-2]) #[70,50,30] 判断指定元素在列表中是否存在
lst=[10,20,'python','hello']
print(10 in lst)
print(10 not in lst)
列表元素的遍历
lst = [10,20,30,40,50,60,70,80]
for item in lst:
print(item)34.列表元素的增加操作
增加操作:
append() :在列表的末尾添加一个元素
extend() :在列表的末尾至少添加一个元素
insert() :在列表的任意位置添加一个元素
切片 :在列表的任意位置添加至少一个元素
lst = [10 ,20 ,30]
lst.append(100) #[ 10, 20, 30, 40],增加后的列表和原列表标识(ID)相同
lst2=['heelo','world']
lst.extend(lst2) #[10 ,20 ,30,'heelo','world']
lst=[10 ,20 ,30,'heelo','world']
lst.insert(1,90) #[10,90,20 ,30,'heelo','world']
lst=[10,90,20 ,30,'heelo','world']
lst3=[True,False,'hello'] #[10,True,False,'hello'] 切掉的部分用一个新的列表替换
lst[1:]=lst3 #从90开始切35.列表元素的删除操作:
remove() :一次删除一个元素 重复元素只删除第一个 元素不存在抛出ValueError
pop() :删除一个指定索引位置上的元素 指定索引不存在抛出ValueError,不指定索引,删除列表中最后一个元素
切片:一次至少删除一个元素
clear():清空列表
del 删除列表
lst = [10,20,30,40,50,60,30]
lst.remove(30)
print(lst)
lst.remove(3000)
print(lst)
lst = [10,20,30,40,50,60,30]
lst.pop(1)
lst.pop(10000)
lst.pop()
#切片,切片将会产生一个新的列表对象
lst=[10,40,50,60]
new_list=lst[1:3] #切片后的列表[40,50]
"""切片:不产生新的列表对象,而是删除原列表的内容"""
lst[1:3]=[]
print(new_list)
lst.clear()
print(lst) #[] 清除列表中的所有元素
'''del语句将列表对象删除'''
del lst
print(lst) #没有定义
36.列表元素的修改
为指定索引的元素赋予一个新值
为指定的切片赋予一个新值
lst=[10,20,30,40]
lst[2]=100 #[10,20,100,40]
lst[1:3]=[300,400,500,600] #[10,300,400,500,600,40]37.列表元素的排序操作
sort() :默认从小到大的顺序进行排序,也可以指定reverse=True,进行降序排序,排序是在原列表上进行的
sorted() :可以指定reverse=True,进行降序排序,原列表没有产生变化,而是产生了一个新的列表
lst=[20,40,50,10,98,5]
print("排序前的列表",lst,id(lst))
#开始排序
lst.sort() #等同 lst.sort(reverse==False)
print('排序后的列表',lst,id(lst)) #id没变,排序是在原列表上进行的
#指定关键字参数,进行降序排序
lst.sort(reverse==True)
print('排序后的列表',lst,id(lst)) #id没变,排序是在原列表上进行的
#使用内置函数sorted()对列表进行排序,将产生一个新的列表
lst=[20,40,50,10,98,5]
new_list=sorted(lst)
print(lst) #原列表没有产生变化,而是产生了一个新的列表
print(new_list)
#降序排列
desc_list=sorted(lst,reverse=True)
38.列表生成式
列表生成式简称:“生成列表的公式”
语法格式:
[ i *i for i in range(1,10)]
i*i:列表元素的表达式,列表中真正包含元素的值
lst=[i for i in range (1,10) ]
lst=[i*i for i in range (1,10) ]
lst=[i*2 for i in range (1,6) ]39.字典
字典与列表一样是一个可变序列【可以增删改】
以键值对的方式存储数据,字典是一个无序的序列 键:值
列表【】 字典{ }
第一个放入字典中的,不一定在字典中处于第一个位置,所以说它无序
hash(key)——>,把键放到hash(哈希函数)中进行计算得到的位置,放到字典中的键必须是不可变序列,不可变序列作为键的时候不管怎么动哈希值计算出来都是相同的。
整数序列和字符串序列都是不可变序列
字典的实现原理:与查字典类似,查字典是先根据部首或拼音查找相应的页码,python中的字典是根据key查找value所在位置
hash(key)——>value所在的位置
40.字典的创建
最常用的方式:使用花括号
scores={'懒羊羊':0 , '喜羊羊':100}
使用内置函数dict()
dict(name='jack',age=20)
dict(name='懒羊羊',age=8) #等号左侧是键,等号右侧是值空字典d={}
41.字典的增删改
key的判断 in:指定的key在字典中存在返回True
not in:指定的key在字典中不存在存在返回True
"""
键的判断
"""
scores={"懒羊羊":0,'喜羊羊':100}
print("懒羊羊" in scores)字典元素的删除
"""
字典元素的删除
"""
del scores=['喜羊羊']
scores['美羊羊']=80 #新增元素
scores['美羊羊']=90 #修改元素
scores.clear() #清空字典的元素
42.字典的视图操作
keys():获取字典中所有key
values():获取字典中所有Value
items():获取字典所有key,value对
keys=scores.keys() #字典键类型
print(list(keys))#将所有的key组成的视图转化为列表
values=scores.values() #字典值类型
print(list(values))
items=scores.items()
print(list(items))#列表中的每一个元素都是一个元组(‘懒羊羊’,100)43.字典元素的遍历
for item in scores :
print(item) #item是字典中的键
print(scores[item],scores.get(item)) #获取字典的值,第一个会抛异常,而另一个不会
44.字典的常用操作
字典中元素的获取
[]:举例scores['张三']
get()方法:举例scores.get("张三")
【】如果字典中不存在指定的key,抛出keyError异常
