







前言
相信对于新入门大模型微调和应用的小伙伴来说,网上的一些教程更多的是告诉怎么使用或者对大模型算法的研究,但是这样的问题是如果没有跟着系统的教程过度,码友们特别是刚入门大模型使用的小白们学到的东西很朦胧或者是不能理解,这篇文章主要是带大家浅浅认识一下一些大模型框架或者套件的使用的背后组成原理。
简介
这次教程是基于昇思国产深度学习框架(但是讲的东西都是比较普适的,最后我会发散的),先简单给大家回顾介绍一下什么是mindspore和mindformers及其关系吧
MindSpore 是由华为公司开发并开源的新一代全场景人工智能(AI)计算框架。它于2019年8月首次推出,并在2020年3月28日正式宣布开源。MindSpore 的设计目标是实现易开发、高效执行和全场景统一部署,以支持从端侧到边缘再到云端的各种设备。
简单的理解呢,就是相当于国产的pytorch(仅仅是简单这样认为哈,还是很多不一样的)
MindFormers 是 MindSpore 生态系统中的一个子项目,它是一个专注于预训练模型的工具包。MindFormers 提供了一系列先进的预训练模型以及相关的训练和推理脚本,使得开发者能够快速地利用这些强大的模型进行研究或应用开发。MindFormers 包含了多种类型的预训练模型,如:自然语言处理(NLP):包括 BERT、GPT 等。计算机视觉(CV):例如 ViT(Vision Transformer)、Swin Transformer 等。多模态学习:结合文本和图像等多种数据类型的模型。
通过 MindFormers,用户可以方便地加载已有的预训练权重,对特定任务进行微调(fine-tuning),或者使用这些模型直接进行推理。此外,MindFormers 也提供了详细的文档和支持,帮助用户更好地理解和使用这些模型。
简单的理解就是,它就像是基于mindspore框架的,对标hugging face的transformers库的mindspore transformers库
使用模式介绍
使用这种套件或者框架,想必大家无论官网还是网上教程,看到的更多的是分为下面这两种使用:
命令启动:

mindformers官网启动教程

随便在csdn截图的某大神微调
高级api方式自定义:

