






 本文介绍了数据库的基础知识,包括数据库系统、关系型数据库与NoSQL的区别。重点讲解了MySQL的配置文件my.ini,以及数据库表的创建、修改、删除等操作。此外,详细阐述了SQL的DML语言,如数据增删改查,涉及索引、分页、排序、条件查询和聚合函数的使用。同时,提到了事务处理、日志机制和数据库的备份与恢复概念。
本文介绍了数据库的基础知识,包括数据库系统、关系型数据库与NoSQL的区别。重点讲解了MySQL的配置文件my.ini,以及数据库表的创建、修改、删除等操作。此外,详细阐述了SQL的DML语言,如数据增删改查,涉及索引、分页、排序、条件查询和聚合函数的使用。同时,提到了事务处理、日志机制和数据库的备份与恢复概念。
一、数据库简介
1、操作系统中数据存放的载体
- Windows、Linux和MacOS都是基于文件的操作系统
2、什么是数据库系统?
- 数据库系统(DBMS)是指一个能为用户提供信息服务的系统。它实现了有组织地、动态地存储大量相关数据的功能,提供了数据处理和信息资源共享的便利手段
3、什么是关系型数据库系统?
- 关系型数据库系统(RDBMS)是指使用了关系模型的数据库系统
- 关系模型中,数据是分类存放的,数据之间可以有联系
- 主流关系型数据库:DB2、Oracle、MysSQL、SQL Server
4、什么是NoSQL数据库系统?
- NoSQL数据库指的是数据分类存放,但是数据之间没有关联关系的数据库系统
- Redis(内存保存数据):单线程
- 应用:秒杀库存、登陆信息、消息通知
- 主流NoSQL数据库:Redis、MemCache\MongoDB、Neo4J
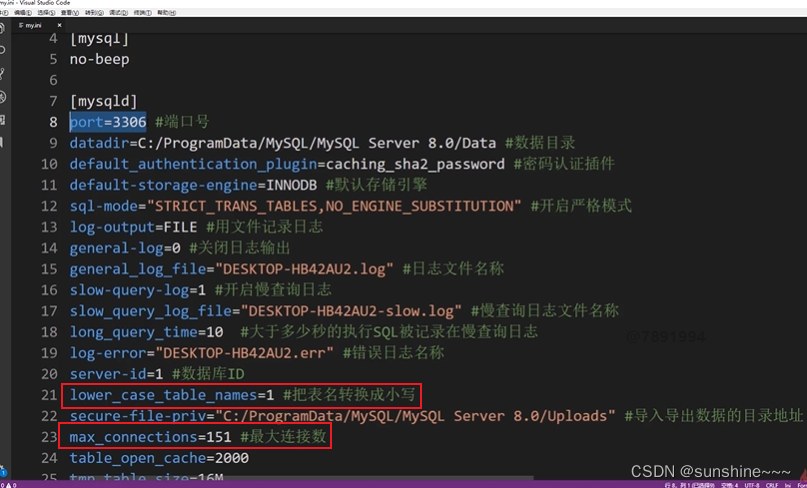
5、MySQL配置文件—my.ini:
在my.ini文件中,我们可以设置各种MySQL的配置,例如字符集、端口号、目录地址等;
主要分为两大部分:客户端配置信息、数据库配置信息
client :配置图形界面的设置
mysql : 配置命令行客户端的设置
mysqld : 配置数据库的设置
修改配置文件后,需关闭数据库服务,然后重启,才能使新的配置文件生效
二、数据库表的相关操作
1、SQL语言分类
- DML(Data Manipulation Language 数据操控语言) 添加 修改 删除 查询
- DCL(Data Control Language数据控制语言) 用户 权限 事务
- DDL (Data definition language 数据定义语言) 逻辑库 数据表 视图 索引
2、DDL——创建逻辑库
# CREATE DATABASE 逻辑库名称;
CREATE DATABASE test;
# SHOW DATABASES; 查看有哪些逻辑库 schemes
#DROP DATABASE 逻辑库名称;
DROP DATABASE test;
3、DDL——创建数据表
CREATE TABLE interview.student1student1(
id INT UNSIGNED PRIMARY KEY COMMENT "主键",
name VARCHAR(20) NOT NULL COMMENT "姓名",
age INT unsigned NOT NULL COMMENT "年龄"
)COMMENT "这是一个测试表1";
# 查看test逻辑库下面所有的表
SHOW tables;
# 插入一条数据
INSERT INTO interview.student1 VALUES (1, "小张", "24");
