







Perface
首先,此文档默认你的电脑已经安装:
- Java
- Hadoop集群
- Scala
我的电脑环境:
- Java version “1.8.0_171”
- Hadoop 2.7.7
- CentOS Linux release 7.7.1908 (Core)
首先需要下载合适的spark版本:spark官方下载网址
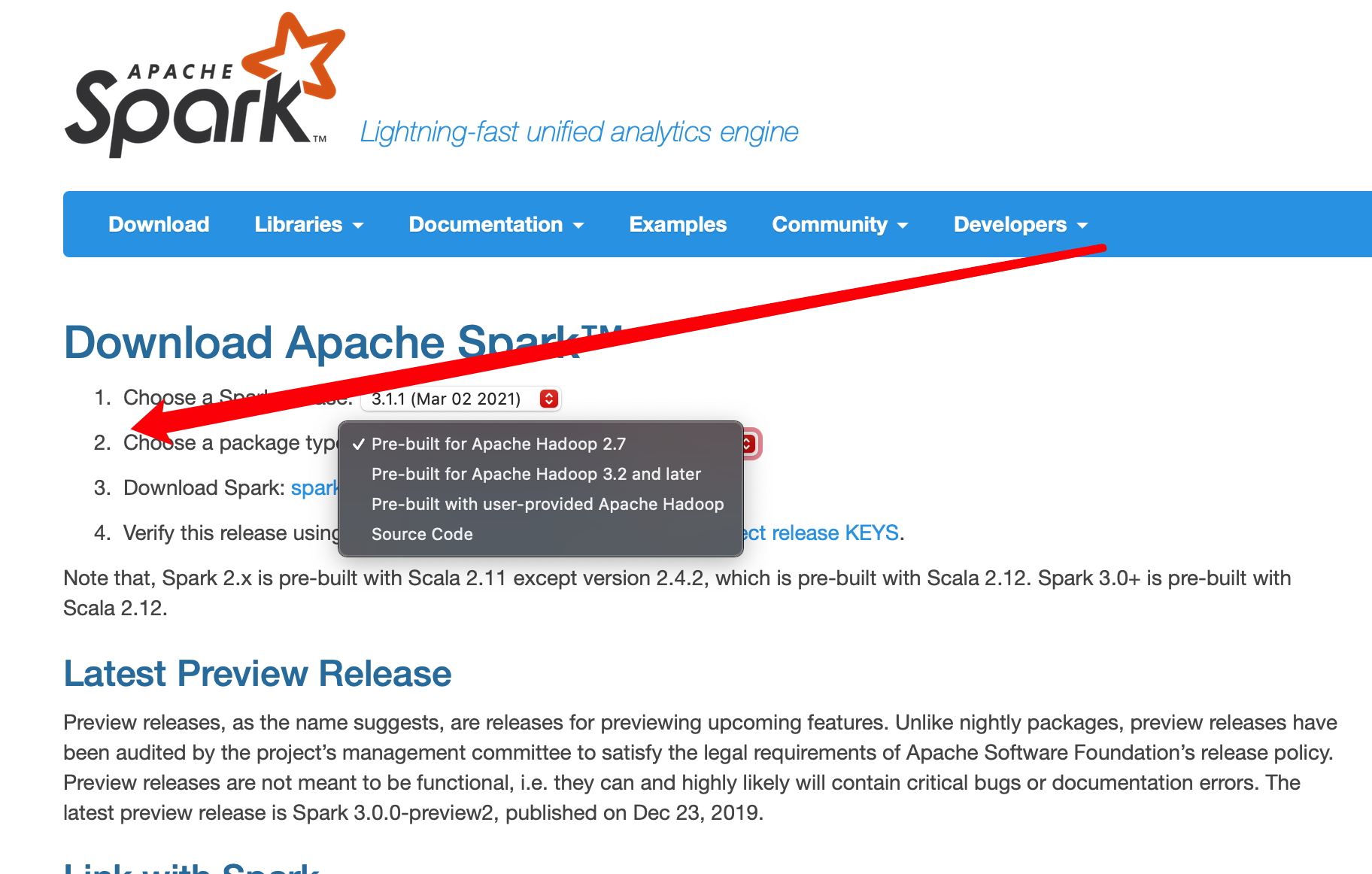
!> 重点是第二步,选择合适你hadoop的版本来下载,我因为下老师提供的未build错误版本浪费了很长时间
这里提供的是适合hadoop2.7版本下载的2.4.7版本
点我下载
由于我们已经自己安装了Hadoop,所以,在“Choose a package type”后面需要选择“Pre-build with user-provided Hadoop [can use with most Hadoop distributions]”,然后,点击“Download Spark”后面的“spark-2.1.0-bin-without-hadoop.tgz”下载即可。下载的文件,默认会被浏览器保存在“/home/hadoop/下载”目录下。需要说明的是,Pre-build with user-provided Hadoop: 属于“Hadoop free”版,这样,下载到的Spark,可应用到任意Hadoop 版本。
关于spark
Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器)。
安装
准备
$ tar -zxf /root/spark-2.1.0.tgz
$ cd /root
$ mv /spark2.1.0 spark
# 关于scala与上同理,在此不赘述
$ vim /etc/profile
在文件中添加下面:
export SCALA_HOME=/root/scala
export SPARK_HOME=/root/spark
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$JPS_HOME:$HIVE_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin:$SCALA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