get()方法取值,如果字典中不存在指定的key,不会抛出异常而是返回None,可以通过参数设置默认的value,以便指定的key不存在时返回
scores={'懒羊羊':0,"喜羊羊":100}
scores['懒羊羊'] #0
scores.get('懒羊羊')
scores.get('美羊羊',99) #查找'美羊羊'所对的value不存在时,提共一个默认值9945.字典的特点
字典中的所有元素都是一个键值对,key不允许重复,value可以重复
字典中的元素是无序的
字典中的key必须是不可变对象
字典也可以根据需要动态地伸缩
字典会浪费较大的内存,是一种使用空间换时间的数据结构
d={'懒羊羊':'100','懒羊羊':0} #结果后面的0干掉了前面的100,懒羊羊0分,【key不允许出现重复】
d={'懒羊羊':'100','喜羊羊':100} #{'懒羊羊':'100','喜羊羊':100} value可以重复46.字典生成式
内置函数zip()
items=['Fruits','books','others']
prices=[96,78,85]
d={item:price for item,price in zip(items,prices)}
d={item.upper:price for item,price in zip(items,prices)} #变大写
items=['Fruits','books','others']
prices=[96,78,85,100,200] #以元素少的生成47.元组
元组是不可变序列
不可变序列:字符串,元组
不可变序列——没有增删改的操作
可变序列:列表,字典
可变序列:可以对序列执行增删改操作,对象地址不发生更改
元组的创建方式:
t=('python','hello',90) #这种方式小括号可以不写 t='python','hello',90
t=tuple('Python','hello',90)
只包含一个元组的元素需要使用逗号和小括号t=(10,) t=('懒羊羊',)#如果不加逗号会认为是本身的数据类型。
空元组的创建方式:t=() t5=tuple()
48.为什么要将元组设计成不可变序列
在多任务环境下,同时操作对象时不需要枷锁
因此,在程序中尽量使用不可变序列
可以看里面的数据,可以从里面拿数据,但是你不能对里面的数据进行修改,谁看都一样,不会对里面的内容进行破坏
注意事项:元组中存储的是对象的引用
(a):如果元组中对象本身是不可变对象,则不能再引用其他对象
(b):如果元组中的对象是可变对象,则可变对象的引用不允许改变,但数据可以改变。
t=(10,[20,30],9)
print(t)
print(type(t)) #元组
print(t[0],type(t[0]),id(t[0])) #整数
print(t[1],type(t[1]),id(t([1]))) #列表
print(id(100))
t[1]=100 #报错 元组不允许,修改元素
#但是 【20,30】是列表,列表是可变序列,所以可以向列表中添加元素,而列表的内存地址不变
t[1].append(100)
print(t) #不允许修改元组中元素的引用,但是你可以修改元素中可变对象的添加内容
49.元组的遍历
元组是可迭代对象,所以可以使用for...in进行遍历
t=tuple(('python','hello',90))
for item in t:
print(item)
50.集合
与列表,字典一样都属于可变类型的序列
集合是没有value的字典
直接{}
s={'python','hello',90}
s={2,3,44,44} #集合中的元素不允许重复,重复的会被去掉
使用内置函数set()
s1=set(range(6))
set(列表)
set((1,2,4,5,65)) #{65,1,2,4,5} 集合中的元素是无序的
set(字符串)
s=set('懒羊羊')
print(s,type(s)) #{'羊', '懒'} <class 'set'> 定义一个空集合
s={} ——>字典类型
set():这样才是一个空集合
51.集合的相关操作
集合元素的判断操作:in 或 not in
集合元素的新增操作:add(),一次添加一个元素
update()至少添加一个元素
s={10,20,40,60}
print(10 is s)
s.add('懒羊羊')
s.update({200,'灰太狼',0}) #放集合
s.update([200,100,0]) #放列表
s.update((200,100,0)) #放元组集合元素的删除操作:
一次删除一个指定元素
remove(),一次删除一个指定元素,如果指定的元素不存在抛出KeyError
discard(),一次删除一个指定元素,如果指定的元素不存在,不会抛出异常
s={10,20,40,60}
s.remove(10)
s.discard(500)一次只删除一个任意元素:pop(),不能添加参数
s={10,20,40,60} #随机删除一个元素,不能指定
s.pop()clear():清空集合
s.clear() :清空
52.集合之间的关系
两个集合是否相等:可以使用运算符==或!=进行判断(元素相同,就相等)
只要是内容相同,底部的存储顺序就是相同的{'懒羊羊','喜羊羊'}=={'喜羊羊','懒羊羊'}
一个集合是否是另一个集合的子集:issubset
s1={10,20,30,40,50,60}
s2={10,20}
print(s2.issubset(s1))
#True
一个集合是否是另一个集合的超集: issuperset
s1={10,20,30,40,50,60}
s2={10,20}
print(s1.issuperset(s2))
#True
两个集合是否没有交集:isdisjoint
s1={10,20,30,40,50,60}
s2={10,20,100,5000}
print(s1.isdisjoint(s2))
#False——有交集为FALSE
53.集合的数学操作
交集 ,并集,差集,对称差集
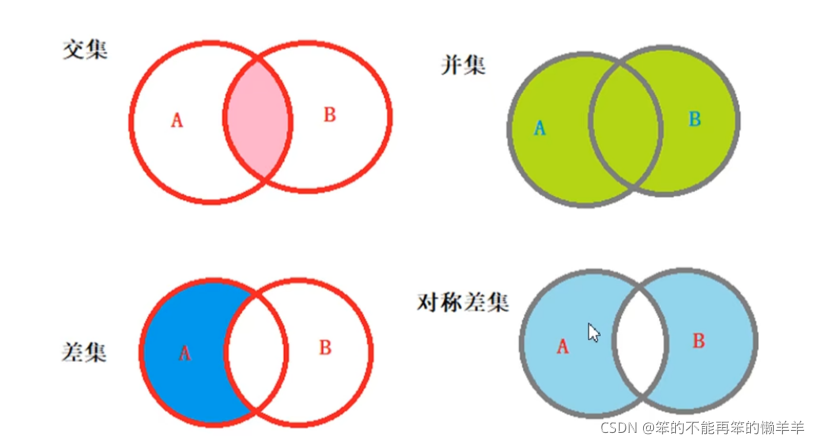
原集合不会发生变化
s1={10,20,30,40}
s2={20,30,40,50,60}
#交集intersection()与&等价
print(s1.intersection(s2))
print(s1 & s2)
print(s1)#不变
print(s2)#不变
#并集union()与|等价
print(s1.union(s2))
print(s1|s2)
#差集操作 dofference()与-等价
print(s1.dofference(s2)) #10
print(s1-s2)
#对称差集
print(s1.symmetric_difference(s2))
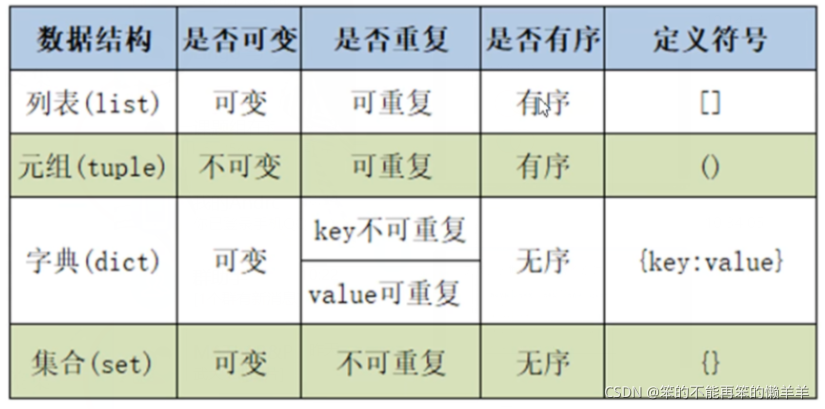
print(s1^s2) #{50,10,60}54.集合生成式
元组没有生成式
用于生成集合的公式:{i*i for i in range(1,10)}#将{}改为【】就是列表生成式
总结:
55.字符串的创建和驻留机制
字符串是一个不可变的字符序列
字符串的定义
a='python'
b="python"