# 查看建表语句 DDL
SHOW CREATE TABLE student1;
#删除学生数据表
DROP TABLE student ;
4、数据表定义语言DDL:修改表结构
1.添加字段
ALTER TABLE 表名称ADD 列1 数据类型 [约束] [COMMENT 注释],
ADD 列2 数据类型 [约束] [COMMENT 注释],......;
例:
ALTER TABLE student ADD adress VARCHAR(200) NOT NULL,
ADD home_tel CHAR(11) NOT NULL;
2.修改字段类型和约束
ALTER TABLE 表名称 MODIFY 列1 数据类型 [约束] [COMMENT 注释],
MODIFY 列2 数据类型 [约束] [COMMENT 注释],......;
其中"列"是想要修改的字段名
例:
ALTER TABLE studentMODIFY home_tel VARCHAR(20) NOT BULL;
3.修改字段名称
ALTER TABLE 表名称
CHANGE 列1 新列明1 数据类型 [约束] [COMMENT 注释],
CHANGE 列2 新列明2 数据类型 [约束] [COMMENT 注释],
......;
例:
ALTER TABLE student CHANGE address home_address VARCHAR(20) NOT BULL;
4.删除字段
ALTER TABLE 表名称 DROP 列1,DROP 列2,......;
5、数据定义语言DDL:数据库的范式
- 构造数据库必须遵循一定的规则,这种规则就是范式
- 目前关系型数据库有6种范式,一般情况下,只满足第三范式即可
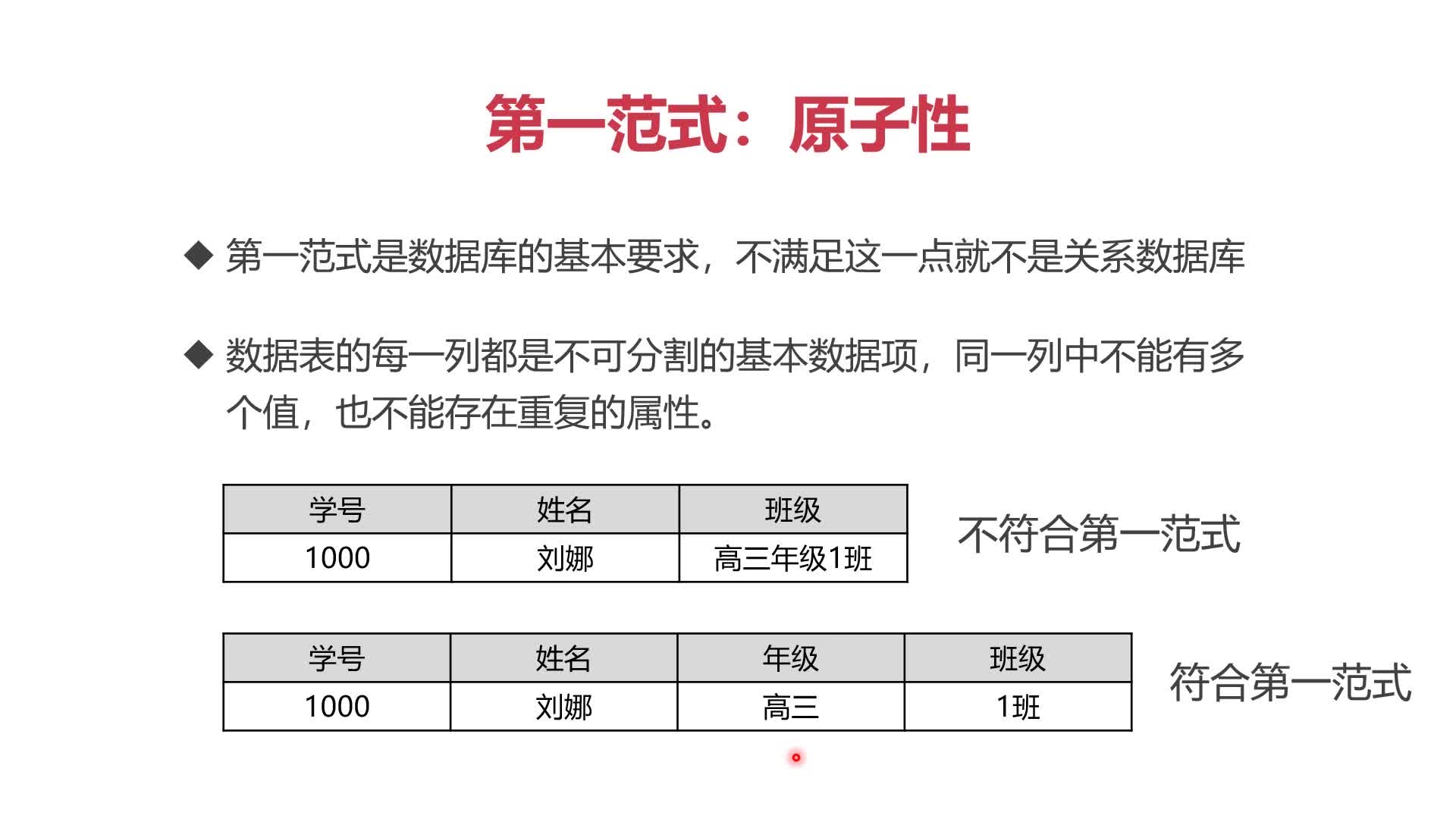
(1)第一范式:原子性
-
第一范式是数据库的基本要求,不满足这一点就不是关系数据库
-
数据表的每一列都是不可分割的基本数据项,同一列中不能有多个值,也不能存在重复的属性
**
**
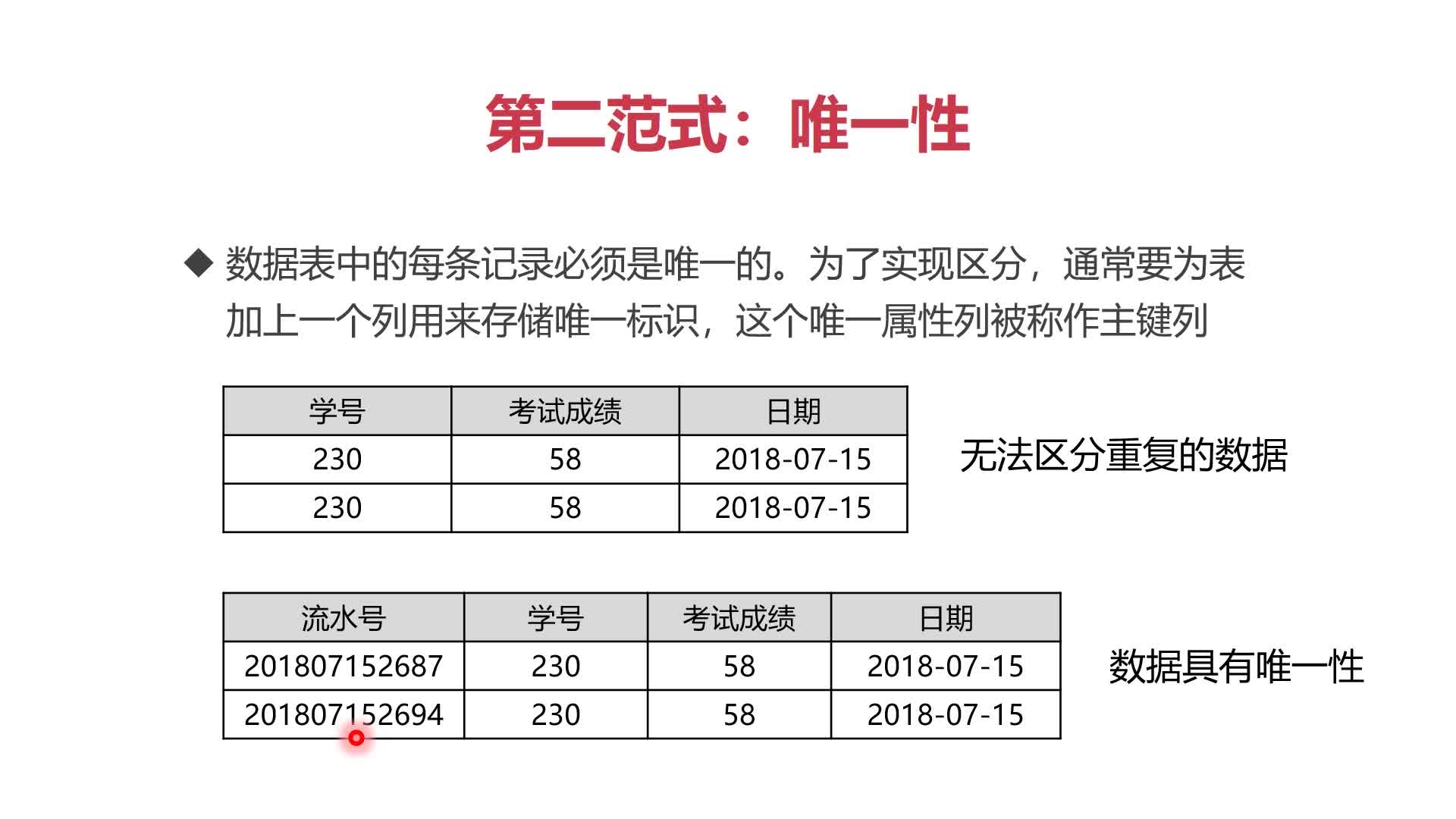
(2)第二范式:唯一性
- 数据表中的每条记录必须是唯一的。为了实现区分,通常要为表加上一个列用来存储标识,这个唯一属性列被称为主键列
- **
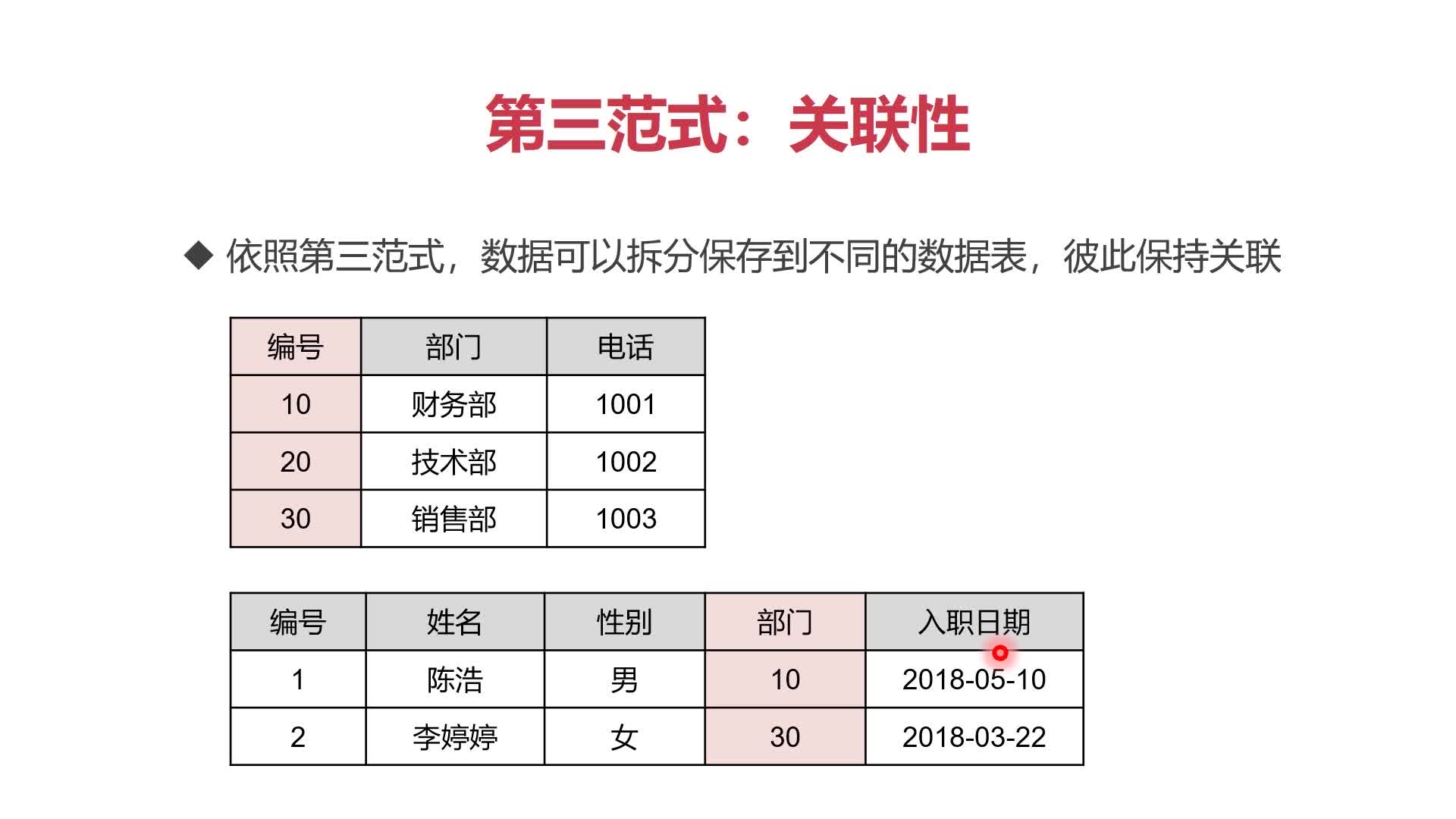
(3)第三范式:关联性
- 每列都与主键有直接关系,不存在传递依赖
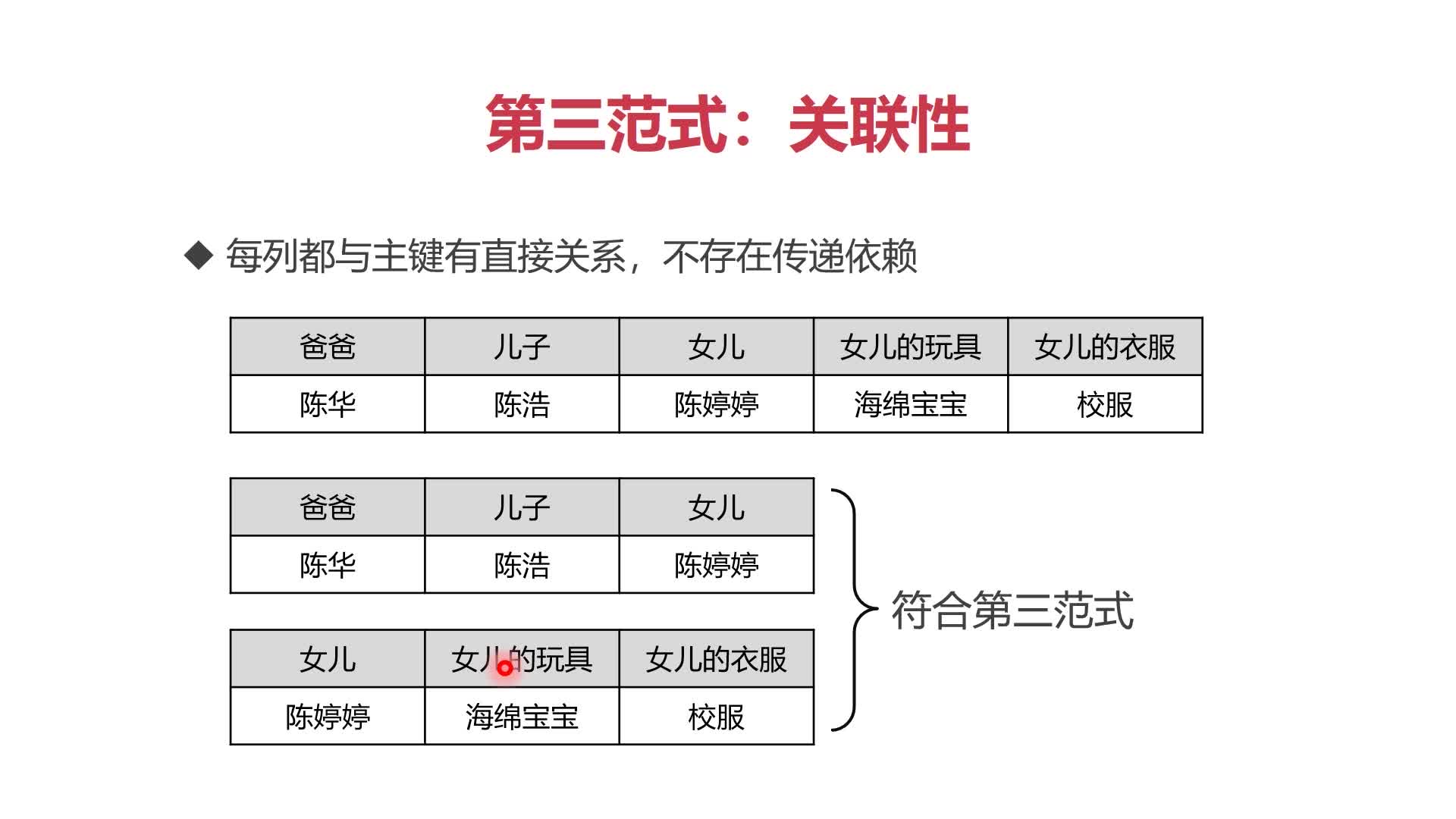
- 依照第三范式,数据可以拆分保存到不同的数据表,彼此保持关联
6、数据定义语言DDL:字段约束(共四种):
- MYSQL中的字段约束共有四种:(外键约束不推荐使用)
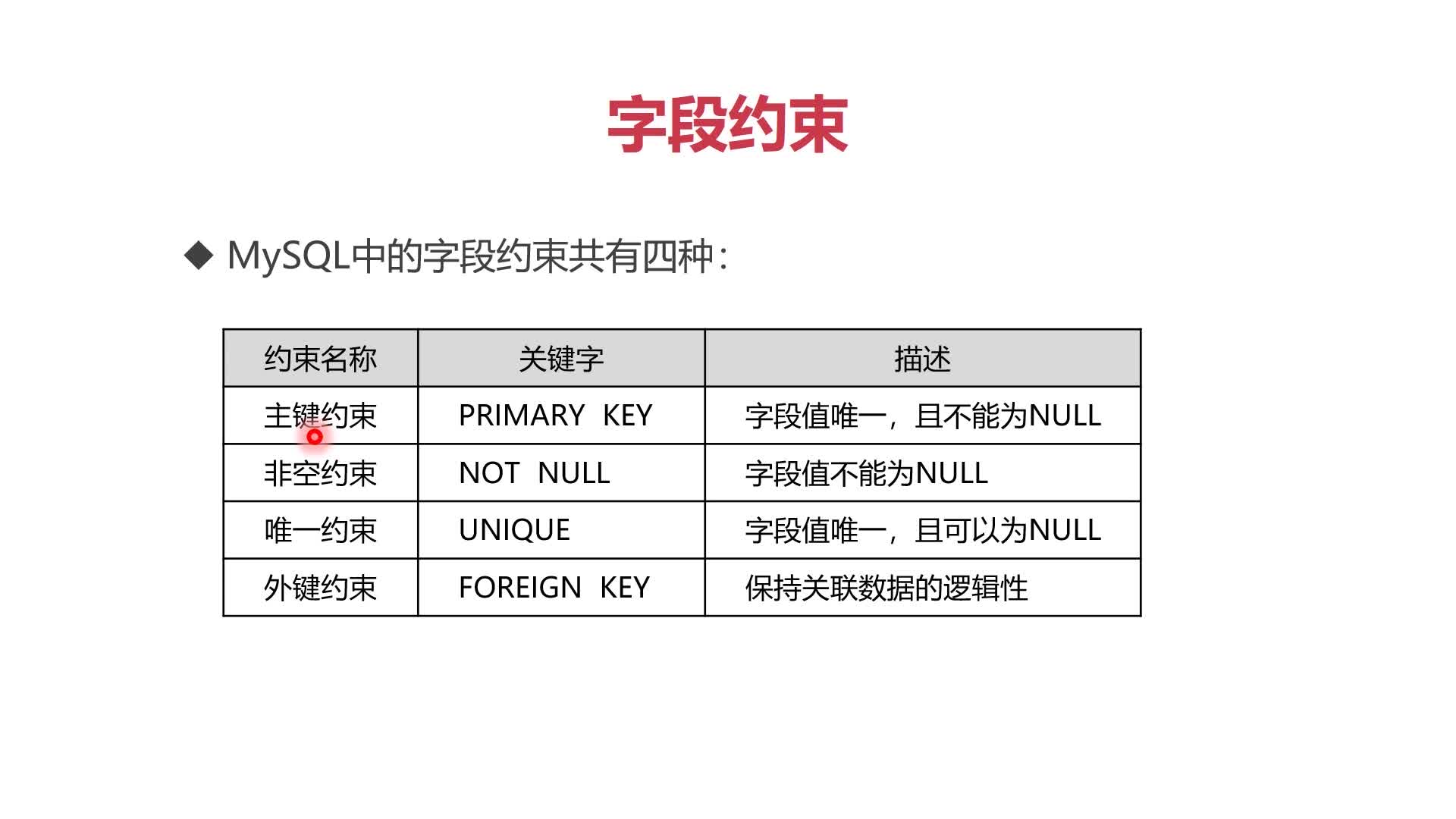
(1)主键约束:
- 主键约束要求字段的值在全表必须唯一,而且不能为NULL值
- 建议主键一定要使用数字类型,因为数字的检索速度会非常快
- 如果主键是数字类型,还可以设置自动增长
CREATE TABLE t_teacher( id INT PRIMARY KEY AUTO_INCREMENT,......);
(2)非空约束:
- 非空约束要求字段的值不能为NULL值
- NULL值以为没有值,而不是空字符串
(3)唯一约束:
- 唯一约束要求字段值如果不为NULL,那么在全表必须唯一
(4)外键约束:
- 外键约束用来保证关联数据的逻辑关系