$ source /etc/profile
$ scala -version #已可查看版本号
# 将文件分发到从机
$ scp -r /root/spark slave1:/root/
$ scp -r /root/spark slave2:/root/
$ scp -r /root/scala slave1:/root/
$ scp -r /root/scala slave2:/root/
$ scp -r /etc/profile slave1:/etc/
$ scp -r /etc/profile slave2:/etc/
配置spark
$ cd /root/spark/conf
$ cp spark-env.sh.template spark-env.sh
$ vim spark-env.sh
添加下面几行:
export JAVA_HOME=${JAVA_HOME}
export SCALA_HOME=${SCALA_HOME}
export SPARK_MASTER_IP=192.168.72.5 # 这里写自己的ip
export SPARK_WORKER_MEMORY=1G
export HADOOP_CONF_DIR=/root/hadoop/etc/hadoop # 这个是你hadoop配置文件所在位置
修改slaves文件
$ cp slaves.template slaves
$ vim slaves
slave1
slave2
将配置好的文件导入从机
$ scp -r /root/spark slave1:/root
$ scp -r /root/spark slave2:/root
启动spark
$ cd /root/spark
$ ./sbin/start-all.sh
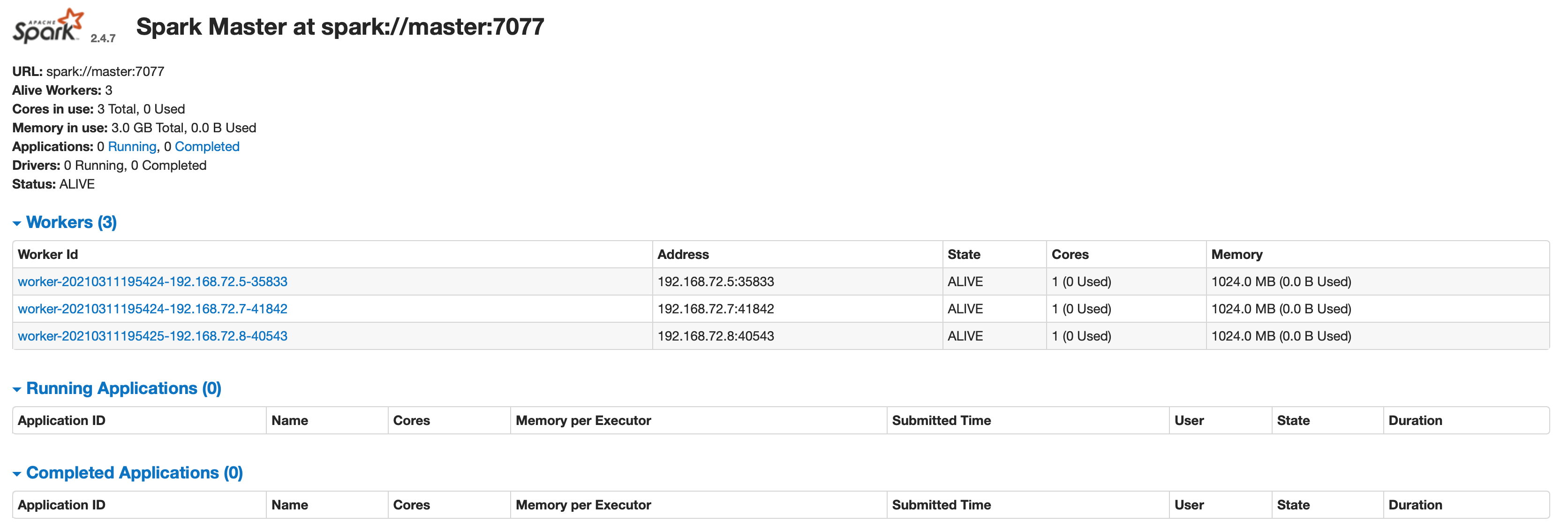
$ jps # 查看,出现worker和master代表成功
访问localhost:8080


















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