c=""" python """ 这三个字符串的内存地址都是相同的字符串的驻留机制:仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同的字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量
驻留机制的集中情况:字符长度为0或1时
符合标识符的字符串(字母数字下划线)
字符串只在编译时进行驻留,而非运行时
【-5,256】之间的整数数字
强制驻留:sys中的intern方法强制2个字符串指向同一个对象
pycharm对字符串进行了优化处理
pycharm
s1='abc%'
s2='abc%'
print(s1 is s2)
#ture驻留机制的优缺点
当需要值相同的字符串时,可以直接从字符串池里拿来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是会比较影响性能的
在需要进行字符串拼接时建议采用str类型中的join方法,而非+,因为join()方法是先计算出所有字符串中的长度,然后再拷贝,只new一次对象,效率比+效率高
56.字符的常用操作
字符的查询
index():查找子串substr第一次出现的位置,如果查找的子串不存在时,则抛出Valueerror
rindex() : 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则抛出Valueerror
find():查找子串substr第一次出现的位置,如果查找的子串不存在时,则返回-1
rfind():查找子串substr最后一次出现的位置,如果查找的子串不存在时,则返回-1
s='喜羊羊,懒羊羊'
print(s.index('羊羊')) #1
print(s.find('羊羊')) #6| -7 | -6 | -5 | -4 | -3 | -2 | -1 |
| 喜 | 羊 | 羊 | , | 懒 | 羊 | 羊 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
字符串大小写转换
upper():全部转化成大写
lower() : 全部转成小写
swapcase() :大小写颠倒
capitalize():把第一个字符转成大写,其余字符转成小写
title():把每个单词的第一个字符转成大写,把每个单词的剩余字符转换为小写
s='hello,python'
a=s.upper()
print(a,id(a))
print(s,id(s)) #字符串是不可变序列,你改变后会产生一个新的字符串对象
b=s.lower()
print(b,id(b)) #转换之后,会产生一个新的字符串对象,值没变
print(b is s) #false
c='hello,Python'
print(c.swapcase()) #大小写互换
字符串内容对齐
center():居中对齐,第一个参数指定宽度,第二个参数指定填充符,第二个参数是可选的,默认是空格,如果设计宽度小于实际宽度则返回原字符串
s='hello,python'
print(s.center(20,'*'))![]()
ljust() 左对齐,第一个参数指定宽度,第二个参数指定填充符,第二个参数是可选的,默认是空格,如果设计宽度小于实际宽度则返回原字符串 右边打*
rjust()右对齐,.......,左边打***,字母右对齐
zfill()右对齐,左边用0填充,该方法只接受一个参数,用于指定 字符串的宽度,如果设计宽度小于实际宽度则返回原字符串
print('-8910'.zfill(8)) #-0008910字符串的分割
split():从左边开始分割,默认的分割字符是空袼字符串,返回值是一个列表
通过参数sep指定分割字符串的分隔符
通过参数maxsplit指定分割字符串时的最大分割次数,在经过最大分割之后,剩余的子串会单独做为一部分
s1='hello|world|python'
print(s1.split(sep='|')) #['hello', 'world', 'python']
print(s1.split(sep='|',maxsplit=1)) #['hello', 'world|python']rsplit()从字符串的右侧分割
判断字符串操作的方法
isidentifier():判断指定的字符串是不是合法的标识符
s='hello,python'
print(s.isidentifier()) #FAlse,合法的标识符(字母,数字,下划线)isspace():判断指定的字符串是否全部由空白字符组成(回车,换行,水平制表符)
isalpha():判断指定字符串是否全部由字母组成 ( ‘懒羊羊’也是全部由字母组成)
isdecimal():判断指定字符串是否全部由十进制的数字组成(罗马数字VII不是)(’123四‘不是)
isnumeric():判断指定的字符串是否全部由数字组成(’123四‘是)(罗马数字VII是)
isalnum():判断指定字符串是否全部都由字母和数字组成
字符串的替换replace() 第一个参数指定被替换的子串,第二个参数指定替换子串的字符串,,第三个参数指定最大的替换次数,替换前的字符串不发生变化
s='hello python'
print(s.replace('python','C语言')) #hello c语言
print(s) #hello python
s1='hello python python'
print(s.replace('python','C语言',2)) #hello c语言 c语言字符串的合并 join(),将列表或元组中的字符串合并成一个字符串
lst=['hello','java','python'] lst=('hello','java','python')
print('|'.join(lst))
print(''.join(lst))
#hello|java|python
hellojavapythonprint('*'.join('python')) #它把python作为字符串序列进行一个连接
# p*y*t*h*o*n
字符串的比较操作:
>,<, >=,<=,==,!=
比较规则:首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较
比较原理:两个字符进行比较时,比较的是其ordinal value(原始值),调用内置函数ord可以指定字符的ordinal value。与内置函数ord对应的内置函数chr,调用内置函数chr时指定ordinal value可以得到其对应的字符
print('apple'>'app')print(ord('a'),ord('b')) #97 98
print(chr(97)) #a
print(ord('懒')) #25042
print(chr(25042)) #懒"""==与is的区别"""
==比较的value
is 比较的是id是否相等
字符串的切片操作
字符串是不可变类型:不具备增删改等操作,切片操作将产生新的对象
切片[start:end:step]
s='hello,python'
s1=s[:5] #hello,没指定其实位置,从0开始
s2=s[6:] #python 由于没有指定结束位置,所以切到字符串的最后一个元素
s3="!"
