







如果你在学习爬虫时遇到这个问题:
不知道这行代码什么意思CreatorHomeAnalyticsDataItem-title.?>(.?)
CreatorHomeAnalyticsDataItem-title.*?>(.*?)</div>
建议你换一下,以下代码块是我学习爬虫的时候遇到的代码
import requests
import re
# 构造请求头字典
headers = {
# 从浏览器中复制过来的User-Agent
"user-agent": ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (
KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’,
# 从浏览器中复制过来的Cookie
"cookie": ’xxx这里是复制过来的cookie字符串’}
# 请求头参数字典中携带cookie字符串
response = requests.get(’https://www.zhihu.com/creator’, headers=headers)
data = re.findall(’CreatorHomeAnalyticsDataItem-title.*?>(.*?)</div>’,response.text)
print(response.status_code)
print(data)
我使用自己的user-agent,使用它的网页https://www.zhihu.com/creator
登录获取cookie,但是确实是拿不到数据
截图如下:
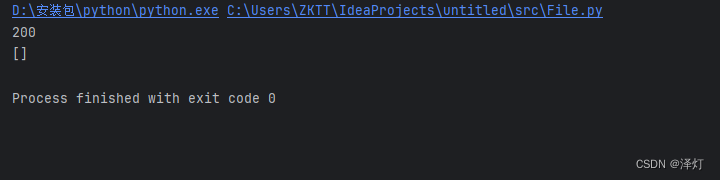
不知道那个博主他们是怎么获得到的具体内容
反正我获取不到,网上搜了许多也解决不了
后面查询到re.findall()这个方法:
- re.findall(‘pattern’,string)
- pattern是一个正则表达式,string 是要搜索的字符串
建议将代码换成:
re.findall(“[\u4e00-\u9fa5]”,response.text)
import requests
import re
# 构造请求头字典
headers = {
# 从浏览器中复制过来的User-Agent
"user-agent": "用你自己的user-agent",
# 从浏览器中复制过来的Cookie
"cookie": "你自己得到cookie"
# 请求头参数字典中携带cookie字符串
}
response = requests.get("https://www.zhihu.com/creator", headers=headers)
data = re.findall("[\u4e00-\u9fa5]",response.text)
print(response.status_code)
print(data)
[\u4e00-\u9fa5]
这个正则表达式的意思是获取里面所有的中文
我代码结果图如下:

