







随便写一个ReentrantLock应用
ReentrantLock reentrantLock = new ReentrantLock(true);
reentrantLock.lock();
System.out.println("上锁了");
reentrantLock.unlock();ctrl+鼠标左键点击lock方法,ctrl+alt+B选择该实现类为公平锁

公平锁的lock()方法
final void lock() {
//1---->表示标识锁成功添加之后的改变值为1,下面这个方法其实是判断自己需不需要排队
acquire(1);
}非公平锁的lock()方法
final void lock() {
//非公平锁因为是不公平的,他进来不管有没有人排队,先进行CAS尝试获取一下锁,获取不到,才执行acquire(1)方法
if (compareAndSetState(0, 1))
//如果获取到锁,设置获取锁的线程为当前线程
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}公平锁上锁过程必须先判断自己需不需要排队,而非公平锁进来就先CAS尝试一下获取锁,获取不到再去尝试排队,但是不管是公平锁还是非公平锁,只要进入AQS排队了,那就会永远排队,下面例子是以公平锁为例继续深入。
执行流程如下:
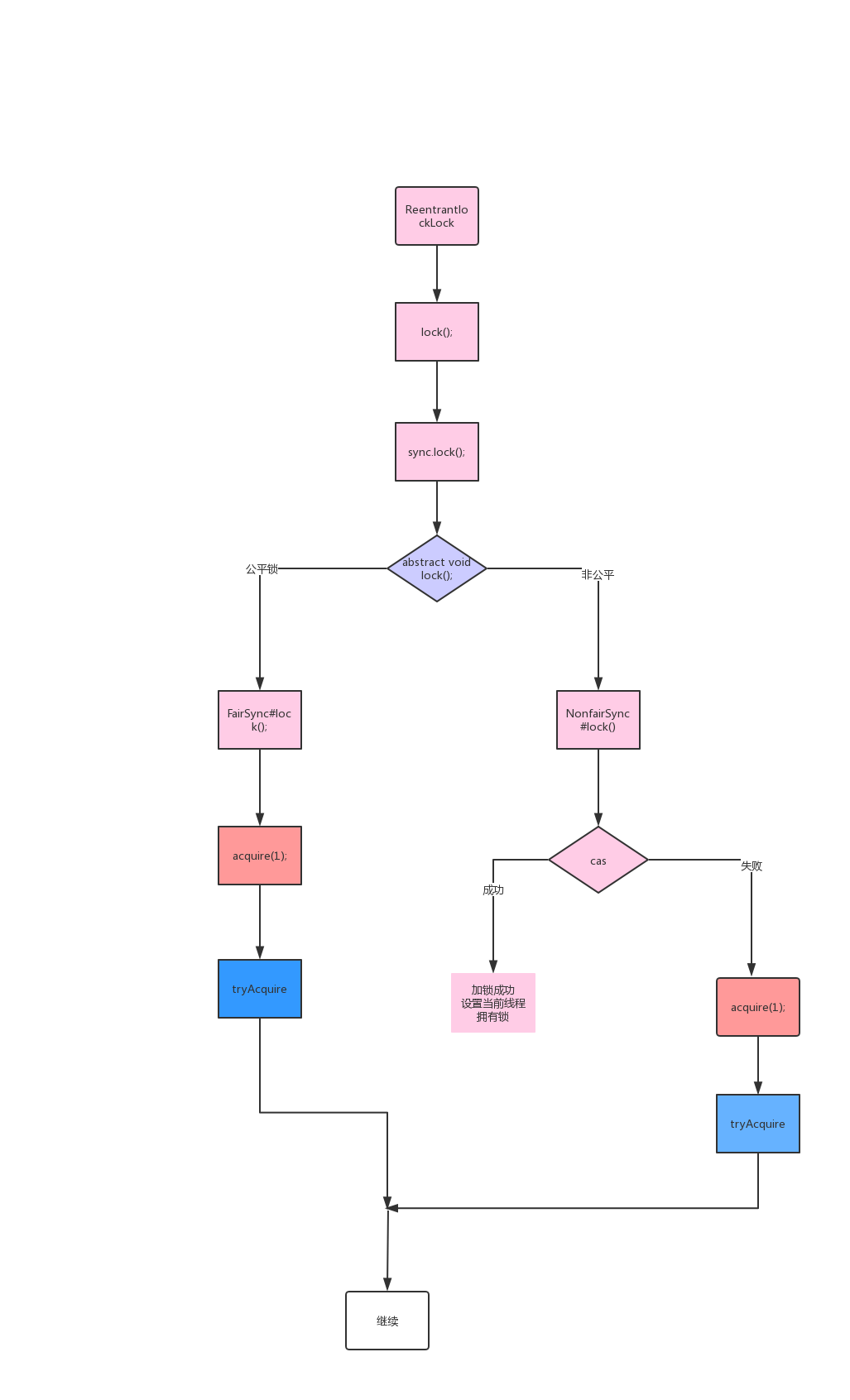
Acquire(1)源码如下:
public final void acquire(int arg) {
//tryAcquire(arg)尝试加锁,如果加锁失败返回false,取反为true继续往下执行acquireQueued方法尝试加入队列排队,返回true有两种情况,一种是直接加锁,内部有很多逻辑,下面介绍,第二种是当前占有锁的线程是自己,也就是可重入锁的原理,状态值+1
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
tryAcquire(arg)源码如下(ctrl+左键,然后ctrl+alt+B选择):
protected final boolean tryAcquire(int acquires) {
//将当前线获取并放到current变量中
final Thread current = Thread.currentThread();
//获取lock上锁的状态,源码中是直接retrun state属性值,如果是0表示自由状态,1表示锁定,大于表示可重入锁被获取次数
int c = getState();
//如果锁是自由状态,因为是公平锁,所以会通过hasQueuedPredecessors方法先判断自己是否需要排队,如果不需要排队就返回false,取反为true继续执行,尝试CAS获取锁,获取成功设置当前线程为拥有锁的线程,并返回true。
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
//1.如果c!=0,且当前线程不为获取到锁的线程就不执行,直接返回false,加锁失败
//2.如果c!=0,但当前线程==获取到锁的线程,加锁成功,也就是可重入锁,状态+1,返回true
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
//把更改后的state值设置回去
setState(nextc);
return true;
}
return false;
}hasQueuedPredecessors判断是否需要排队源码:
public final boolean hasQueuedPredecessors() {
// The correctness of this depends on head being initialized
// before tail and on head.next being accurate if the current
// thread is first in queue.