str=s1+s3+s2 #hello!python
s[-6::1] #python
s1 s2 s3 str四个ID都不同
s='hello,python'
s1=s[-1:-5:-1]
print(s1)
#noht57.格式化字符串
按一定格式输出的字符串
格式化字符串的两种方式
%: %s——字符串 %i或者%d——整数 %f——浮点数
name='懒羊羊'
age=8
print('我叫%s,今年%d' % (name,age))
|
|
固定符号{}
'我的名字叫;{0},今年{1},我真的叫:{0}'.format(name,age)
#标0使用format中的第一个位置的数,标1使用format中的第二个位置的数f-string
name='懒羊羊'
age=8
print(f'我叫{name},今年{age}岁')表示精度和宽度
print('%10d' % 99) #10-表示的是宽度
print('%f' % 3.1415926) #3.141593
print('%.3f' % 3.1415926) #保留三位小数
print('%10.3f' % 3.1415926) %宽度是10,保留三位小数58.字符串的编码转换
编码与解码的方法
编码:将字符串转换为二进制数据(bytes)
解码:将bytes类型的数据转换成字符串类型
s='朝闻道'
#编码
print(s.encode(encoding='GBK')) #GBK编码格式中一个中文占两个字节
#b'\xb3\xaf\xce\xc5\xb5\xc0' b——表示二进制的意思
print(s.encode(encoding='utf-8')) #utf-8,一个中文占三个字节
#解码
byte=s.encode(encoding='GBK') #编码
print(byte.decode(encoding='GBK')) #encoding='GBK'解码的类型 byte代表的就是一个二进制数据(字节类型数据)
'''编码格式和解码格式要相同'''59.函数的创建和调用
为什么要需要函数:重复使用代码,隐藏实现细节,提高可维护性,提高可读性便于调试
函数的创建: def 函数名([输入函数])
函数体
[renturn xxx]
#函数的创建
def calc(a,b):
c=a+b
return c
函数的调用
result=calc(10,20)
print(result)
60.函数的参数传递
上面的代码 a,b占了两个实际变量的位置——形参,形参的位置是在函数的定义处
calc(10,20) #10,20称为实际参数值,称为实参,实参的位置是函数的调用处
位置实参:根据形参对应的位置进行实参传递,一个萝卜一个坑
关键字实参:根据形参名称进行实参传递
calc(b=10,a=20) # =左侧的变量的名称称为关键字参数
def calc(a,b):
内存分析:形参和实参的参数名称可以不相同
在函数调用过程中,进行参数的传递:如果是不可变对象,在函数体的修改不会影响实参的值;
如果是可变对象,在函数体的修改会影响实参的值
def fun(arg1, arg2):
print('arg1', arg1)
print('arg2', arg2)
arg1 = 100
arg2.append(10)
print('arg1', arg1)
print('arg2', arg2)
n1 = 11
n2 = [22, 33, 44]
print('n1', n1)
print('n2', n2)
fun(n1, n2)
print('n1', n1)
print('n2', n2)n1 11
n2 [22, 33, 44]
arg1 11
arg2 [22, 33, 44]
arg1 100
arg2 [22, 33, 44, 10]
n1 11
n2 [22, 33, 44, 10]进程已结束,退出代码 0
61.函数的返回值
函数返回多个值时,结果为元组
def fun(num):
odd=[]#存奇数
even=[]#存偶数
for i in num:
if i%2:
odd.append(i)
else:
even.append(i)
return odd,even
print(fun([10,29,34,23,44,56,59]))([29, 23, 59], [10, 34, 44, 56])
1.如果函数没有返回值,【函数执行完毕之后,不需要给调用处提供数据】,return可以省略不写
2.函数的返回值,如果是一个,直接返回原类型:你是列表我就是列表,你是实数我就是实数
3.函数的返回值,如果是多个,返回的结果为元组
def fun1()
print('青草蛋糕')
fun1def fun2():
return 'hello'
res=fun2()
print(res)
def fun3()
return 'hello','world'
print(fun3())函数在定义时,是否需要返回值,视情况而定
62.函数的参数定义
函数定义时,给形参设置默认值,只有与默认值不符的时候才需要传递实参
def fun(a,b=10)
print(a,b)
#函数的调用
fun(100) #(100,10)
fun(20,30) #(20,30)63.函数的参数定义
个数可变的位置参数
定义函数时,可能无法事先确定传递的位置实参的个数时,使用可变的位置参数
使用*定义个数可变的位置形参
结果为一个元组
def fun(*args):
print(arges)
fun(10)
fun(10,20,30)
(10,)
(10,20,30)
def fun2(*a,*b)
pass
#程序会报错,个数可变的位置参数,只能是1个个数可变的关键字形参
定义函数时,无法事先确定传递的关键字实参的个数时,使用可变的关键字形参
使用**定义个数可变的关键字形参
结果为一个字典
def fun(**args):
print(args)
fun(a=10)
fun(a=10,n=20,c=30)
{'a': 10}
{'a': 10, 'n': 20, 'c': 30}
def fun2(**a,**b)
pass
#程序会报错,个数可变的关键字参数,只能是1个在一个函数的定义过程中,既有个数可变的关键字形参,也有位置可变的位置形参,要求,个数可变的位置形参,放在个数可变的关键字形参之前
函数的参数总结
def fun(a,b,c):
print('a=',a)
print('b=',b)
print('c=',c)
fun(10,20,30)#函数调用时的参数传递,称为位置传参 a=10,b=20,c=30
lst=[11,22,33]
fun(lst) #程序报错,你有三个参数,你只传了一个
fun(*lst) #在函数调用时,将列表中的每个元素都转换为位置实参传入
fun(a=100,c=300,b=200)#函数的调用,所以是关键字实参
dict={"a":111,"b":222,"c":333}
fun(**dic) #在函数的调用时,将字典中的键值对都转换为关键字实参传入
def fun(a,b=10) : #b是在函数的定义处,所以b是形参,而且进行了赋值,所以b称为默认值形参
print('a=',a)
print('b=',b)
def fun2(*arges): #个数可变的位置形参
print(arges)
def fun2(**arges): #个数可变的关键字形参
print(arges)
def fun4(a,b,c,d):
print('a=',a)
print('b=',b)
print('c=',c)
print('d=',d)
fun4(10,20,30,40)#位置实参传递
fun4(a=10,b=20,c=30,d=40)#关键字实参传递
fun4(10,20,c=30,d=40)#混用
"""c,d只能采用关键字实参传递"""
def fun4(a,b,*,c,d): #从*之后的参数,在函数调用时,只能采用关键字参数传递
print('a=',a)
print('b=',b)
print('c=',c)
print('d=',d)
''' 函数定义时的形参的 顺序问题'''
def fun5(a,b,*,c,d,**args)
pass
def fun5(*args1,**args2)