- 外键约束的定义是写在子表上的
- 外键约束的闭环问题:如果形成外键闭环,我们将无法删除任何一张表的记录
7、数据定义语言DDL—索引 【原理:对数据排序】
(1)主键自带索引功能;
(2)数据排序的好处:
- 一旦数据排序之后,查找的速度就会翻倍,现实世界跟程序世界都是如此
(3)如何创建索引:
CREATE TABLE 表名称(......,INDEX [索引名称](字段),.....);
CREATE TABLE t_message(
id INT UNSIGNED PRIMARY KEY,
content VARCHAR(200) NOT NULL,
type ENUM("公告","通报","个人通知") NOT NULL,
create_time TIMESTAMP NOT NULL,
INDEX id_type (type)
);
(4)如何添加和删除索引:
CREATE INDEX 索引名称 ON 表名(字段);
ALTER TABLE 表名 ADD INDEX [索引名](字段);
// 展示索引
SHOW INDEX FROM 表名;
// 删除
DROP INDEX 索引名称 ON 表名;
(5)索引的使用原则:
- 数据量很大,而且经常被查询的数据表可以设置索引
- 索引只添加在经常被用作检索条件的字段上面
- 不要在大字段上创建索引
二、数据操作语言DML(也就是数据增删改查)
1、数据操作语言:普通查询
(1)记录查询:
- 最基本的查询语句是由SELECT和FROM关键字组成的
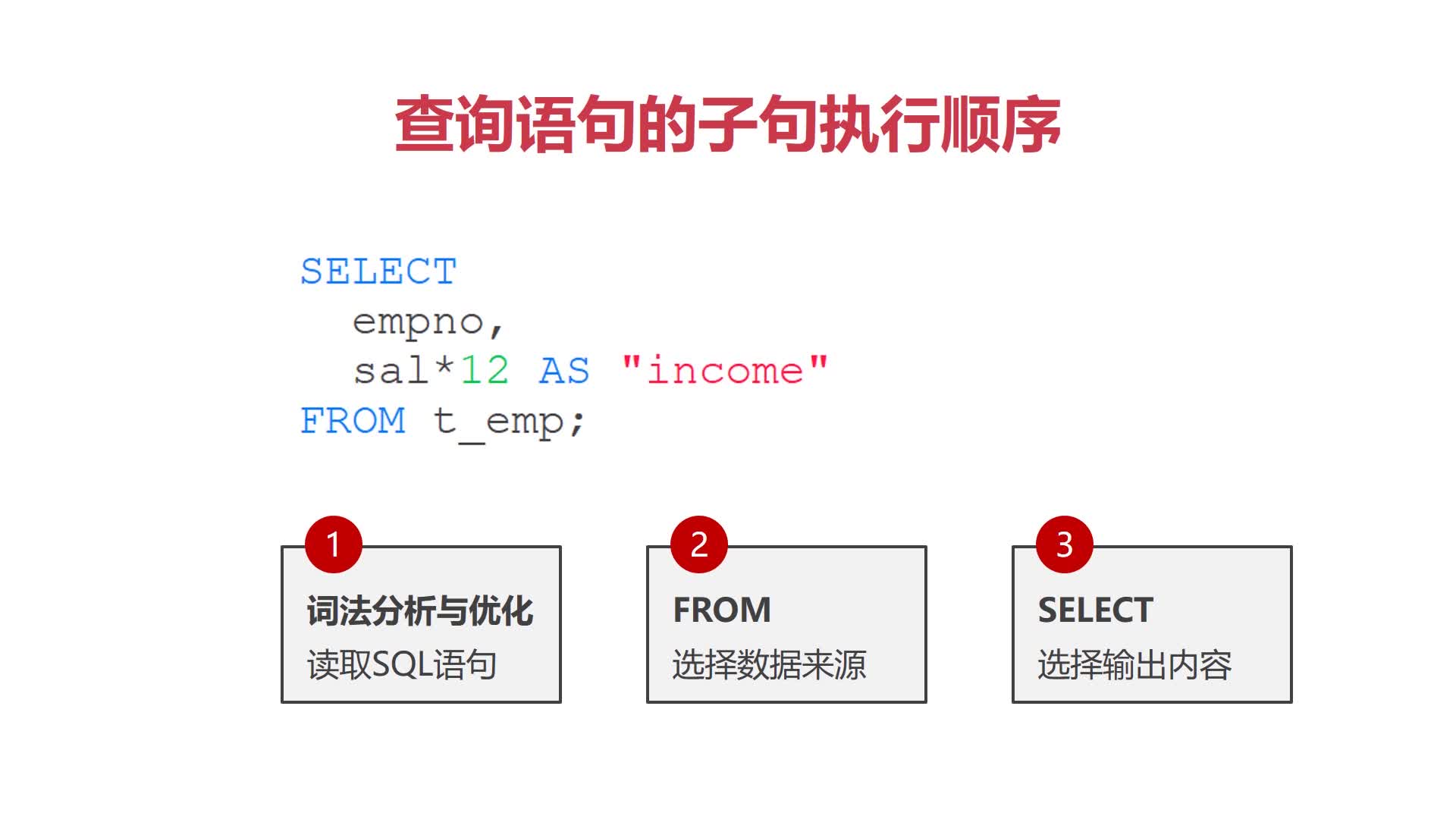
SELECT * FROM t_emp;SELECT empno, ename, sal FROM t_emp;
- SELECT语句屏蔽了物理层的操作,用户不必关心数据的真实存储,交由数据库高效的查找数据
(2)使用列别名:
- 通常情况下,SELECT子句中使用了表达式,那么这列的名字就默认为表达式,因此需要一种对列名重命名的机制
SELECT empno, sal*12 AS "income"FROM t_emp;
(3)查询语句的子句执行顺序:
2、数据操作语言:数据分页 LIMIT
- 比如我们查看朋友圈,只会加载少量部分信息,不用一次性加载全部朋友圈,那样只会浪费CPU时间、内存和网络带宽
- 如果结果集的记录很多,则可以使用LIMIT关键字限定结果集数量**
**
SELECT ... FROM ... LIMIT 起始位置,偏移量;
SELECT empno, ename FROM t_temp LIMIT 0,20;
数据分页的简写用法:
- 如果LIMIT子句只有一个参数,它表示的是偏移量,起始值默认为0
SELECT empno, ename FROM t_emp LIMIT 10;
- 执行顺序:FROM ——> SELECT——〉LIMIT
3、数据操作语言:结果集排序 ORDER BY
如果没有设置,查询语句不会对结果集进行排序。也就是说,如果想让结果集按照某种顺序排列,就必须使用ORDER BY子句。
# ASC升序,DESC降序,如果不填,默认为升序。SELECT .... FROM .... ORDER BY 列名 [ ASC | DESC ]; SELECT ename ,sal FROM t_emp ORDER BY sal;
排序关键字
ASC代表升序(默认),DESC代表降序
-
如果排序是数字类型,数据库就按照数字大小排序,如果是日期类型就按照日期大小排序,如果是字符串就按照字符串集序号排序。
-
