







Mysql深入初识
Mysql架构
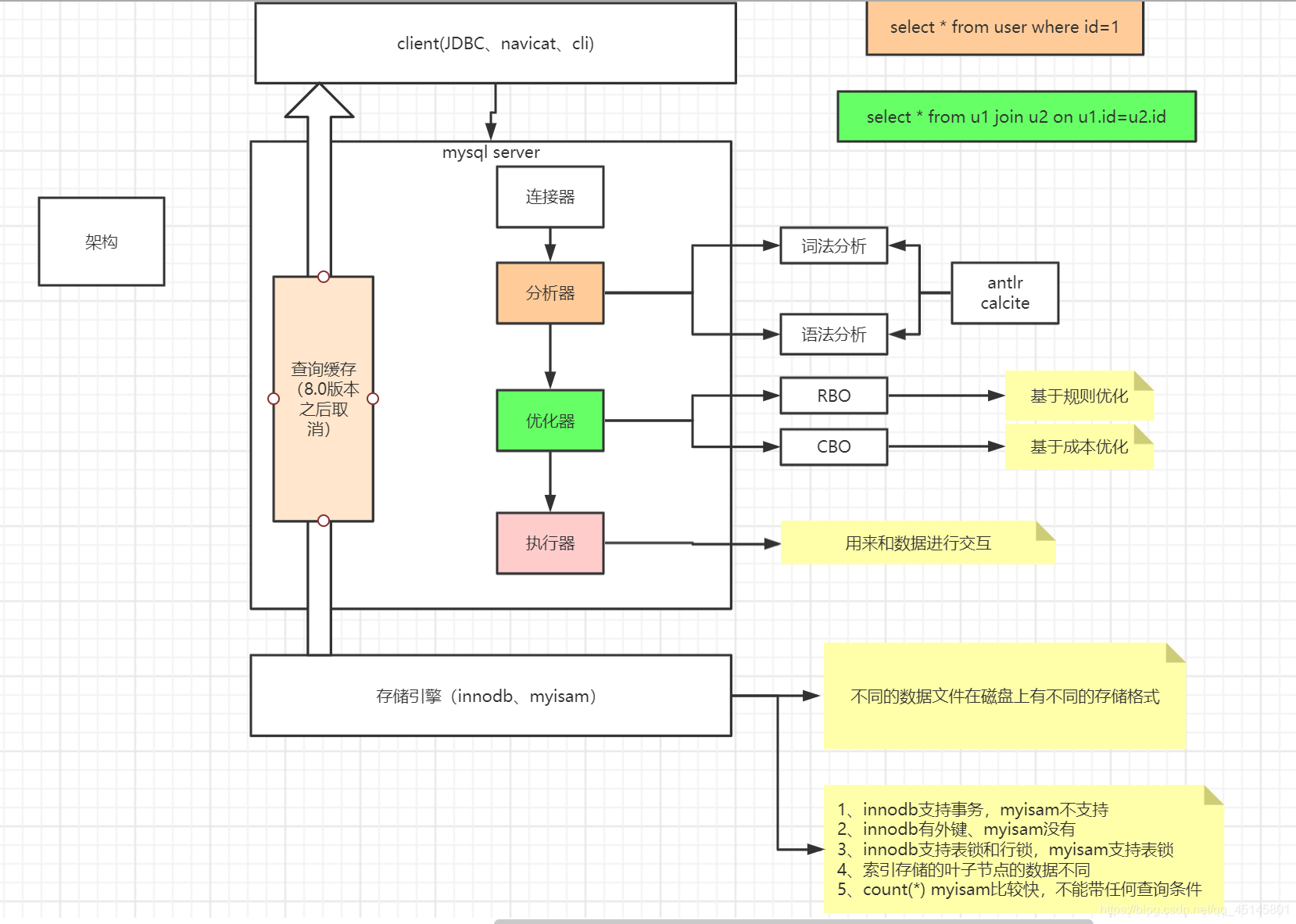
Mysql的架构主要有三个模块:
-
Client(客户端)
提供连接MySQL服务器功能的常用工具集
-
Server(服务端)
MySQL实例,真正提供数据存储和数据处理功能的MySQL服务器进程
Server层包括连接器、分析器、优化器、执行器和查询缓存
连接器:管理连接,权限校验
分析器:对Sql进行词法分析和语法分析
优化器:执行计划生成,索引选择
执行器:操作引擎,返回结果
查询缓存:对数据进行缓存,再次查询时命中可直接返回 -
Engine (存储引擎)
负责提取和存储数据
Mysql优化:需要根据架构进行优化
连接器:show processlist;查询连接,可杀掉一部分没有用的链接
分析器:程序写死,无法进行优化
优化器:可进行索引优化
查看当前语句的执行计划
官网对执行计划explain的解释为:根据表,列,索引的详细信息以及WHERE子句中的条件,MySQL优化器会考虑多种技术来有效执行SQL查询中涉及的查找。可以在不读取所有行的情况下执行对巨大表的查询。可以在不比较行的每个组合的情况下执行涉及多个表的联接。优化器选择执行最有效查询的一组操作称为“查询执行计划”,也称为 EXPLAIN计划
EXPLAIN SELECT * FROM `user` WHERE id=2;