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}上面源码看着很少,但里面逻辑很复杂,首先要记住是对比与上面的tryAcquire他那里取反了,所以在tryAcquire中hasQueuedPredecessors返回为false也就是不需要排队才进行CAS操作加锁
然后分析一下上面的hasQueuedPredecessors源码
一.不需要排队(暂时不需要排队,最终要是条件不满足的话还是要排队)有两种意思: 1.队列没有初始化,比如线程A是第一个线程来就可以直接获取到锁,并不需要执行AQS操作,他只是用到了AQS类中的一个state变量来存储加锁状态,也就是说如果是单线程的,或者线程直接是交替执行(线程B在线程A释放之后才来),那么是不需要AQS队列的。----但是在高并发情况下可能会造成加锁失败,AB两个线程同时来lock(),发现锁没有被占有,都同时通过CAS获取锁,那么其中有一个必然会失败,回去进行初始化队列并排队 2.队列被初始化了,但是当线程B来加锁的时候,发现队列当中的第一个就是自己,比如可重入时。这时候他会先去CAS尝试一下获取锁,因为有可能这个时候线程A刚好释放了锁,如果没有释放则继续去排队等待 二. h!=t 也就是首不等于尾这里分三种情况 1(h!=t不成立).队列没有初始化,也就是第一个线程来的时候,首尾都为null,h!=t不成立,直接返回false,不需要排队,直接CAS加锁。 2(h!=t成立).队列初始化了,但是队列在初始化的时候会创建一个Thread为null的node结点存放获取锁的线程,然后把需要排队的线程放到第二个位置上,这时首尾不相等(@不绝对,下面的第三种情况,因为如果开始有三个线程,当前两个运行结束后,第三个线程执行,但是没有第四个线程进来,队列当中只有第三个线程,这时首尾相等),h!=t成立,继续执行&&后面的代码,&&后面的代码时一整块,因为是||,所以只要一个返回true就行,将头结点的后一个结点赋值给s(假设现在队列当中并没有执行到上面@不绝对那里的极端情况,也就是队列当中的线程个数>1),那么(s = h.next) == null肯定不成立,返回false,继续执行||后面的代码: s.thread != Thread.currentThread() 这里又分为两种情况 A1.当前线程不等于第二个位置上的线程,也就是头结点后面的处于第一个排队位置上的线程,返回true && true返回true,tryAcquire返回false,取反为true,继续执行acquire后续代码,也就是去进行排队 A2.当前线程等于第二个位置上的线程,true && false返回flase,也就是不需要排队,tryAcquire中执行后面的代码,也就是CAS尝试加锁,【!hasQueuedPredecessors() && compareAndSetState(0, acquires)】,这里又要分为两种情况讨论: B1:使用锁的线程释放了锁,加锁成功,!false && true为true,皆大欢喜,执行后续逻辑,设置当前线程为获取锁的线程,返回true,加锁成功 B2:使用锁的线程没有释放锁,CAS加锁不成功,这时候就和A1的情况一样了,【!hasQueuedPredecessors() && compareAndSetState(0, acquires)】和【!hasQueuedPredecessors()】返回结果是一样的,执行A1一样的后续操作。 3(h!=t不成立).队列初始化了,但队列中只有一个线程,上面2中的@处,此时h!=t不成立,直接返回false,不需要排队,直接CAS加锁。 注意:针对于上面的2处,他不是直接加入队列的,他会先判断第二个位置上也就是头结点后的第一个排队是不是自己,如果是会先CAS自旋一下尝试获取锁,获取不到再加入队列,如果不是那就直接加入队列,不会自旋尝试获取
注意点1.:也许会有人疑惑,既然h != t已经判断了头和尾不相等,那就肯定不只一个结点,为什么还要(s = h.next) == null判断一下了,是多此一举吗?