排序字段内容相同的情况,默认会按照主键进行升序排序
-
多个排序字段:我们可以使用ORDER BY规定首要排序条件和次要排序条件。数据库会先按照首要排序条件排序,如果遇到首要排序内容相同的记录,那么就会启用次要排序条件接着排序,如果所有排序条件都无法满足,最终将默认使用主键升序进行排序。
-
排序 + 分页
SELECT empno FROM t_emp ORDER BY sal DESC LINIT 0,5;
-
ORDER BY字句书写的时候放在LIMIT字句的前面
执行顺序:FROM -> SELECT -> ORDER BY -> LIMIT
4、 数据操作语言:去除重复记录 DISTINCT
- 如果我们需要去除重复的数据,可以使用DISTINCT关键字来实现
SELCT DISTINCT 字段 FROM ...;
SELECT DISTINCT job FROM t_emp;
- 使用DISTINCT的SELECT子句中只能查询一列数据,如果查询多列,去除重复记录就会失效
- DISTINCT关键字只能在SLECT子句中使用一次
5、数据操作语言:条件查询
- 很多时候,用户感兴趣的并不是逻辑表里的全部记录,而只是当中能够满足某一种或某几种条件的记录。这类条件要用WHERE子句来实现数据的筛选
SELECT ... FROM ...WHERE 条件 [AND|OR] 条件 ...;
SELECT empno,ename,sal FROM t_emp WHERE deptno=10 AND sal >= 2000;
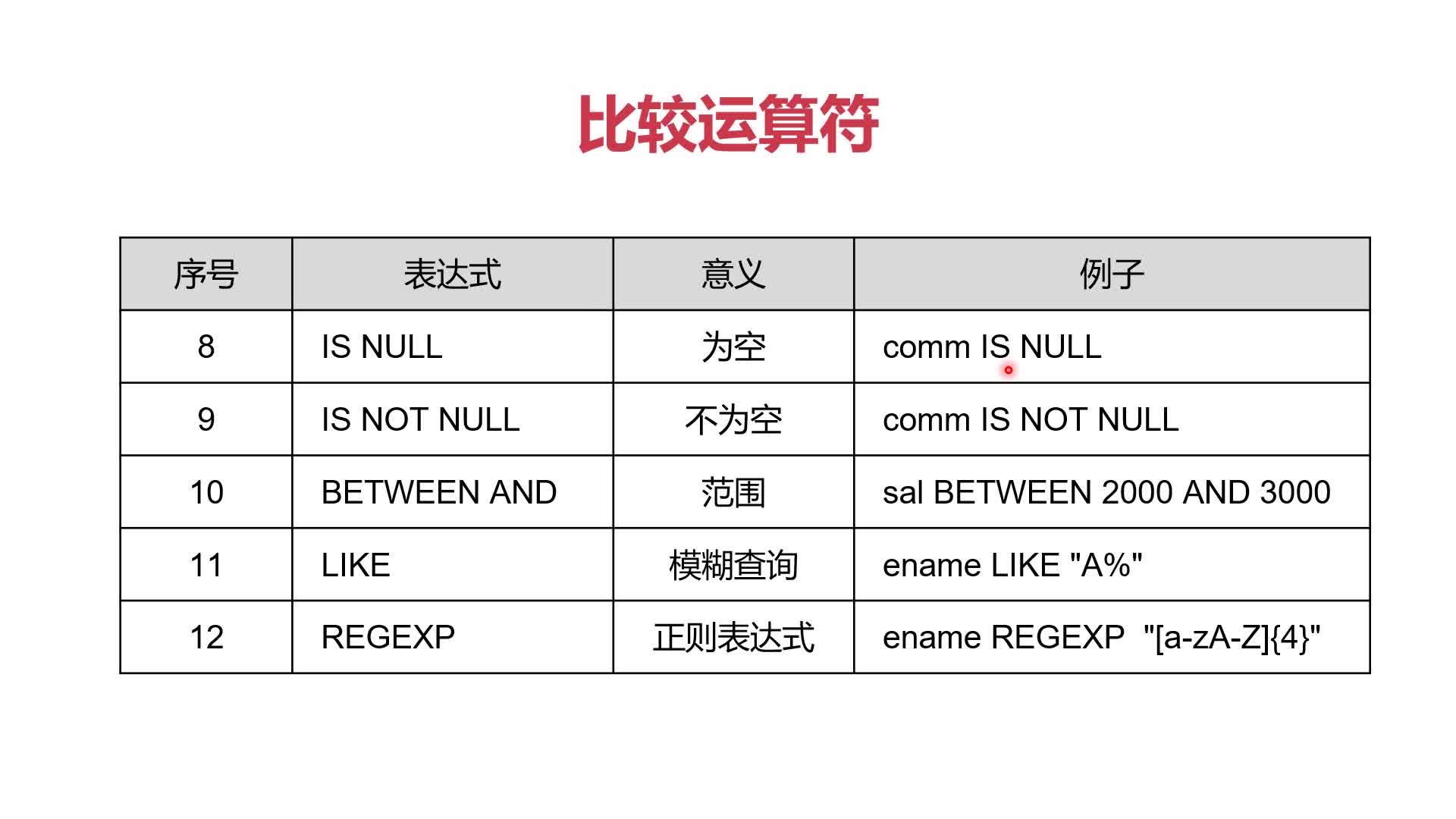
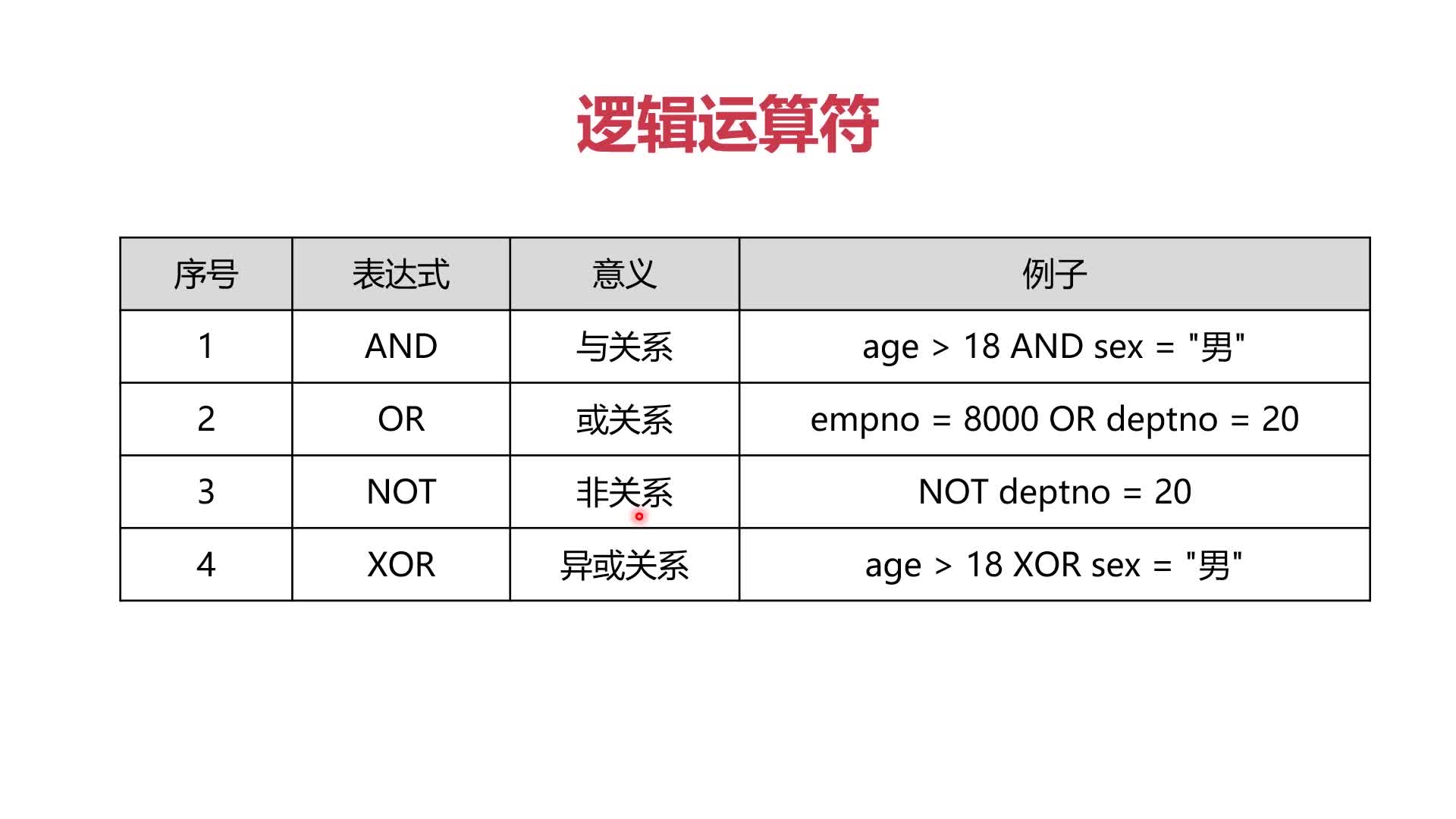
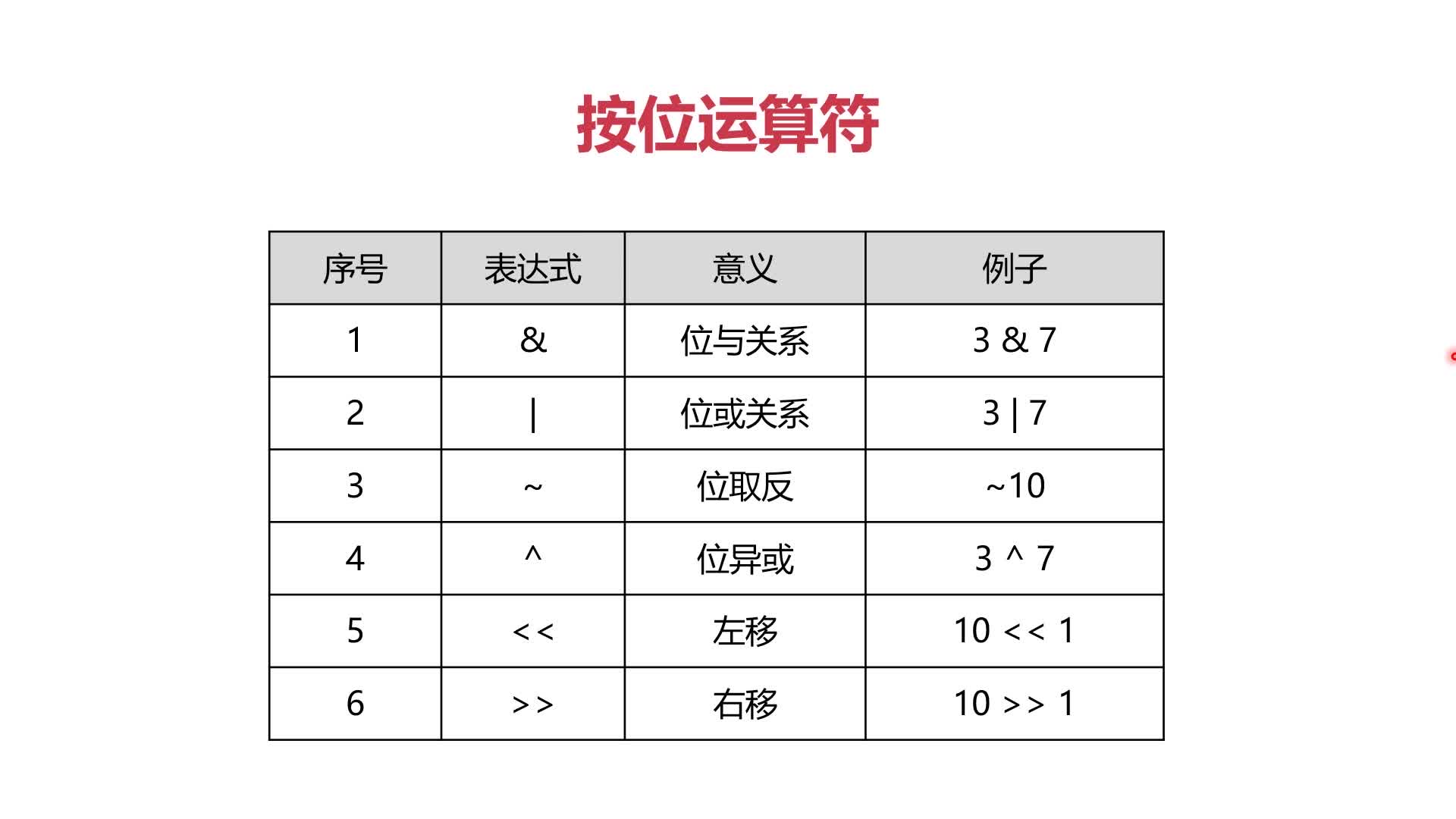
(1)四类运算符:WHERE语句中的条件运算会用到以下四种运算符
- 数学运算符
- 比较运算符
- 逻辑运算符
- 按位运算符
(2)函数:
- IFNULL(null,0)把null转换成0
- DATEDIFF(expr1,expr2)可以返回第一个日期减去第二个日期的天数
- NOW()可以得到当前的日期和时间
(3)WHERE子句的注意事项:
- WHERE子句中,条件执行的顺序是从左到右的。所以我们应该把索引条件,或者筛选掉记录最多的条件写在最左侧
(4)各种子句的执行顺序:
- FROM——>WHERE——>SELECT——>ORDER BY——>LIMIT
7、数据操作语言:聚合函数
- 聚合函数在数据的查询分析中,应用十分广泛。聚合函数可以对数据求和、求最大值和最小值、求平均值等(返回只有一条数据)
(1)SUM函数:
- SUM函数用于求和,只能用于数字类型,字符类型的统计结果为0,日期类型统计结果是毫秒数相加
SELECT SUM(salary) FROM t_emp;
SELECT SUM(salary) FROM t_emp WHERE deptno IN(10,20);
(2)MAX函数:
- MAX函数用于获得非空值的最大值
SELECT MAX(comm) FROM t_emp;// 查询名字最长的是几个字符
SELECT MAX(LENGTH(ename)) FROM t_emp;
(3)MIN函数:
- MIN函数用于获得非空值的最小值
SELECT MIN(empno) FROM t_emp;
SELECT MIN(hiredate) FROM t_emp;
(4)AVG函数:
- AVG函数用于获得非空值的平均值,非数字数据统计结果为0**