注:对于执行计划来讲,还是要先需要了解索引
索引系统(重中之重)
索引是怎么存储的
索引是必须要进行持久化存储的,除了memory这种存储引擎基本都是需要落盘的。
索引在进行读取时需要返回什么
若自己设计索引要考虑的索引返回值有以下三个:
- key值
- 文件名称
- offset(偏移量)
在大数据领域,hive但是对于Mysql来讲,并没有使用这种返回格式,究其根本,如果数据量很大会导致索引文件也很大,那么会导致IO次数和IO的量都会增加,从而会降低性能。
(Mysql是关系型数据库,需要的是时效性高,Hive是数据仓库,更多的是对数据进行分析,产生决策性影响。)
Mysql是怎么存储索引的
数据格式:key-value
数据结构:hash、树
Mysql采用了什么数据结构
采用什么数据结构是和使用的哪种存储引擎相关的。
可通过SHOW INDEX FROM `user`;查看
hash:memory使用
BTree:innodb、myisam使用(但其本质是B+Tree)
为什么Hash不被innodb使用
hash的结构如下:
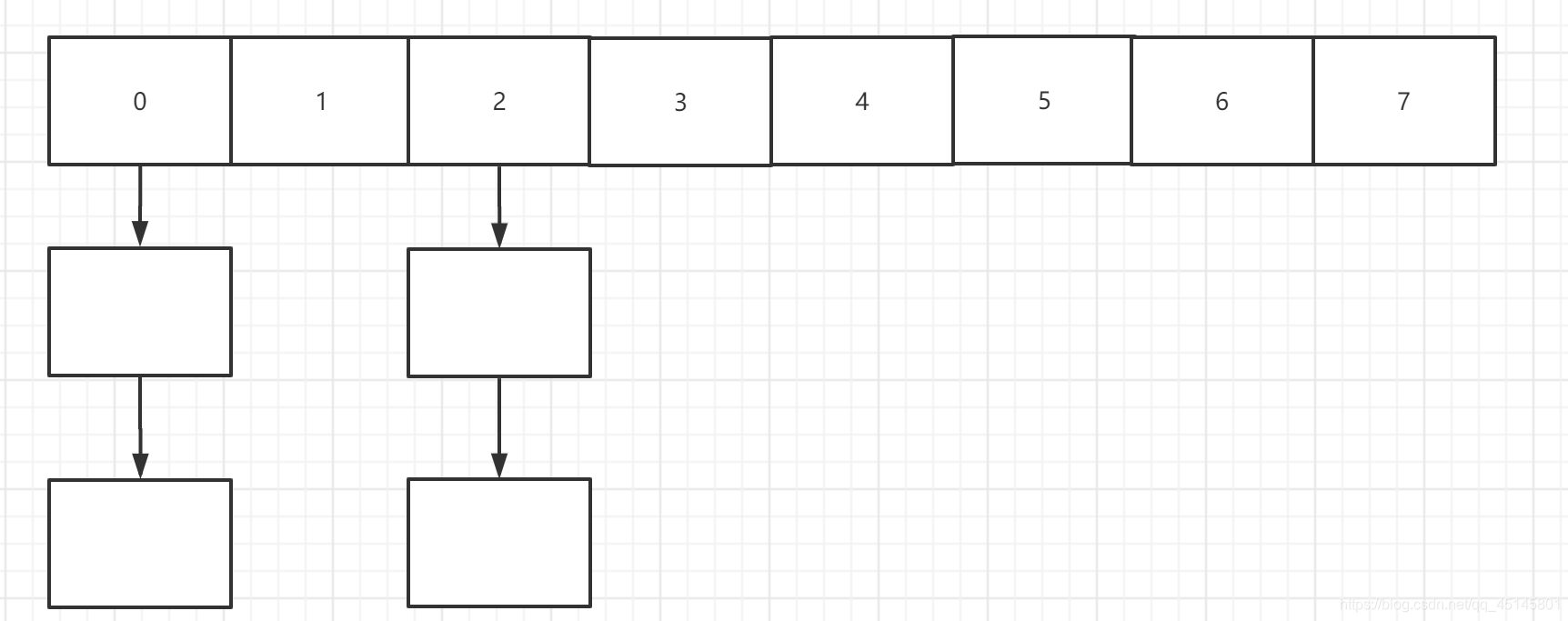
数组+链表,如果要使用Hash结构,需要良好的Hash算法来实现散列均匀,并且Hash表需要大量内存,在进行范围查询时需要每个桶轮流查找,不适合大量范围查询(但其实在实际业务中更多的反而是范围查询)。
为什么要选择B+Tree