pass
def fun5(a,b=10,*args1,**args2)
pass
64.变量的作用域
局部变量:在函数内定义并使用的变量,只在函数内部有效,局部变量使用global声明,这个变量实际上就变成了全局变量
全局变量:函数体外定义的变量,可作用于函数内外
def fun(a,b)
c=a+b #c,就称为局部变量
print(c)
print(c)#报错,c超出了起作用的范围
name="懒羊羊" #name为全局变量
print(name)
def fun2():
print(name)
#调用函数
fun2()
def fun3():
global age#局部变量使用global声明,这个变量实际上就变成了全局变量
age=20
print(age)
fun3()
print(age)65.递归函数
如果一个函数的函数体内调用了该函数本身,这个函数就称为递归函数
递归的组成部分:递归调用与递归终止条件
递归的调用过程:每递归调用一次函数,都会在栈内存分配一个栈帧
每执行完一次函数,都会释放相应的空间
递归的优缺点: 缺点——占用内存多,效率低下
优点——思路和代码简单
def fac(n):
if n==1:
return 1
else:
return n*fac(n-1)
print(fac(7)) #7的阶乘def fid(n):
if n==1:
return 1
elif n==2:
return1
else:
renturn fib(n-1)+fid(n-2)
#斐波那契数列
print(fid(6))
#输出这个数列的前六位上的数字
for i in range(1,7)
print(fib(i))66.bug
debug:排除bug
思路不清:使用print()函数,或#暂时注释部分代码
异常处理机制:
多个except结构捕获异常,先子类后父类的顺序
try:
a=int(input('请输入第一个整数'))
b=int(input('请输入第二个整数'))
result=(a/b)
print('结果为:'result)
except ZeroDivisionError: #不允许被0除的异常,子
print('除数不允许为0')
except ValueError:
print('只能输入数字串')
print('程序结束')67.try...except...else结构
如果try块没有抛出异常,则执行else块,如果try中抛出异常,则执行except块
try: a=int(input('请输入第一个整数')) b=int(input('请输入第二个整数')) result=(a/b) print('结果为:'result) except BaseException as e: print('出错了') print(e) else: print('结果为:',result)
try...except...else...finally:finally块无论是否发生异常都会被执行,常用来释放try块中申请的资源
try:
a=int(input('请输入第一个整数'))
b=int(input('请输入第二个整数'))
result=(a/b)
except BaseException as e:
print('出错了')
print(e)
else:
print('结果为:',result)
finally:
print('无论是否产生异常,总会被执行的代码')
print('程序结束')68.常见的异常类型
ZeroDivisionError——除0异常
IndexError——序列中没有此索引
KeyError——映射中没有这个键
NameError——未声明对象
SyntaxError——python语法错误
int a=20
ValueError——传入无效的参数
a=int('hello')
69.traceback模块
使用traceback模块打印异常信息
#print(10/0)
import traceback
try:
print('_____________________')
print(1/10)
except:
traceback.print_exc()调试模块:小虫子,红色当前执行,蓝色下一步要执行
70.面向对象
| 面向过程 | 面向对象 | |||||||
| 区别 | 事物比较简单,可以用线性的思维去解决 | 事物比较复杂,使用简单的线性思维无法解决 | ||||||
| 共同点 | 面向过程和面向对象都是解决实际问题的一种思维方式 | |||||||
| 二者相辅相成,并不是对立的 | ||||||||
| 解决复杂问题,通过面向对象方式便于我们从宏观上把握事物之间的复杂的关系, | ||||||||
| 方便我们分析整个系统;具体到微观操作,仍然使用面向过程方式来处理 。 | ||||||||
71.类的创建
创建类的语法
class Student: #Student为类的名称(类名)由一个或多个单词组成,每个单词的首字母大写,其 pass 余小写
对象 :ID 类型 值
print(id(Student))
print(type(Student))
print(Student)
有值,类对象
类的组成:类属性,实例方法,静态方法,类方法
class Student:
native_pace='陕西' #直接写在类面的变量,称为类属性
def_init_(self,name,age):
self.name=name #self.name称为实例属性,进行了一个赋值的操作
self.age=age
#实例方法 #在类之外定义的称为函数,在类之内定义的称为方法
def eat(self):
print('青草蛋糕')
#类方法
@classmethod
def cm(cls):
print("类方法")
#静态方法
@staticmethod
def sm(): ——这里面不允许写self
print('静态方法')72.对象的创建(类的实例化)
语法: 实例名=类名()
#创建Student类的对象
stu1=Student('张三',20)
stu1.eat() == Student.eat(stu1) #对象名.方法名 = 类名.方法名(类的对象)
print(stu1.name)
print(stu1.age)
print(id(stu1))
print(stu1)
print(type(stu1))
print('-'*30)
print(id(Student))
print(Student)
print(type(Student))73.类属性,类方法,静态方法
类属性:类中方法外的变量称为类属性,被该类的所有对象所共享
print(Student.native_pace)
stu1=Student('懒羊羊',0)
print(Stu1native_pace)
Student.native_pace='大肥羊学校'
print(Stu1native_pace)
print(Student.native_pace)类方法:使用@classmethod修饰的方法,使用类名直接访问的方法
Student.cm()静态方法:使用@staticmethod修饰的方法,使用类名直接访问的方法
Student.sm()74.动态绑定属性和方法
python是动态语言,在创建对象之后,可以动态地绑定属性和方法
class Student:
def _init_(self,name,age)
self.name=name
self.age=age
def eat(self):
print(self.name+'在吃饭')
stu1=Studeng('懒羊羊',8)
stu2=Studeng('喜羊羊',9)
一个Student类可以创建N多个Student类的实例对象,每个实例对象的属性值不同(name,age)
只想给stu1添加一个青草蛋糕,不给stu2添加
print('-----为stu1动态绑定性别属性-----') stu1.food='青草蛋糕' print(stu1.name,stu1.age,stu1.food) print(stu2.name,stu2.age)print('---------------') stu1.eat() stu2.eat() def show(): print('定义在类之外的,称为函数') stu1.show=show stu1.show() stu2.show()#会报错,这个没有绑定show方法,stu1.show=show这里叫方法类属性,类方法,静态方法都是类名打点使用的 对象名.方法名 )