// 求平均值
SELECT AVG(sal + IFNULL(comm,0) AS avg FROM t_emp;
(5)COUNT函数:
- COUNT(*)用于获得包含空值的记录数,COUNT(列名)用于获得包含非空值的记录数
SELECT COUNT(*) FROM t_emp;
数据操作语言:分组查询
- 默认情况下汇总函数总是对全表范围内的数据做统计
- GROUP BY子句的作用是通过一定的规则将一个数据集划分成若干个小区域,然后针对每个小区域分别对数据汇总处理
SELECT deptno, ROUND(AVG(sal)) FROM t_emp GROUP BY deptno;
逐级分组
- 数据库支持多列分组条件,执行的时候逐级分组
- 查询每个部门里,每种职位的人员数量和平均底薪
SELECT deptno, job, COUNT(*),AVG(sal)
FROM t_emp
GROUP BY deptno,job
ORDER BY deptno;
对SELECT子句的要求:
- 查询语句中如果含有GROUP BY子句,那么SELECT子句中的内容就必须要遵守规定:SELECT子句中可以包含聚合函数,和GROUP BY子句的分组列,其余内容均不可出现在SELECT语句中
对分组结果集再次做汇总:
SELECT deptno, COUNT(*),AVG(sal),MAX(sal),MIN(sal)
FROM t_emp
GROUP BY deptno WITH ROLLUP;
GROUP_CONCAT函数:
- GROUP_CONCAT函数可以把分组查询中的某个字段拼接成一个字符串
各种子句的执行顺序:
FROM ——》WHERE——〉GROUP BY——》SELECT——〉ORDER BY——》LIMIT
8、数据操作语言:分组查询
- 默认情况下汇总函数总是对全表范围内的数据做统计
- GROUP BY子句的作用是通过一定的规则将一个数据集划分成若干个小区域,然后针对每个小区域分别对数据汇总处理
SELECT deptno, ROUND(AVG(sal))FROM t_emp GROUP BY deptno;
(1)逐级分组
- 数据库支持多列分组条件,执行的时候逐级分组
- 查询每个部门里,每种职位的人员数量和平均底薪
SELECT deptno, job, COUNT(*),AVG(sal)
FROM t_emp
GROUP BY deptno,job
ORDER BY deptno;
(2)对SELECT子句的要求:
- 查询语句中如果含有GROUP BY子句,那么SELECT子句中的内容就必须要遵守规定:SELECT子句中可以包含聚合函数,和GROUP BY子句的分组列,其余内容均不可出现在SELECT语句中
(3)对分组结果集再次做汇总 WITH ROLLUP:
SELECT deptno, COUNT(*),AVG(sal),MAX(sal),MIN(sal)
FROM t_emp GROUP BY deptno WITH ROLLUP;
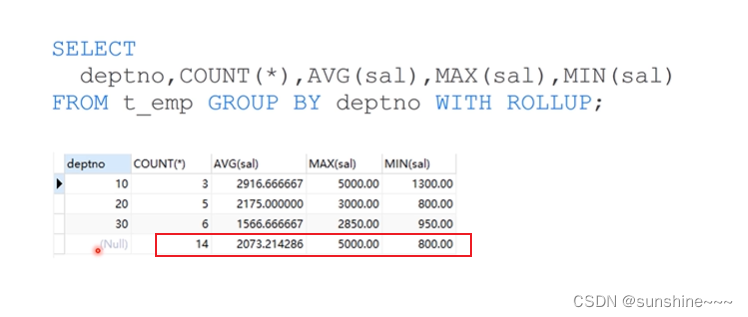
(4)GROUP_CONCAT函数:
- GROUP_CONCAT函数可以把分组查询中的某个字段拼接成一个字符串

(5)各种子句的执行顺序:
FROM ——》WHERE——〉GROUP BY——》SELECT——〉ORDER BY——》LIMIT
9、数据操作语言:HAVING子句(只能结合GROUP BY使用)
- == WHERE子句不能写聚合函数 ==