树的分类有很多种:
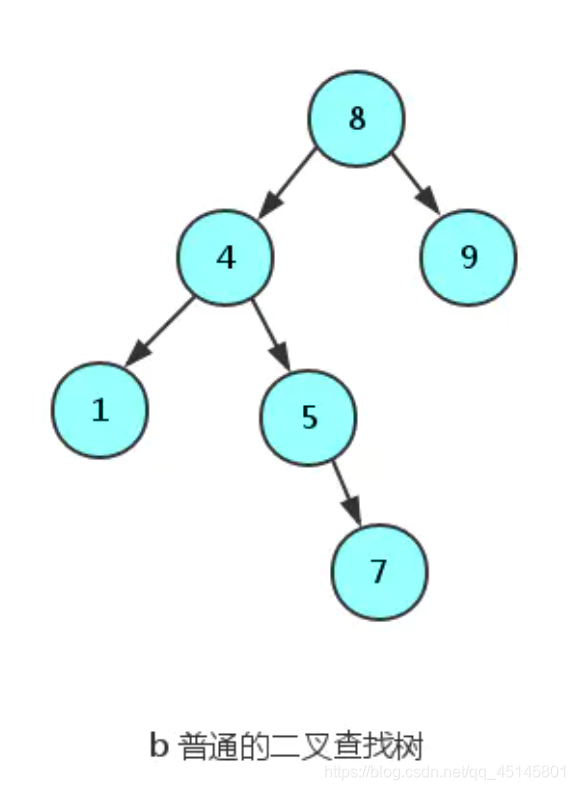
BST(二叉查找树)
元素是有序的,特点是:
- 任意节点左子树不为空,则左子树的值均小于根节点的值
- 任意节点右子树不为空,则右子树的值均大于于根节点的值
- 任意节点的左右子树也分别是二叉查找树
- 没有键值相等的节点
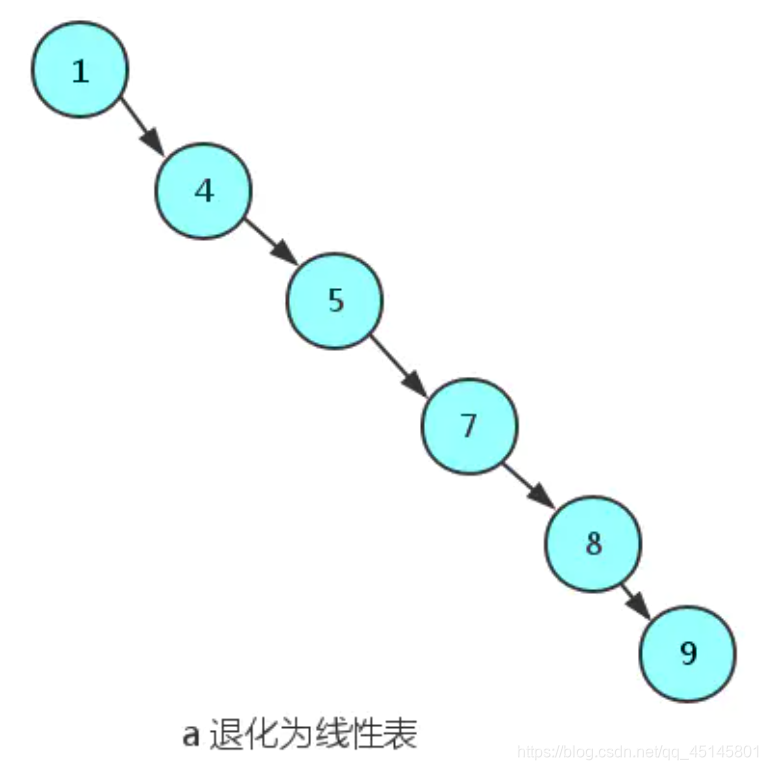
局限性
当输入的元素都是递增或递减时会退化成线性表,此时不会体现树的查找优势。
AVL(二叉查找平衡树)
带有平衡条件的二叉查找树,平衡条件:所有节点的左右子树高度差不超过1,不管是在执行插入还是删除时,只要当树不满足这个条件时就会通过自旋来保持平衡(自旋过程是很耗时的,也就是说AVL通过牺牲插入和删除的性能来提高查询的性能)。
使用场景:
- AVL树适合用于插入删除次数比较少,但查找多的情况。
- 也在Windows进程地址空间管理中得到了使用
- 旋转的目的是为了降低树的高度,使其平衡
AVL树特点:
- AVL树是一棵二叉搜索树
- AVL树的左右子节点也是AVL树
- AVL树拥有二叉搜索树的所有基本特点
- 每个节点的左右子节点的高度之差的绝对值最多为1,即平衡因子为范围为[-1,1]
红黑树
也是一种二叉平衡树,但是他自旋的条件相比AVL要宽松许多,即红黑树确保从根到叶子节点的最长路径不会是最短路径的两倍,用非严格的平衡来换取增删节点时候旋转次数的降低,任何不平衡都会在三次旋转之内解决