实例方法 对象名.方法名 = 类名.方法名(类的对象) 这里有self,self就是Student的类对象
75.面向对象的三大特征
封装:提高程序的安全性
将数据(属性)和行为(方法)包装到类对象中。在方法内部对属性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔离复杂度
在python中没有专门的修饰符可用于属性的私有,如果该属性不希望在类对象外部被访问,前面使用两个"_"
class Student:
def __init__(self,name,age):
self.name=name
self.__age=age
def show(self):
print(self.name,self.__age)
stu=Student('懒羊羊',8)
stu.show()
#在类的外面使用name与age
#print(stu.__age)
#查看stu的所有属性和方法
print(dir(stu))
print(stu.Student__age) #8被获取到了继承:提高代码的复用性
class 子类类名(父类1,父类2...);
pass
如果一个类没有继承任何类,则默认继承object
python支持多继承——父类可以写多个
定义子类时,必须在其构造函数中调用父类的构造函数
class Person(object):
def __init__(self,name,age):
self.name=name
self.age=age
def info(self):
print(self.name,self.age)
class Student(Person):
def __init__(self,name,age,stu_id):
super().__init__(name,age)
self.stu_id=stu_id
class Teacher(Person):
def __init__(self,name,age,teachofvear):
super().__init__(name,age)
self.teachofvear=teachofvear
stu=Student('懒羊羊',8,1010103)
teacher=Teacher('慢羊羊',50,30)
stu.info()
teacher.info()懒羊羊 8
慢羊羊 50class A(object):
pass
class B(object):
pass
class C(A,B):
pass
object()有两个子类A,B,C类继承了A和B,C有两个父类A和B方法重写:
如果子类对继承自父类的某个属性或方法不满意,可以在子类中对其(方法体)进行重新编写
子类重写后的方法中可以通过suoer().XXX()调用父类中被重写的方法
class Person(object):
def __init__(self,name,age):
self.name=name
self.age=age
def info(self):
print(self.name,self.age)
class Student(Person):
def __init__(self,name,age,stu_id):
super().__init__(name,age)
self.stu_id=stu_id
def info(self):
super().info() #调用父类的方法
print(stu_id)
class Teacher(Person):
def __init__(self,name,age,teachofvear):
super().__init__(name,age)
self.teachofvear=teachofvear
stu=Student('懒羊羊',8,1010103)
teacher=Teacher('慢羊羊',50,30)
stu.info()
teacher.info()object类 :object类是所有类的父类,因此所有类都有object类的属性和方法
内置函数dir()可以查看指定对象所有属性
Object有一个__str__()方法,用于返回一个对于‘对象的描述’,对应于内置函数str()经常用于print()方法,帮助我们查看对象的信息,所以我们经常会对__str__()进行重写
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def __str__(self):#重写父类的方法
return '我的名字是{0},今年{1}岁了'.format(self.name,self.age)
stu=Student('懒羊羊',8)
print(dir(stu)) #不会输出对象的内存和地址了,而是调用__str__函数
print(stu) #默认调用__str__()这样的方法
print(type(stu))
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'age', 'name']
我的名字是懒羊羊,今年8岁了
<class '__main__.Student'>多态:提高程序的可扩展性和可维护性
多态就是‘具有多种形态’,它指的是:几遍不知道一个变量所引用的对象到底是什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型,动态决定调用哪个对象中的方法
class Animal(object):
def eat(self):
print('动物会吃')
class Dog(Animal):
def eat(self):
print('狗吃骨头')
class Cat(Animal):
def eat(self):
print('猫吃鱼')
class Person():
def eat(self):
print('人吃五谷')
#定义一个函数
def fun(obj):
obj.eat()
#开始调用函数
fun(Cat())
fun(Dog())
fun(Animal())
print('++++++')
fun(Person())
猫吃鱼
狗吃骨头
动物会吃静态语言实现多态的三个必要条件:继承,方法重写,父类引用指向子类对象----Java
动态语言的多态崇尚‘鸭子类型’当看到一直鸟走起来像鸭子,游起来像鸭子,那么这只鸟就可以被称为鸭子。在鸭子类型中,不需要关心对象是什么类型,到底是不是鸭子,只关心对象的行为——python
76.特殊方法和特殊属性
特殊属性 __dict__ 获取类对象或实例对象所绑定的所有属性和方法的字典
#print(dir(object))
class A:
pass
class B:
pass
class C(A,B):
def __init__(self,name):
self.name=name
#创建C类的对象
x=C('WXH') #X是C类型的一个实例对象
print(x.__dict__)
#
{'name': 'WXH'} name属性#实例对象的属性字典
print(C.__dict__)#类对象,可以看到属性和方法
#{'__module__': '__main__', '__init__': <function C.__init__ at 0x0000024A0BF5A840>, '__doc__': None}
print(x.__class__) #对象所属的类
print(C.__bases__) #C类的父类的元组,(<class '__main__.A'>, <class '__main__.B'>)
print(C.__base__) #根C离得最近的父类出来
print(C.__mro__)#查看类的层次结构
#(<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>)
print(A.__subclasses__()) #获取A的子类的列表特殊方法