(h!=t)是用来判断节点数是否大于等于2,而h.next==null,是判断节点数是否为小于1或未被初始化,如果(h!=t)为true,那么h.next==null必为false,但是在多线程并发执行的情况下:
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
}
CAS只能保证一个变量操作的原子性,无法保证两个,if种CAS操作结束后,可能在tail赋值为head前,另一个线程就在tryAcauire()方法的hasQueuedPredecessors()进行判断,此时head被初始化但tail为null,那么h!=t就为true了,这时候通过h.next==null(判断节点数是否小于等于1),若为true即小于等于一,那么说明可能是链表正在初始化的情况,链表在初始化即代表此时无人排队,hasQueuedPredecessors()返回true,线程尝试取锁。若为false(链表中至少有两个节点,那么排除队列初始化到一半的情况),则通过后续的s.thread != Thread.currentThread()判断是否为排队的第一个线程。
注意点2.:疑问:比如如果在在排队,那么他是park状态,如果是park状态,自己怎么还可能重入啊 ?
这个要结合ReentrantLock源码去看tryAcquire中如果if和else if都不成立的时候就是说当前线程去尝试获取锁的时候其他线程正在使用锁,则返回false。此时就要注意了,lock方法调用的是acquire而不是tryAcquire,而aquire的方法,第一步是tryAcquire此时只是第一次尝试获取锁,失败了,之后会调用acquireQueued(addWaiter(Node.EXCLUSIVE),arg);在该方法中会先addWaiter可能会创建队列并把当前线程入队作为第一个线程,之后acquireQueued中会再次尝试获取锁,当再次尝试获取锁的时候当前线程确实是在排队,但是却还没有执行到park的步骤,线程并未park,因此确实会有在尝试获取锁的时候当前线程就是排队的首个线程的情况,这样判断在一方面是为了减少锁竞争带来的开销
至此,已经看完了tryAcquire的源码了,接着往下执行:
//tryAcquire里面的逻辑加锁不成功,返回false,取反为true,进行排队执行acquireQueued方法
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}acquireQueued(addWaiter(Node.exclusive),arg))方法解析
代码执行到这儿,说明该线程是需要排队的,但是排队又分为两种情况: 1.A线程持有了锁,但是并未释放,此时B线程来了,此时队列并没有初始化 2.不是最开始的执行,执行到中间某一个线程的时候,此时队列已经被初始化了,线程需要排队
先看看addWaiter(Node.exclusive)的源码
private Node addWaiter(Node mode) {
//因为在AQS当中都是一个一个的node结点,所以可以node结点看成一个个的线程
Node node = new Node(Thread.currentThread(), mode);
//这里的tail为队尾,将他赋值给一个临时变量pred(自己创建的,不存在于上下文当中)
Node pred = tail;
//判断队尾不为null,队尾为null只有一种情况,也就是没有被初始化才为空,一旦被初始化了就不可能为 空,即使队列当中只剩下最后一个运行的线程了,队首队尾都是指向这个线程,不为null。
if (pred != null) {
//此时将该node设置为队尾,并让他和上一个队尾互相绑定
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
//如果执行到这,也就是上面的if并没有进入,pred==null,队列没有初始化,看下面代码
enq(node);
return node;
}
private Node enq(final Node node) {
for (;;) {
//将队尾赋值给t结点,因为没有初始化,第一次t结点肯定为null
Node t = tail;
if (t == null) { // Must initialize
//nn表示new的这个node
//调用无参构造方法实例化出来的Node里面三个属性都为null,可以关联Node类的结构,
//compareAndSetHead入队操作;把这个nn设置成为队列当中的头部,cas防止多线程、确保原子操作;
if (compareAndSetHead(new Node()))
//将队尾也指向这个结点
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
因为是for(;;)死循环,我们执行第二次循环:
private Node enq(final Node node) {
for (;;) {
Node t = tail;
//此时t!=null,因为第一次循环队尾已经指向了一个结点,进入else语句块
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
//让nn结点指向入队的结点,也就是把入队的结点放到队列的第二个位置上
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
注:compareAndSetHead是如何将 new Node()结点设置为头结点,大概如下:
private final boolean compareAndSetHead(Node update) {
return unsafe.compareAndSwapObject(this, headOffset, null, update);
}
上面是cas操作,我们查看一下headOffset:
headOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("head"));