使用场景:
红黑树多用于搜索,插入,删除操作多的情况下
红黑树应用比较广泛:
- 广泛用在C++的STL中。map和set都是用红黑树实现的。
- 著名的linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块。
- epoll在内核中的实现,用红黑树管理事件块
- nginx中,用红黑树管理timer等
局限性
随着数据的积累,树会增高,导致查询的IO次数增多。
B树
B-Tree是多叉树,能够保证数据有序。其中可以固定Max.Degree,也就是树的阶数,当为3阶时,表示一个节点中的数据最多不超过2个,即(Max.Degree-1),如下图所示:
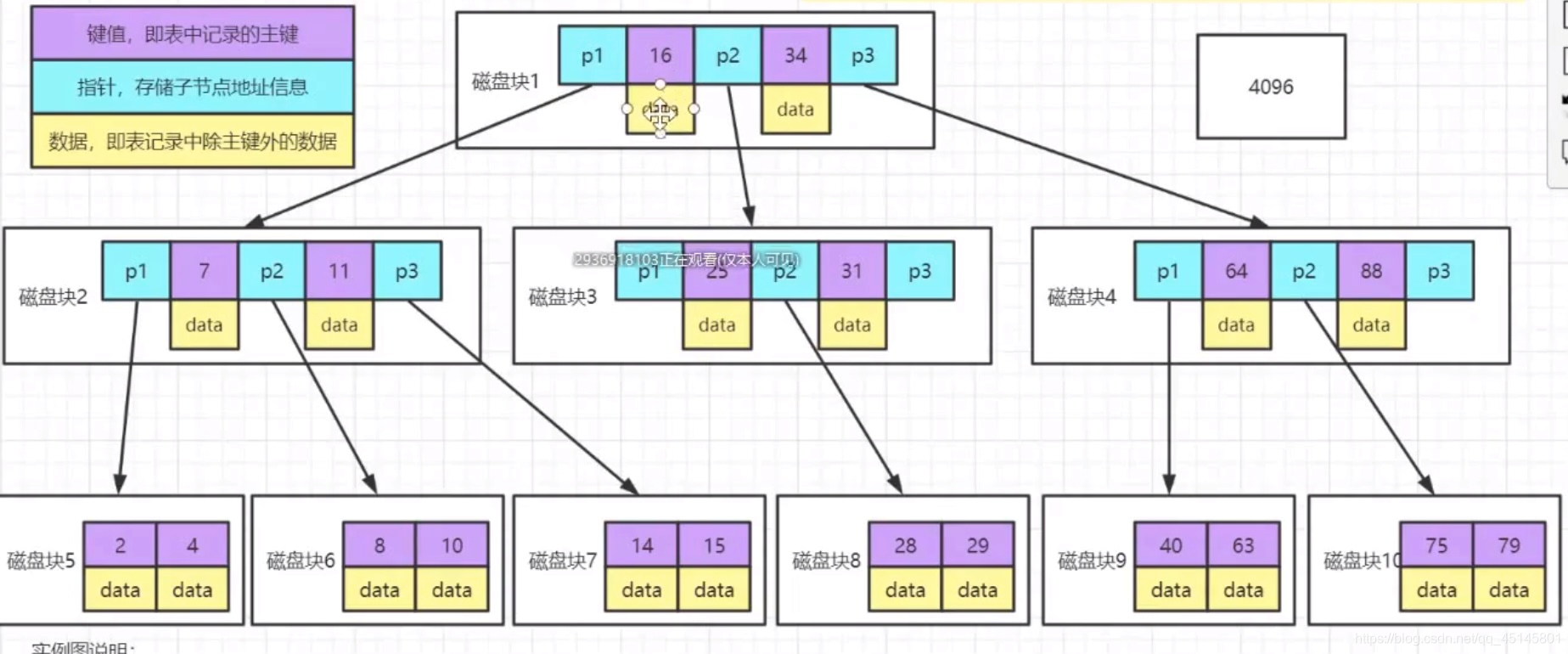
B+树
B+树是B-树的变体,也是一种多叉树
B+的搜索与B-树也基本相同,区别是B+树的真实数据都是存储在叶子结点,这样保证在非叶子节点保存的分叉数据会更多,这样可以使B+树用很少的层级保存更多的真实数据。
B+的特性:
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的
- 不可能在非叶子结点命中
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层
- 更适合文件索引系统