__len__() 通过重写__len__()方法,让内置函数len()的参数可以是自定义类型
__add__()通过重写__add__()方法,可使自定义对象具有“+”功能
__new__()用于创建对象
__init__()对创建的对象进行初始化
a=20
b=100
c=a+b #两个整数类型的对象的相加操作
d=a.__add__(b)
print(c,d)
class Student:
def __init__(self,name)
self.name=name
def __add__(self,other):
return self.name+other.name 1
def __len__(self):
return len(self.name)
stu1=Student('懒羊羊')
stu2=Student('喜羊羊')
s=stu1+stu2 #没有1def会报错
s=stu1.__add(stu2)
print('---------')
lst=[1,2,5,8]
print(len(lst)) #4
print(lst.__len__()) #4
print(len(stu1))
__new__和__init__
class Person(object):
def __new__(cls, *args, **kwargs):
print('__new__被调用执行了,cls的id值为{0}'.format(id(cls)))
obj=super().__new__(cls)
print('创建的对象的id为:{0}'.format(id(obj)))
return obj
def __init__(self,name,age):
print('__init__被调用了.self的id值为:{0}'.format(id(self)))
self.name=name
self.age=age
print('object这个类对象的ID为:{0}'.format(id(object)))
print('Person这个类对象的ID为:{0}'.format(id(Person)))
#创建Person类的实例对象
p1=Person('懒羊羊',8)
print('p1这个Person类的实例对象的id:{0}'.format(id(p1)))77.类的浅拷贝与深拷贝
变量的赋值操作:只是形成两个变量,实际上还是指向同一个对象
浅拷贝:python拷贝一般都是浅拷贝,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
深拷贝:使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同。
class CPU:
pass
class Disk:
pass
class Computer:
def__init__(self,cpu,disk)
self.cpu=cpu
self.disk=disk
#变量的赋值
cpu1=CPU()
cpu2=cpu1
print(cpu1)
print(cpu2)
#类的浅拷贝
disk=Disk() #创建一个硬盘类的对象
computer=Computer(cpu1,disk) #创建一个计算机类的对象
#浅拷贝
import copy
computer2=copy.copy(computer)
print(computer,computer.cpu,computer.disk)
print(computer2,computer2.cpu,computer2.disk)
#深拷贝
computer3=copy.deepcopy(computer)
print(computer,computer.cpu,computer.disk)
print(computer3,computer3.cpu,computer3.disk)78.模块
一个模块中可以包含N多个函数
使用模块的好处:方便其他程序和脚本的导入并使用,避免函数名和变量名冲突,提高代码的可维护性,提高代码的可重用性
在python中一个扩展名为.py的文件就是一个模块——函数,类,语句
79.自定义模块和模块的导入
创建模块:新建一个.py文件,名称尽量不要与Python自带的标准模块名称相同
导入模块:
import 模块名称 [as 别名]
from 模块名称 import 函数/变量/类
import math#数学运算
print(id(math))
print(type(math))
print(math)
print(math.pi)
print('-----------------')
print(dir(math))from math import pi
print(pi)
print(pow(2,3))#报错,你只是导入math里的pi,你并没有导入math
自己定义的模块导入
#calc.py
def add(a,b):
return a+b
def div(a,b):
return a/b
#如何区导入自定义模块#导入calc自定义模块使用
import calc
print(calc.add(10,20))
print('-'*30)
from calc import add
print(add(10,20))80.以主程序形式运行
在每个模块的定义中都包括一个记录模块名称的变量__name__,程序可以检查该变量,以确定他们在哪个模块中执行。如果一个模块不是被导入到其他程序中执行,那么它可能在解释器的顶级模块中执行。顶级模块的__name__变量的值为__main__
#calc2.py
def add(a,b):
return a+b
print(add(10,20))import calc2
print(calc2.add(100,200))
#30
300#calc2
def add(a,b):
return a+b
if __name__=='__main__' #主程序时运行
print(add(10,20)) #只有当点击calc2时,才会被执行运算81.python中的包
包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下
作用:代码规范,避免模块名称冲突
包与目录的区别:
包含__init__.py文件的目录称为包
目录里通常不包含_init__.py文件
python程序:包 , 包里面又有好多模块
包的导入: import 包名.模块名
#在demo8的模块中导入pageage1包
import pageage1.module_A
print(pageage1.module_A.a)
print('等同')
import pageage1.module_A as ma #别名
print(ma.a)导入带有包的模块时注意事项
import pageage1
import calc
#使用import方式进行导入时,只能跟包名或模块名
from pageage1 import module_A
from pageage1.module_A import a
#使用from...import可以导入包,模块,函数,变量82.常用的内置模块
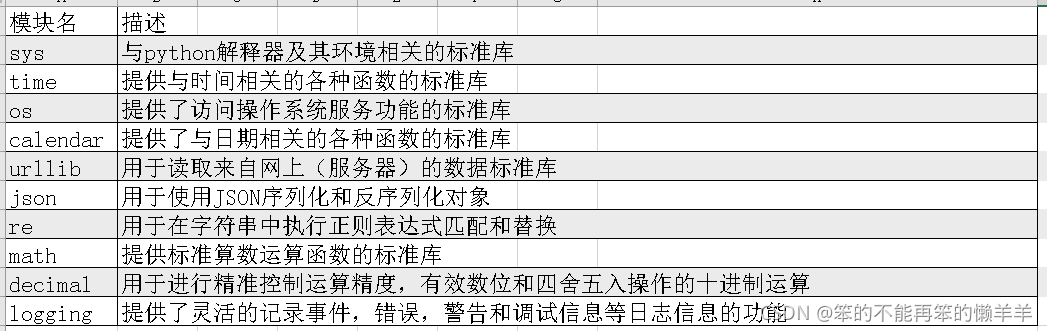
83.编码格式
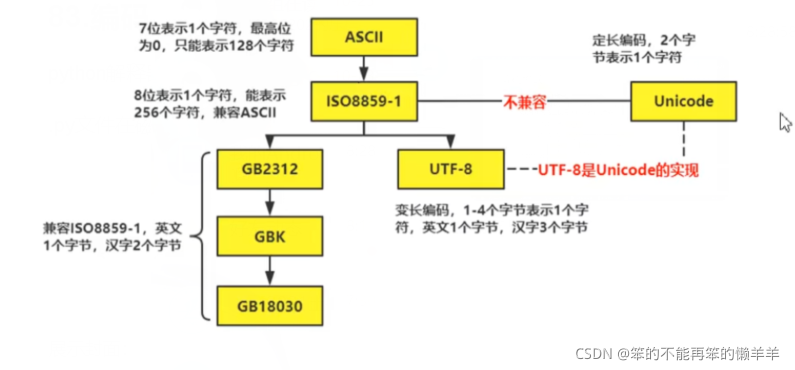
python解释器使用的是Unicode(内存)
.py文件在磁盘上使用UTF-8存储(外存)
84.文件的读写原理
文件的读写俗称“IO操作” ——(input,output)——先进先出(管流)
.py文件——>解释器去执行——>调用OS操作系统的资源——>操作硬盘
内置函数open()创建文件对象——通过IO流将磁盘文件
通过IO流将磁盘文件中的内容与程序中的对象中的内容进行同步
file=open(filename ,[mode,encoding])——mode打开模式默认为只读,encoding——默认文本文件中字符的编写格式为gbk
r-读
file=open('a.txt','r')
print(file.readlines()) #结果是一个列表
file.close()85.常用的文件打开模式
文件的类型
文本文件:存储的是普通“字符”文本,默认为unicode字符集,可以使用记事本程序打开