objectFieldOffset()方法用于获取某个字段相对Java对象的“起始地址”的偏移量,理解为获取head的地址即可, 如果为null,将将他赋值给这个node结点 总结:addWaiter方法就是让要入队的线程入队-并且维护队列的链表关系,但是由于情况复杂做了不同处理,主要针对队列是否有初始化,没有初始化则new一个新的Node nn作为对首,nn里面的线程为null。
acquireQueued方法的源码分析:
final boolean acquireQueued(final Node node, int arg) { //这里的node 就是当前线程封装的那个node,下文叫做nc
//一个标志位
boolean failed = true;
try {
//一个标志位
boolean interrupted = false;
for (;;) {
//获取nc的上一个结点,分两种情况:1种是头结点,1中不是头结点
final Node p = node.predecessor();
//如果nc是头结点,那么使用tryAcquire去CAS尝试一下加锁,加锁成功返回true,执行if里面,将nc设置为队首头结点,并将上一个头结点的引用断掉,进行回收,
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
//记住记加锁成功的时候为false
failed = false;
return interrupted;
}
//如果tryAcquire尝试加锁失败,很大概率失败,执行shouldParkAfterFailedAcquire,看中文名,尝试加锁失败之后应该park()。
//这里分两种情况:
//1.nc的上一个结点不是头结点,也就是nc不是第一个排队的
//2.nc的上一个结点是头结点,但是再去尝试获取锁失败了,应该park()
//不管哪一种情况都需要park
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}shouldParkAfterFailedAcquire源码分析:
//因为在acquireQueued()方法中有for(;;)存在,如果shouldParkAfterFailedAcquire不满足条件无法return的话就会一直循环执行
//第一次循环
//pred表示nc的上一个结点,node表示nc结点
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
//获取nc结点的上一个结点的waitStatus值,默认为0
int ws = pred.waitStatus;
//Node.SIGNAL=-1,不满足
if (ws == Node.SIGNAL)
return true;
//ws=0 不满足
if (ws > 0) {
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
//进行CAS操作,将ws赋值为-1
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
//第二次循环
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
//获取nc结点的上一个结点的waitStatus值,第一次循环已经更改为-1了
int ws = pred.waitStatus;
//满足条件,进入if,return结束循环
if (ws == Node.SIGNAL)
return true;
if (ws > 0) {
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
//此时执行acquireQueued中的
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
执行到这儿,nc也就是当前线程将他的上一个结点的waitstatus修改为-1,且自己park()了注1: 也许到这儿会有一个疑问,为什么不自己将自己的waitstatus设置为-1,而是需要下一个结点来设置?
因为你得确定你自己park了才是能改为-1;不然你自己改成自己为-1;但是改完之后你没有park那不就骗人?你对外宣布自己是单身状态,但是实际和马黑鬼私下约会这有点坑人,所以只能先park;在改状态;但是问题你自己都park了;完全释放CPU资源了,故而没有办法执行任何代码了,所以只能别人来改;故而可以看到每次都是自己的后一个节点把自己改成-1状态
注2:为什么waitstatus开始默认是0,进行一次循环之后改为-1,再执行,直接赋值-1不行吗?
为了保证第一个结点多自旋一次,也就是自旋两次,但后面的结点只会自旋一次,因为他都不是第一个结点,没有资格自旋两次。为什么第一个节点要多自旋一次:1.为了减少park的几率,park很消耗资源;2. ws=0是一种必要的状态,其他方法中会通过ws=0进行其他的操作
node结点的结构大概如下:
public class Node{
volatile Node prev;
volatile Node next;
volatile Thread thread;
volatile int waitStatus;
static final Node EXCLUSIVE = null;
/** waitStatus value to indicate thread has cancelled */
static final int CANCELLED = 1;
/** waitStatus value to indicate successor's thread needs unparking */
static final int SIGNAL = -1;
/** waitStatus value to indicate thread is waiting on condition */
static final int CONDITION = -2;
/**
* waitStatus value to indicate the next acquireShared should
* unconditionally propagate
*/
static final int PROPAGATE = -3;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