原因: 增删文件(节点)时,效率更高,因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率,如当Max.Degree=3时:
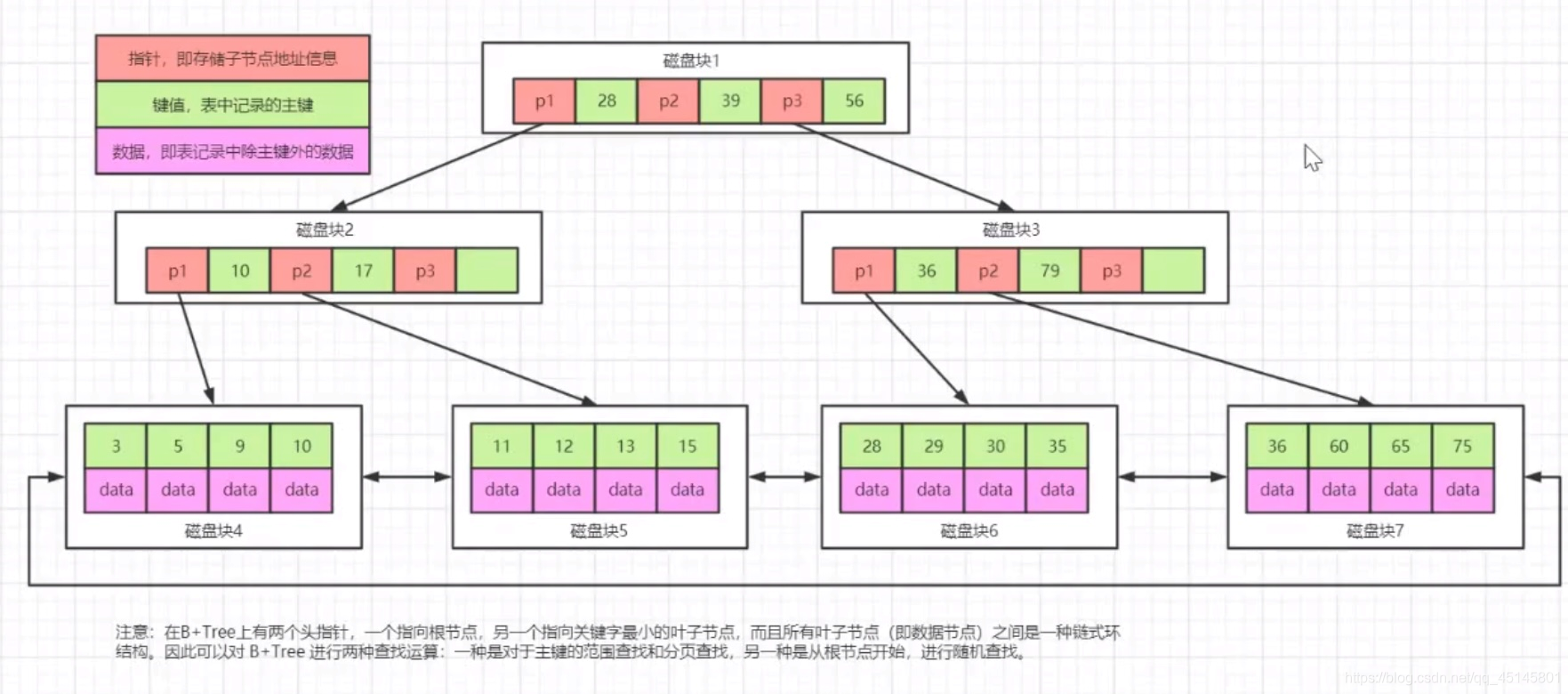
使用场景:
文件系统和数据库系统中常用的B/B+ 树,他通过对每个节点存储个数的扩展,使得对连续的数据能够进行较快的定位和访问,能够有效减少查找时间,提高存储的空间局部性从而减少IO操作。他广泛用于文件系统及数据库中,如:
Windows:HPFS 文件系统
Mac:HFS,HFS+ 文件系统
Linux:ResiserFS,XFS,Ext3FS,JFS 文件系统
数据库:ORACLE,MYSQL,SQLSERVER 等中
Mysql的B+树的高度一般是在3-4层。
在设置索引时,要尽可能避免使用varchar,如果非要使用varchar,可以对数据进行截取优化
Mysql中怎么实现的索引
Mysql InnoDB—B+Tree叶子节点直接放置数据
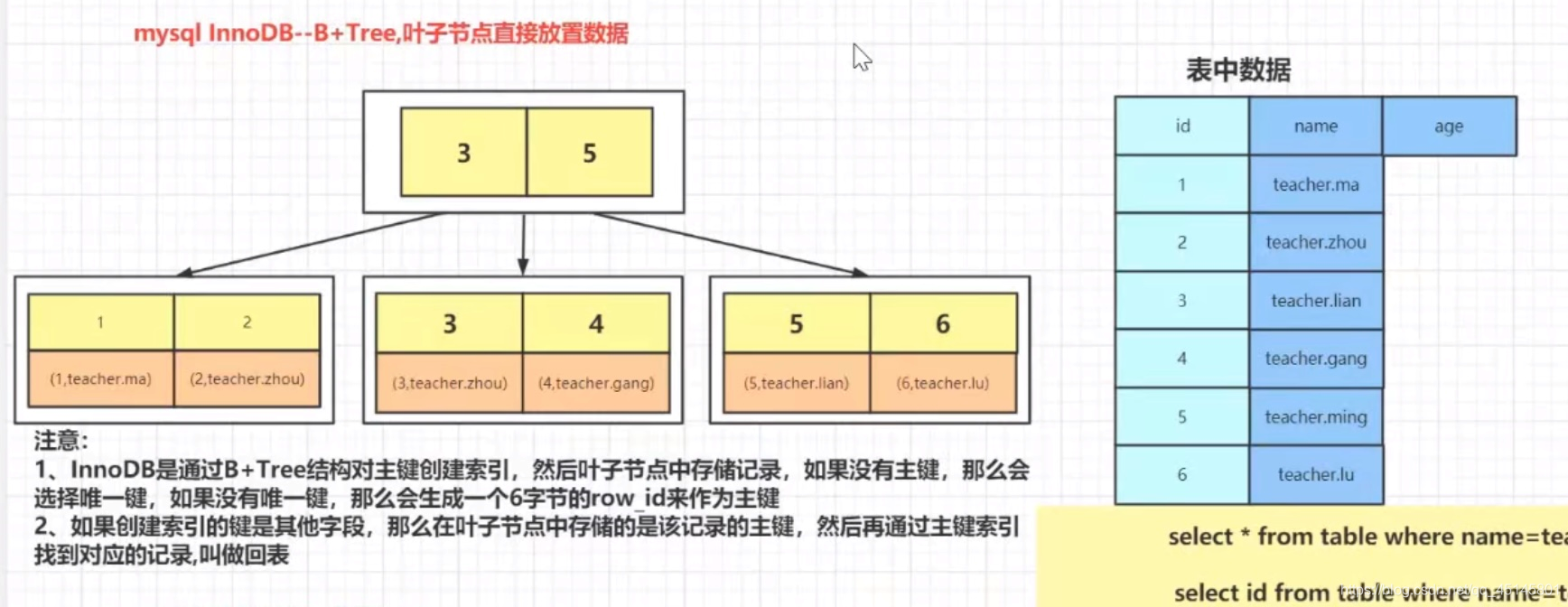
注意:
- InnoDB是通过B+Tree结构对主键创建索引,然后叶子节点中存储记录,如果没有主键,就选择唯一键,如果没有唯一键,就会生成一个6字节的row_id作为主键
- 如果创建索引的键是其他字段,那么在叶子节点中存储的是该记录的主键,然后再通过主键索引找到对应的记录,叫做回表