- WHERE子句执行顺序在GROUP BY子句前面,所以会出现问题。
- HAVING子句和WHERE子句差不多,都是用来做条件筛选的,只是HAVING子句写在GROUP BY子句后面,GROUP
BY子句执行完之后才会执行HAVING子句
SELECT deptno,AVG(sal) FROM t_emp GROUP BY deptno HAVING AVG(sal) > 2000;
10、数据操作语言:INSERT语句
-
写字段声明可以加快执行速度:…表名(字段1,字段2, … ) …
-
INSERT语句可以向数据表写入记录,可以是一条记录,也可以是多条记录
-
INSERT INTO 表名(字段1,字段2, … ) VALUES(值1,值2, …);
-
INSERT INTO 表名(字段1,字段2, … ) VALUES(值1,值2, …),(值1,值2, …),;
-
INSERT 语句方言:MYSQL的INSERT语句还有一种方言语法
INSERT INTO 表名 SET 字段1=值1,字段2=值2, … ; #关键字INTO可以省略
-
IGNORE关键字会让INSERT只插入数据库不存在的记录
INSERT [IGNORE] INTO 表名 … ;
11、数据操作语言:UPDATE语句
(1)UPDATE语句用于修改表的记录
IGNORE关键字会忽略主键冲突的记录
更新语句中limit后面只能跟单个的值
UPDATE [IGNORE] 表名
SET 字段1=值1,字段2=值2,......
[WHERE 条件1 ......]
[ORDER BY]
[LIMIT ......];
(2)UPDATE语句的表连接(内连接)
-表连接的UPDATE语句可以修改多张表的记录
-因为相关子查询效率非常低,所以我们可以利用表连接的方式来改造UPDATE语句
# 方式一
UPDATE 表1 JOIN 表2 ON 条件
SET 字段1=值1,字段2=值2,......;
# 方式二
UPDATE 表1,表2
SET 字段1=值1,字段2=值2,......
WHERE 连接条件;
UPDATE t_emp, t_dept
SET t_emp.deptno=t_dept.deptno,t_dept.loc="北京"
WHERE t_dept.dname="RESEARCH" AND t_emp.ename="ALLEN";
# 一张表用表连接的形式更新字段:把底薪低于公司平均底薪的员工,底薪增加150元
UPDATE t_emp,(SELECT AVG(sal) AS avg FROM t_emp) t_avg
SET t_emp.sal =t_emp.sal + 150
WHERE t_emp.sal < t_avg.avg;
-UPDATE语句的表连接既可以是内连接,又可以是外连接
UPDATE 表1 [LEFT|RIGHT] JOIN 表2 ON 条件
SET 字段1=值1,字段2=值2,......;
UPDATE t_emp LEFT JOIN t_dept
ON t_emp.deptno=t_dept.deptno
SET t_emp.deptno=20
WHERE t_emp.deptno IS NULL OR (t_dept.dname="SALES" AND t_emp.sal < 2000);
12、数据操作语言:DELETE语句
(1)DELETE语句用于删除记录,语法如下:
DELECT [IGNORE] FROM 表名
[WHERE 条件1,条件2,......]