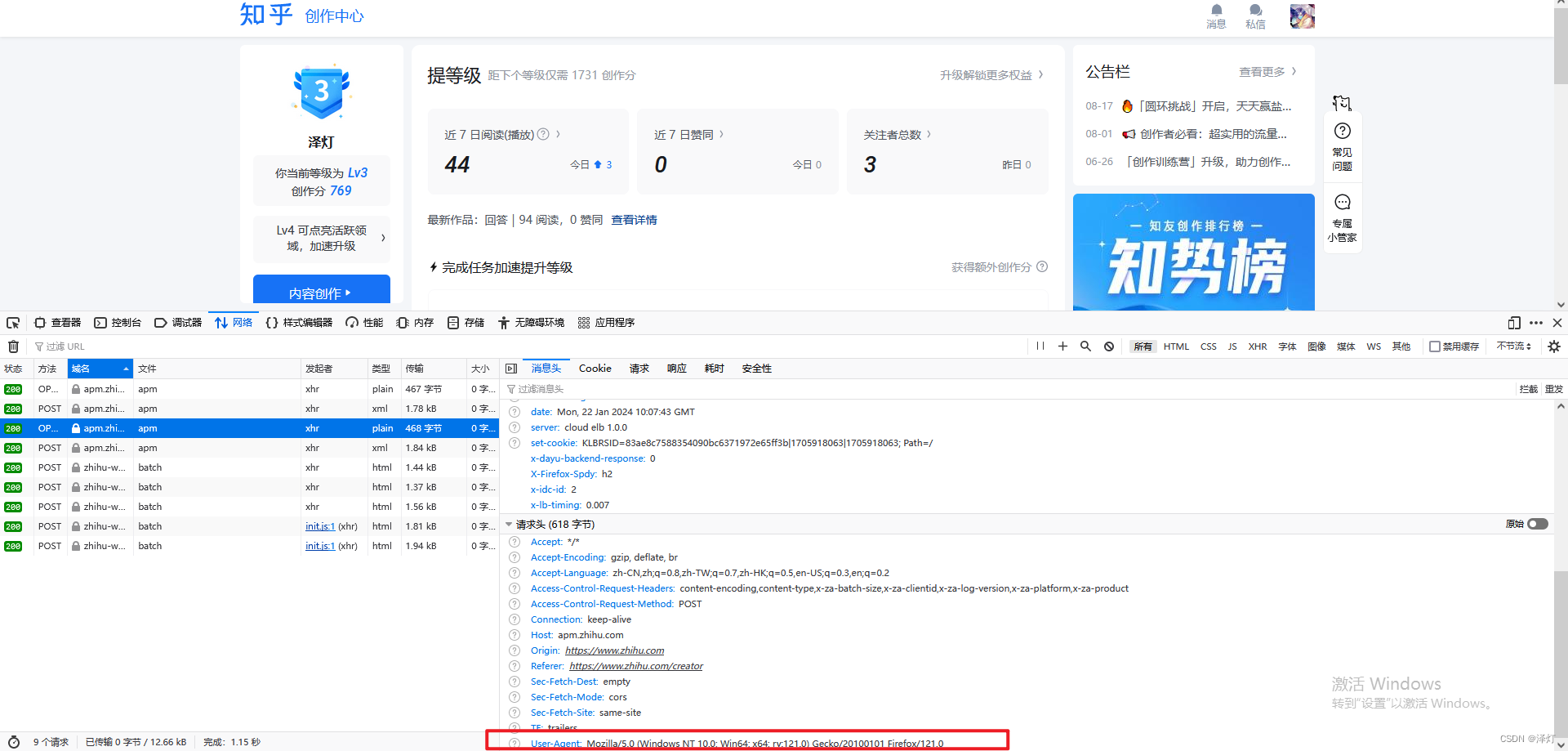
部分代码获取方式:
1,user-agent获取方式,F12以后随机选择一个借口,查找user-agent
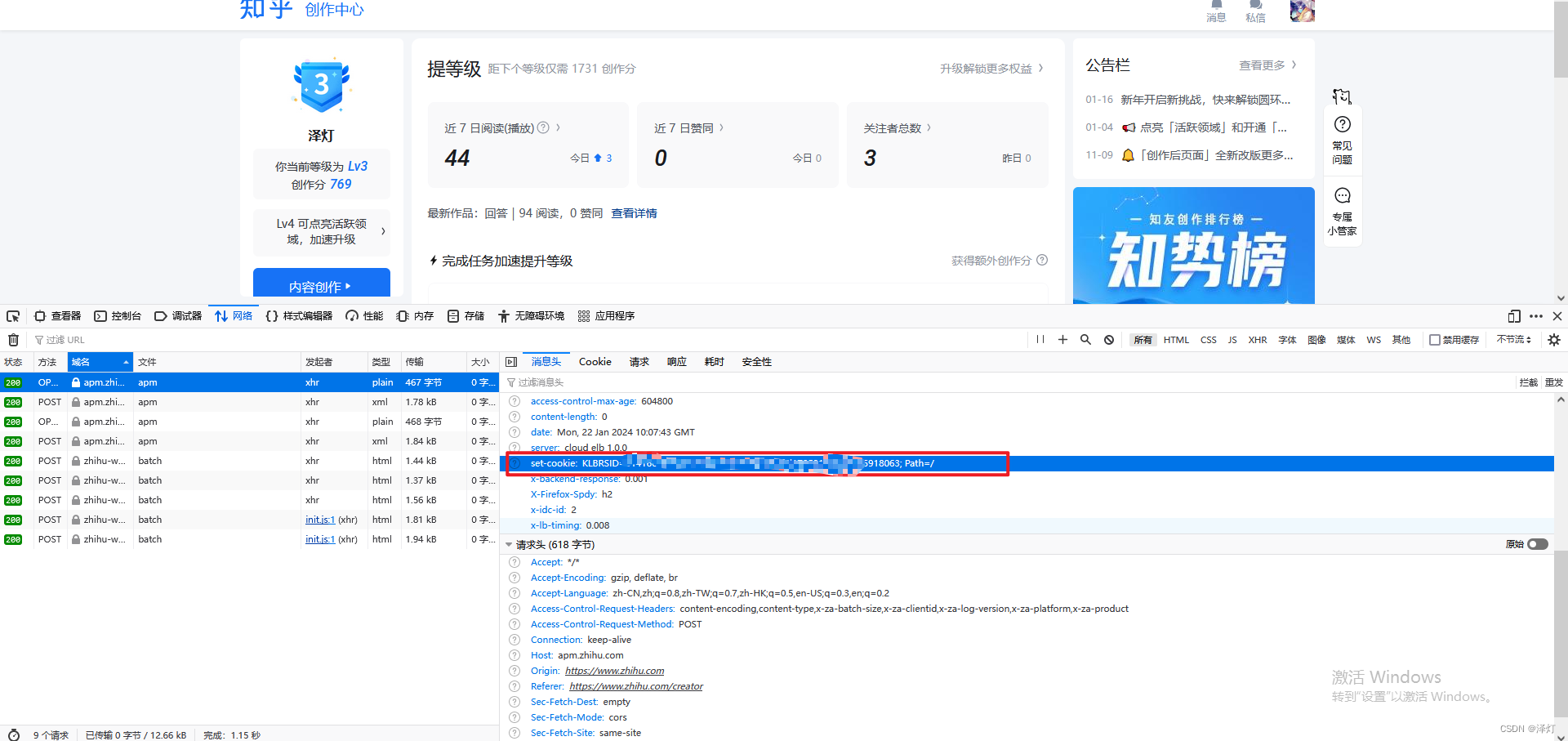
 2,cookie获得方式,最好找上面的第一个接口
2,cookie获得方式,最好找上面的第一个接口
如果有理解这个代码的大佬请评论,我将非常感谢:
CreatorHomeAnalyticsDataItem-title.?>(.?)</div>
CreatorHomeAnalyticsDataItem-title.*?>(.*?)</div>


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