Mysql Myisam—B+Tree叶子节点放置数据的存储地址
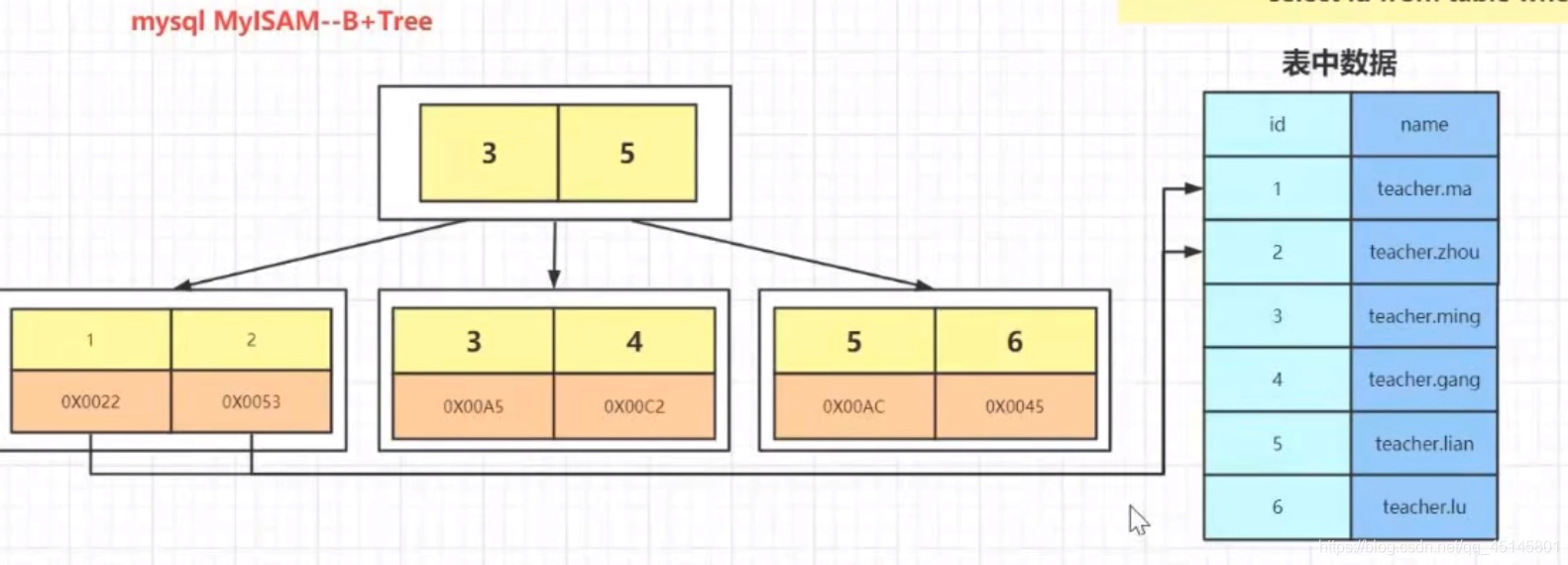
索引分类
聚簇索引
结合具体表来看:
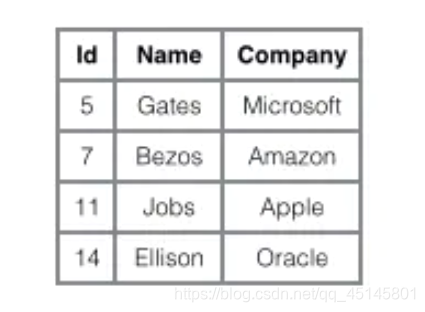
数据和索引时放在一起的(innodb)
注意:
- 一个表的聚簇索引不一定是主键索引
- 一个表的聚簇索引不会有很多个,只有一个
- 主键索引一定是聚簇索引吗?
假如创建表的时候没有主键,没有唯一键,添加数据之后,设置了主键,这时候的索引内容会变吗?
会变,在没有主键没有唯一键的情况下会创建row_id来存储索引,当存储了数据之后再设置主键,索引会变为聚簇索引,这是因为使用row_id存储了聚簇索引,再创建主键时,又会创建一个B+树,此时如果在这棵树保存的是聚簇索引的row_id,再查找时相当于要查两棵树,效率不高,索引Mysql选择在创建主键时生成一个主键聚簇索引来代替row_id的聚簇索引,尽管重新生成索引时会浪费一些时间,但是在后续查找数据时会很快。 - innodb的普通列索引是非聚簇索引
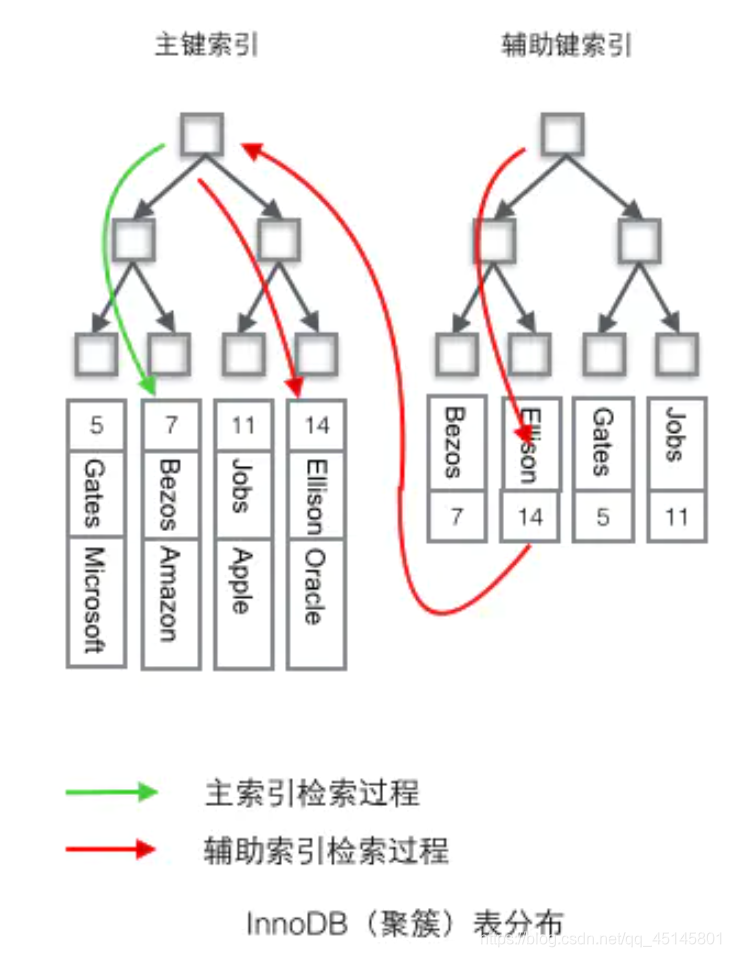
非聚簇索引
数据和索引不放在一起(myisam)
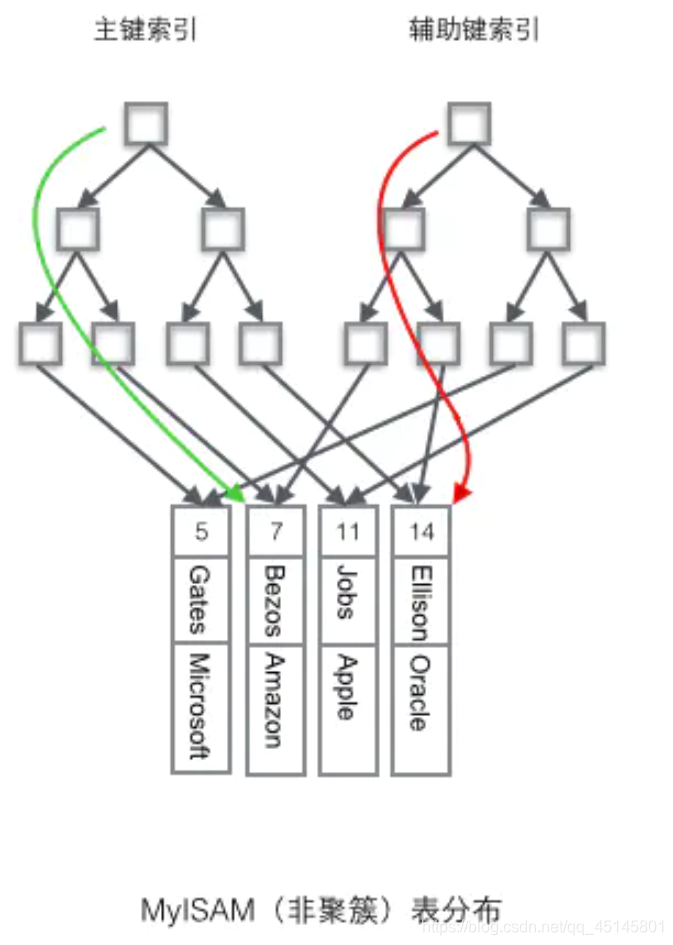
几个类型的索引?