[ORDER BY ......]
[LIMIT ......];
(2)DELETE语句的表连接(内连接)
- 因为相关子查询效率非常低,所以我们可以利用表连接的方式来改造DELETE语句
DELETE 表1,...... FROM 表1 JOIN 表2 ON 条件
[WHERE 条件1,条件2,......]
[ORDER BY ......]
[LIMIT ......];
DELETE t_emp,t_dept
FROM t_emp JOIN t_dept
ON t_emp.deptno=t_dept.deptno
WHERE t_dept.dname="SALES";
(3)DELETE语句的表连接(外连接)
- DELETE语句的表连接既可以是内连接,又可以是外连接
DELETE 表1,...... FROM 表1 [LEFT|RIGHT] JOIN 表2 ON 条件 ......;
(4)快速删除数据表全部记录
- DELETE语句是在事务机制下删除记录,删除记录之前,先把将要删除的记录保存到日志文件里,然后再删除记录
- TRUNCATE语句在事务机制外删除记录,速度远超过DELETE语句
# 一次只能清空一张数据表
TRUNCATE TABLE 表名;
13、数据操作语言:表连接查询
- 从多张表中提取数据,必须指定关联的条件。如果不定义关联条件就会出现无条件连接,两张表的数据会交叉连接,产生笛卡尔积。
- 规定了连接条件的表连接语句,就不会出现笛卡尔积 有这个ON条件,就不会产生笛卡尔积。
SELECT e.empno,e.ename,d.dname
FROM t_emp e JOIN t_dept d
ON e.deptno=d.deptno;
(1)表连接的分类:
表连接分为两种:内连接和外连接
内连接是结果集中只保留符合符合连接条件的记录
外连接时不管符不符合连接条件,记录都要保留在结果集中
内连接:
内连接是最常见的一种表连接,用于查询多张关系表符合连接条件的记录
内连接的多种语法形式:
(1)SELECT ...... FROM 表1 JOIN 表2 ON 连接条件;
(2)SELECT ...... FROM 表1 JOIN 表2 WHERE 连接条件;
(3)SELECT ...... FROM 表1,表2 WHERE 连接条件;
内连接的数据表不一定必须有同名字段,只要字段之间符合逻辑关系就可以
语法嵌套的例子:
查询与SCOTT(员工)相同部门的员工都有谁?
SELECT ename
FROM t_emp
WHERE deptno=(SELECT deptno FROM t_emp WHERE ename="SCOTT")
AND ename !="SCOTT";
虽然上面的例子很符合人思考的习惯,但是它的执行效率很慢!改进办法:
SELECT e2.ename
FROM t_emp e1 JOIN t_emp e2 ON e1.deptno=e2.deptno
WHERE e1.ename="SCOTT" AND e2.ename!="SCOTT";
这样就只筛选了数据,没有做子查询,所以更快!
相同的数据表也是可以做表连接的。
三、MySQL基本函数的使用
1、数字函数
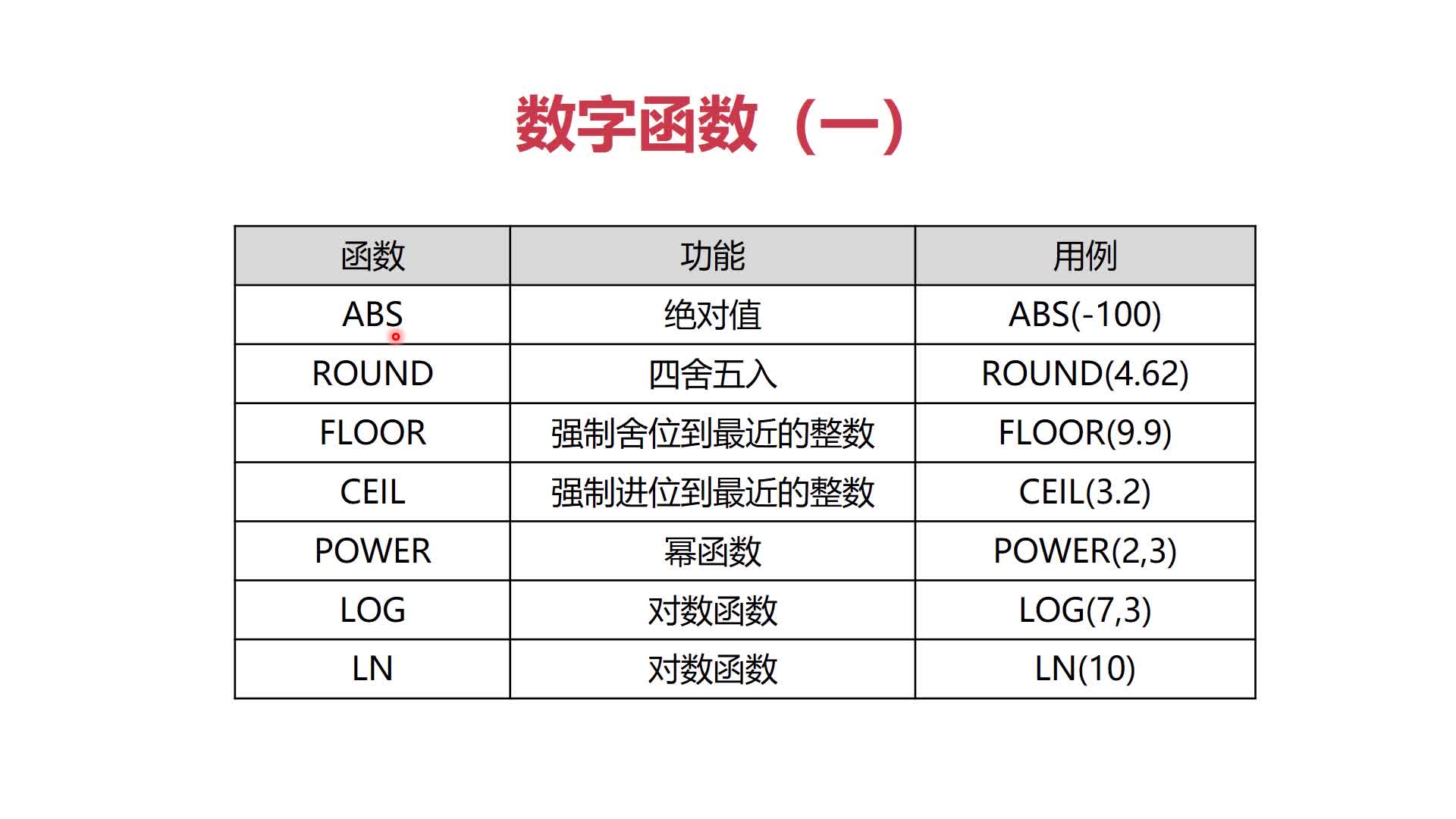
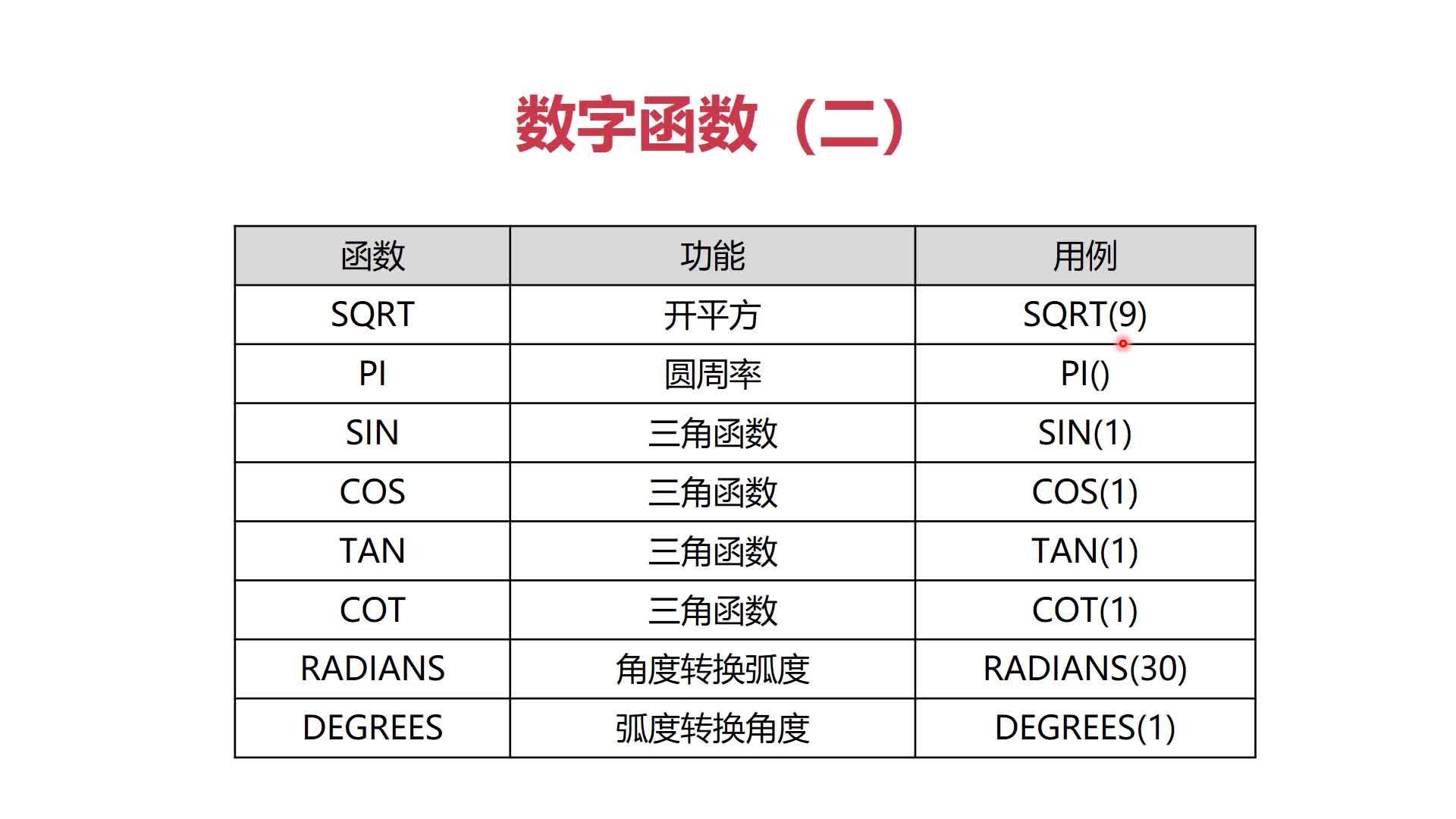
2、字符函数
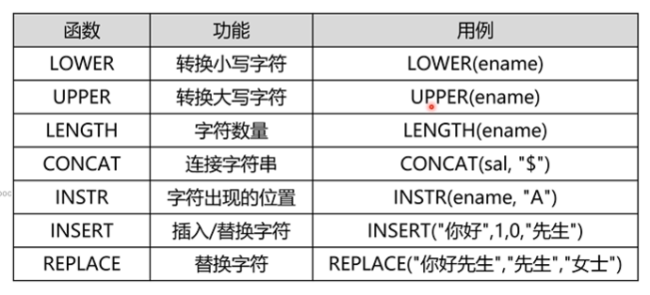
SELECT LOWER(ename), UPPER(ename),LENGTH(ename),CONCAT(sal, "$"),INSTR(ename, "A")
FROM t_emp;
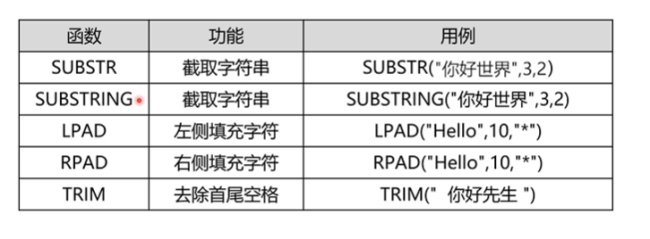
3、日期函数
(1)日期函数:(数据库支持的最小的时间单位是秒)
- 获取系统时间函数:NOW()函数能获得系统日期和时间,格式yyyy-MM-dd hh:mm:ss
- CURDATE()函数能获得当前系统日期,格式yyyy-MM-dd
- CURTIME()函数能获得当前系统时间,格式hh:mm:ss
(2)日期格式化函数:DATE_FORMAT()
- DATE_FORMAT(日期,表达式):函数用于格式化日期,返回用户想要的日期格式