二进制文件:把数据内容用“字节”进行存储,无法用记事本打开,必须用专用的软件打开,例如"mp3音频文件,jpg图片,.doc文件"
| 打开模式 | 描述 |
| r | 以只读模式打开文件,文件的指针将会放在文件的开头 |
| w | 以只读模式打开文件,荣光文件不存在则创建,如果文件存在,则覆盖原有内容,文件的指针将会放在文件的开头 |
| a | 以追加模式打开文件,如果文件不存在则创建,文件指针在文件的开头;如果文件存在,则在文件末尾追加内容,文件指针在原文件末尾 |
| b | 以二进制方式打开文件,不能单独使用,需要与其他模式一起使用,rb或者wb |
| + | 以读写方式打开文件,不能单独使用,需要与其他模式一起使用,a+ |
src_file=open('logo,png','rb')#读
target_file=open('copylogo.png','wb')#写
target_file.write(src_file.read())
target_file.close()
src_file.close()
86.文件对象的常用方法
| 方法名 | 说明 | ||||||
| read([size]) | 从文件中读取size个字节或字符的内容;若省略[size],则读取到文件末尾,即一次读取文件所有内容。 | ||||||
| readline() | 从文本文件中读取一行内容 | ||||||
| readlines() | 把文本文件中的每一行都作为独立的字符串对象,并将这些对象放入列表返回 | ||||||
| write(str) | 将字符串str内容写入文件 | ||||||
| writelines(s_list) | 将字符串列表s_list写入文本文件,不添加换行符 | ||||||
| seek(offse,[whence]) | 把文件指针移动到新的位置 offset表示相对于whence的位置: offset:为正往结束方向移动,为负往开始方向移动 whence不同值代表不同含义
| ||||||
| tell() | 返回文件指针的当前位置 | ||||||
| flush() | 把缓冲区的内容写入文件,但不关闭文件 | ||||||
| close() | 把缓冲区的内容写入文件,并关闭文件,释放文件对象相关资源 |
file=open('a.txt','r')
print(file.read())
print(file.readlines())
file.colse
file=open('c.txt','a')
file.write('懒羊羊')
lst=['懒羊羊','喜羊羊','沸羊羊']
file.write(lst)
file.close()file=open('a.txt','r')
file.seek(2) #一个中文占两个字节
print(file.read())
print(file.tell())
file.closewith语句可以自动管理上下文资源,不论什么原有跳出with块,都能确保文件正确的关闭,以此达到释放资源的目的
with open('a.txt','r') as file:
print(file.read())
# open('a.txt','r') 上下文表达式:结果是上下文管理器lyy实现了特殊方法__enter__(),__exit__()称为该类对象遵守了上下文管理器协议,该类对象的实例对象,称为上下文管理器
with lyy() as file: 相当于file=lyy()
file.show()
with open('logo.png','rb')as src_file:
with open('copy2logo.png','wb') as t_file:
t_file.write(src_file.read())87. 目录操作:
os模块时python内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关
import os
#os模块与操作系统相关的一个模块
os.system('noteoad.exe')#打开记事本
os.system('calc.exe')#打开计算器
#直接调用可执行文件
os.startfile("D:\\Tencent\\QQ\\Bin\\QQ.exe")| 函数 | 说明 |
| getcwd() | 返回当前的工作目录 |
| listdir(path) | 返回指定路径下的文件和目录信息 |
| mkdir(path,[mode]) | 创建目录 |
| mkdirs(path1/path2...,[mode]) | 创建多级目录 |
| remdir(path) | 删除目录 |
| removedirs(path1/path2...) | 删除多级目录 |
| chdir(path) | 将path设置为当前工作目录 |
import os
print(os.getcwd())
#C:\Users\hff\PycharmProjects\untitled15
lst=os.listdir('../chap15') #..返回上级目录
print(lst)
os.mkdir('lyy')
os.makedirs('A/B/C')#在当前文件夹下创建A,A里有B,B里有C
os.removedirs("A/B/C")#删除A/B/C
88.os.path模块操作目录相关函数
| 函数 | 说明 |
| abspath(path) | 用于获取文件或目录的绝对路径 |
| exists(path) | 用于判断文件或目录是否存在,如果存在——True |
| join(path,name) | 将目录与目录或者文件名拼接起来 |
| splitext() | 分离文件名和扩展名 |
| basename(path) | 从一个目录中提取文件名 |
| dirname(path) | 从一个路径中提取文件路径,不包括文件名 |
| isdir(path) | 用于判断是否为路径 |
import os.path
print(os.path.abspath('data6.1.py'))
print(os.path.exists('data3.py'))
print (os.path.join('D:\\Python','data2.py'))
print(os.path.split("D:\\Python\\data2.py"))
print(os.path.splitext("data2.py"))
print(os.path.basename('D:\\Python\\data2.py'))
print(os.path.dirname('D:\\Python\\data2.py'))
print(os.path.isdir('D:\\Python\\data2.py'))#data2.py这是一个文件
——————————————————————————————————————————————————————————
D:\Python\data2.py
('D:\\Python', 'data2.py')
('data2', '.py')
data2.py
D:\Python
False#获取指定目录下面所有的python文件
import os
path=os.getcwd()
lst=os.listdir(path)
for filename in lst:
if filename.endswith('.py'):
print(filename)import
#import module_a #导入 #from module import xxx #导入某个模块下的某个方法或者子模块 eg:os.system(‘df-h’) #from module.xxx.xx import xx as rename #导入一个方法后重命名 #form module.xxx.xx import * #导入一个模块下的所有方法,不建议使用,直接eg:system(‘df-h’),容易和函数名冲突
python换行 空格+\ 回车

















 152
152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