主键索引
主键列做索引
唯一索引
唯一键的列做索引
普通索引(辅助索引或二级索引)
普通列做索引
回表
一个表的结构如下
id-主键
name-普通索引
age-int
gender-varchar
select * from user where name=“张三”;
从普通索引的树找到id,再根据id值去主键树找到整行的记录,称之为回表;
索引覆盖(性能更高,减少IO,SQL语句优化时可尽量保证其使用索引覆盖)
select id,name from user where name=“张三”;
此时只会通过name的B+树找到要查询的所有字段,可以直接返回,不需要再去查找主键索引,此时叫索引覆盖;
全文索引
innodb在5.6之后支持全文索引,不经常被使用,可以使用lucene、solr、es上,Mysql使用全文索引是没有必要的。
组合索引(联合索引)
之前的索引中都是只包含一个字段,当一个索引列里面有多个字段时就被称为组合索引。
B+ 树的结构如下:
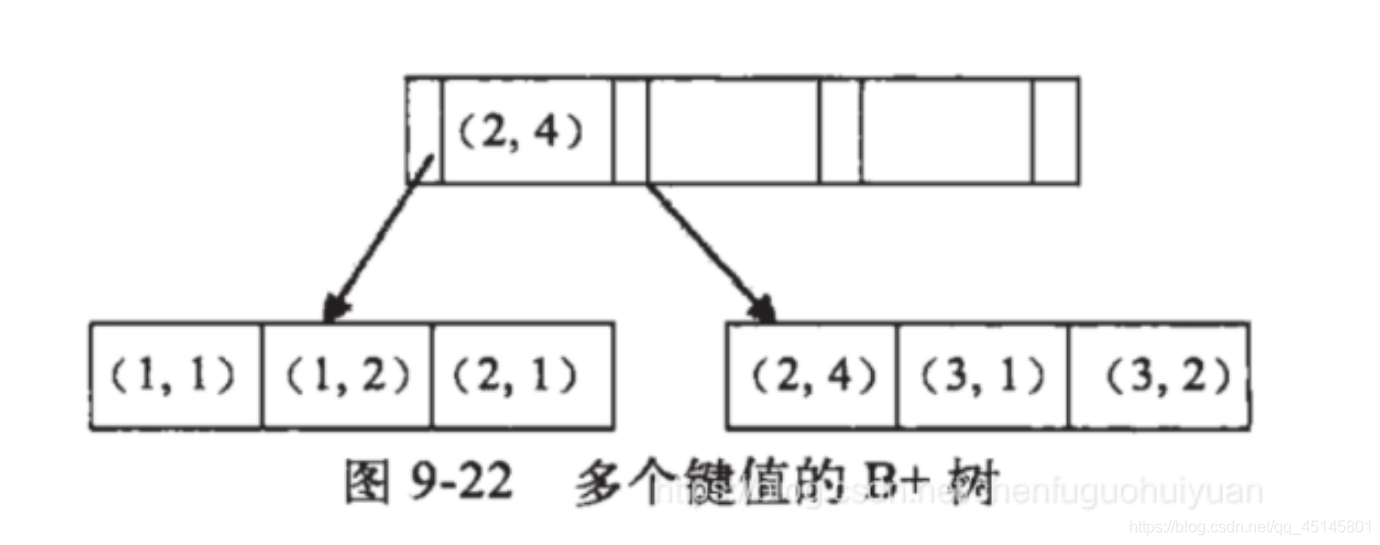
最左匹配
在只有一个索引列时存储需要有序,当有多个列时也需要保证有序,此时有一个最左匹配原则:每次匹配从第一个列开始匹配,要全部匹配时才会使用此组合索引。
注意:
- 当一个表里的所有列都是索引列时不会符合最左匹配原则。
- 查询条件中包含等号时可以使用索引,如果是范围的话会不使用索引
- 索引失效条件之一:> 或 <等做范围查询
- 索引失效条件之二:like模糊匹配%为第一个字符时
- 索引失效条件之三:条件子句中字段那一边不能有表达式
- 索引失效条件之四:条件子句中有函数
- 索引失效条件之五:SQL中的隐式类型转换会导致索引失效
- 索引失效条件之六:or和and有可能会导致索引失效,视情况而定
索引下推(在使用组合索引情况下)
select t1.name,t2.name from t1 join t2 on t1.id=t2.id;
执行方式有两种:
- 将两张表按照id字段进行关联,获取到对应的数据(IO量大)
- 把两个表需要的字段取出来然后再进行关联(IO量少)
(sql下推\谓词下推)
select * from user where name=‘张三’ and age=18;
这句SQL在执行时是怎么执行的?