SELECT ename, DATE_FORMAT(hiredate, "%Y") FROM t_emp;
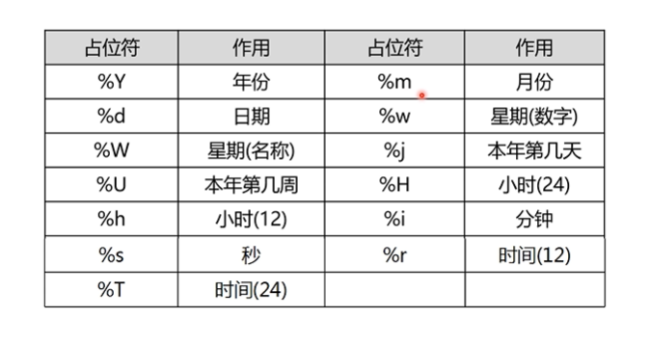
(3)日期计算的注意事项:
- MySQL数据库里面,两个日期不能直接加减,日期也不能与数字加减
(4)日期偏移计算:DATE_ADD()函数
- DATE_ADD()函数可以实现日期的偏移计算,而且时间单位很灵活
DATE_ADD(日期,INTERVAL 偏移量 时间单位)
SELECT DATE_ADD(NOW(), INTERVAL 15 DAY);
SELECT DATE_ADD(NOW(), INTERVAL -300 MINUTE);
(5)计算日期之间相隔的天数: DATEDIFF()
- DATEDIFF()函数用来计算两个日期之间相差的天数
DATEDIFF(日期,日期)
4、条件函数
条件函数:
- SQL语句中利用条件函数来实现编程语言里的条件判断
IFNULL(表达式,值)
IF(表达式,值1,值2) 【类似三元表达式】
复杂的条件判断可以用条件语句来实现,比IF语句功能更强大
CASE
WHEN 表达式 THEN 值1
WHEN 表达式 THEN 值2
......
ELSE 值N
END
四、MySQL数据库的事务机制
1、避免写入直接操作数据文件:
如果数据的写入直接操作数据文件是非常危险的事情;
2、利用日志来实现间接写入
MySQL总共有5种日志,其中只有redo日志和undo日志与事务有关:
日志文件相当于数据文件的一个副本,SQL语句操作什么样的记录,MySQL就会本这份记录拷贝到undo日志里面,增删改查会记录到redo日志里面,如果这些操作没有问题,最后把redo和数据文件做一下同步就可以了,即使出现了死机等情况,重启mysql之后继续完成redo和数据文件的同步就可以了,同步之后修改的数据就真正写到数据文件里面了,抵抗意外事故的能力就变强了。
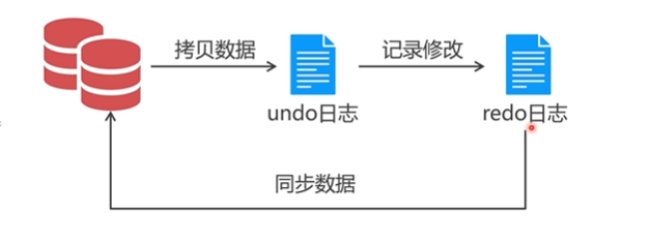
3、事务机制(Transaction)
- RDBMS = SQL语句 + 事务(ACID:原子性、一致性、隔离性、持久性)
- 事务是一个或者多个SQL语句组成的整体,要么全部执行成功,要么全都执行失败
事务的原子性:一个事务中的所有操作要么全部完成,要么全部失败。事务执行后不允许停留在中间某个状态;
事务的一致性:不管在任何给定的时间、并发事务有多少,事务必须保证运行结果的一致性;
事务的隔离性:隔离性要求事务不受其他并发事务的影响,如同在给定的时间,该事务是数据库唯一运行的事务。默认情况下A事务,只能看到日志中该事务的相关数据。
事务的持久性:事务一旦提交,结果便是永久性的。即便发生宕机,仍然可以依靠事务日志完成数据的持久化。
4、管理事务
- 默认情况下,MySQL执行每条SQL语句都会自动开启和提交事务
- 为了让多条SQL语句纳入到一个事务之下,可以手动管理事务
5、事务的四个隔离级别(默认是repeatable read这个隔离级别):
默认情况下,mysql是不允许读取临时数据的,但是在某些场合下,需要运行事务读取某些临时数据,这个就必须修改事务的隔离级别。
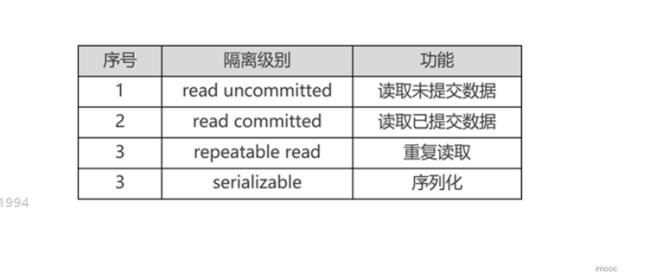
业务案例1火车售票场景:READ UNCOMMITED 代表可以读取其他事务未提交的数据
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITED;
业务案例2银行转账:READ COMMITTED 读取已提交的数据
业务案例3用户购买,商家涨价:REPEATABLE READ 代表事务在执行中反复读取数据,得到的结果是一致的,不会受其他事务影响
事务的序列化
由于事务并发执行所带来的各种问题,前三种隔离级别只适用在某些业务场景中,但是序列化的隔离性,让事务逐一执行,就不会产生上述问题了。
这种隔离牺牲了事务的并发性,前面的事务没有提交,后面的事务就会进入等待,直到前面的事务提交完成了才会开始执行下一个事务,很少使用
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;

















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