首先是执行器从存储引擎中 根据name的条件获取到所有的数据,然后将结果在执行器中按照age进行条件过滤。(即两个条件是在不同的地方执行的,一个是在存储引擎,一个是在Server)
后来在5.7引入索引下推之后,执行方式变成根据name和age两个条件从存储引擎中做数据筛选,取出对应的结果。(所有的条件都是在存储引擎中执行的)
当使用了索引下推时执行计划中的Extra字段的值为Using index condition
索引类型总结
一般情况下,SQL语句中尽可能多的带主键字段,方便进行查询,但是主键字段的条件一定会生效吗?
答案是不一定,
索引匹配方式
创建一个测试表tb_test,字段如下图:
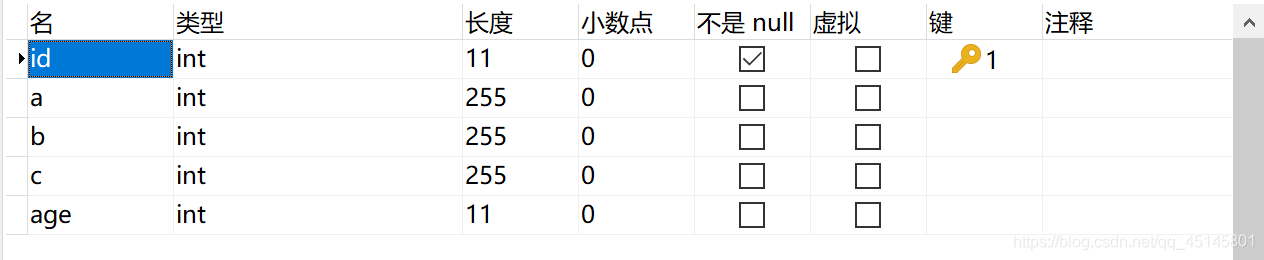
创建联合索引:

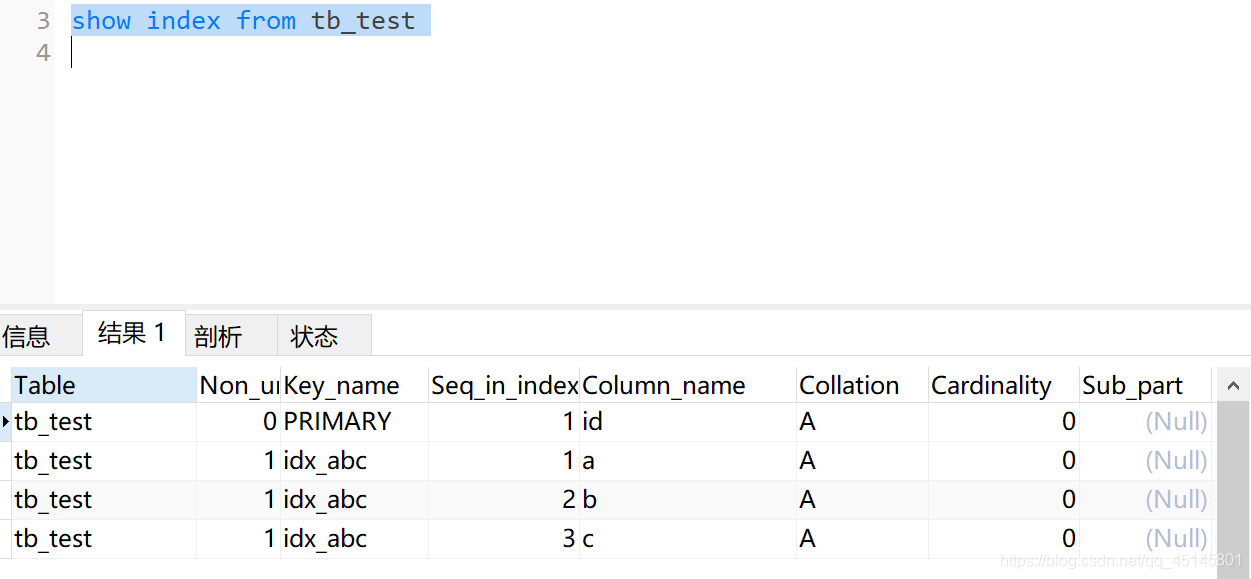
查询索引个数:
全值匹配
和索引中的所有列进行匹配
explain select * from tb_test where a=1 and b=2 and c=3;

匹配最左前缀(最左匹配原则都是针对联合索引来说的)
只匹配前面的几列。最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
explain select * from tb_test where b=2;

但是如果查询条件是a = 1 and b = 2或者a=1(又或者是b = 2 and a = 1)就可以,因为优化器会自动调整a,b的顺序。再比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。
匹配列前缀
可以匹配某一列值的开头部分:
使用索引: explain select * from staffs where name like 'j%' ;
索引失效: explain select * from staffs where name like '%j%' ;
匹配范围值
可以查找某一范围的值:
explain select * from tb_test where a>2;

精确匹配某一列并范围匹配另外一列
可以查询第一列的全部和第二列的部分:
explain select * from tb_test where a=1 and b>2;

只访问索引的查询
查询的时候只需要访问索引,不需要访问数据行,本质上就是索引覆盖。
explain select a,b,c from tb_test where a=1 and b=2 and c=3;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