随便在csdn找的佬的代码
总结一下,这两种方式,一种是脚本语言启动,一种是高级api方式代码启动。前者启动更快,封装更好,但相关的脚本参数以及命令可能对新手来说,特别是不理解背后运行原理的小伙伴来说还是比较难理解的吧(完全就是黑箱子,即使能看懂命令什么意思,但也会怀疑为什么~~)。后者更灵活,更自定义变化,对理解上比第一种更友好,而且其实也是第一种的底层代码实现
使用模式理解
这里先做个小总结:可以简单的理解为:上面的两种方式,前者是后者的封装层面的应用,也可以说是高一个维度运用,前者的底层代码,其实也就是后者,不想看分析过程的,可以直接跳结论
感觉看到上面那些教程后,无从下手,即使从第二种方式入手,也只是简单的学会了几个api的调用,虽然已经足够并且灵活的进行大模型的微调与使用,但是很明显如果没有一定实力,那么任务构建起来肯定效率不高(封装度比较低,虽然灵活,但是可能调试过程中会遇见很多坑~),大型复杂任务自定义配置(比如分布式训练等等)
我们先简单的从较高层面的脚本层面简单看看(不会脚本不要紧,小编最开始也不是很会,这里只是大概看看),这个时候,我们先忘记对mindformers的框架套件认识(从官网简单认识一下这是什么)
首先,我们先完全按照官网说的方式傻瓜式进行下载,在linux环境下能明显看到多了一个mindformers包,其实按照官网的方式,用git,就是将这个包下载到当前项目路径,pip只是下载到当前py环境路径,但是,都是下载了这个包。这里面有个.md文件,这种文件一般都是一些指导性文件,如下:
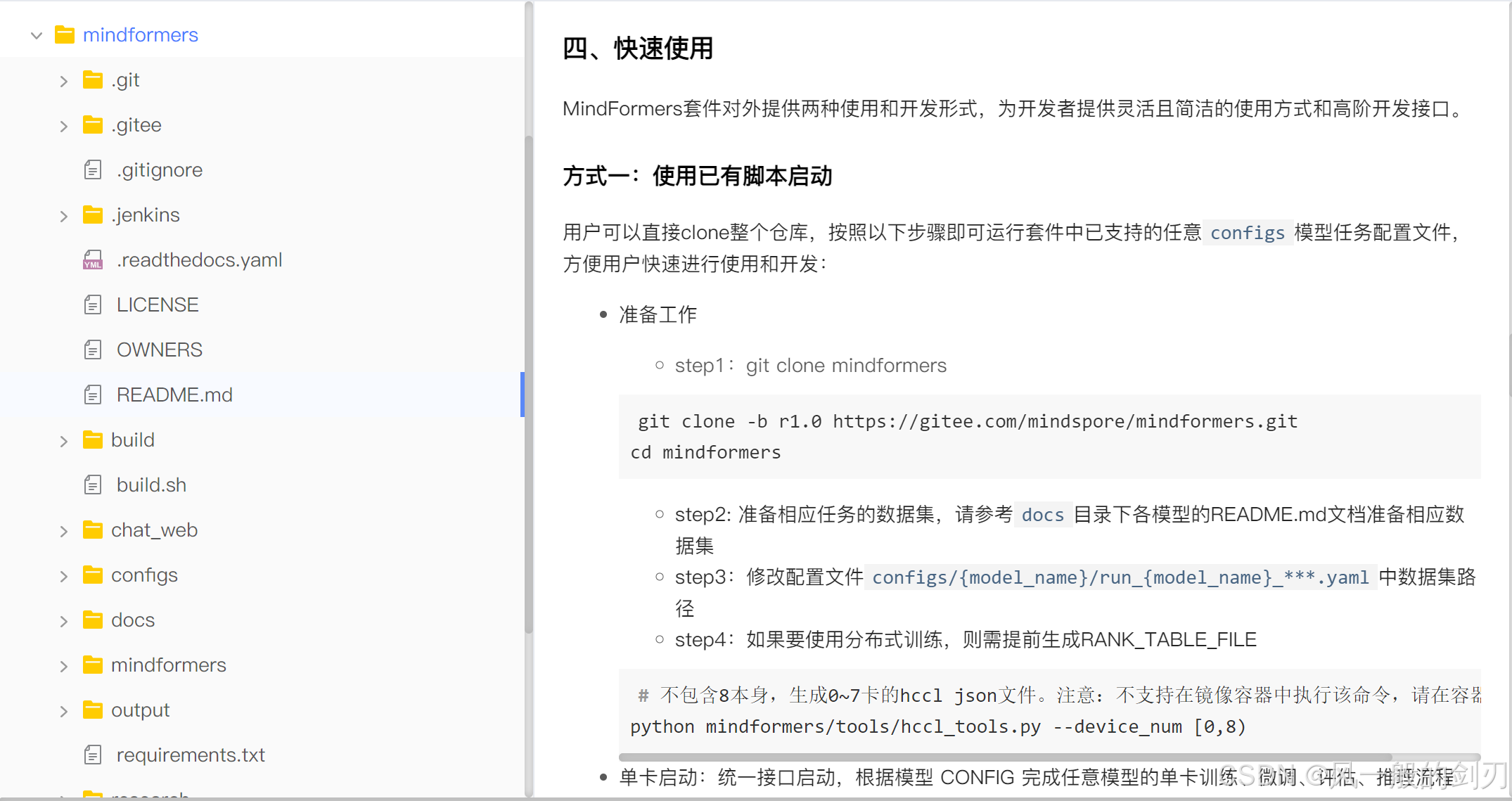
按照官网教程,使用最简单的单卡启动,这里先是cd进去这个包(简单的命令默认大家都会哈)
然后看到单卡启动其实就一行命令吧:


,简单分析(不会使用,没关系,这里能看懂意思就行)其实就是启动运行一个python程序,然后传入了配置文件地址,运行模式,再然后就完了。
先不急着照着上面启动程序,因为读到这里想必大家还是比较朦胧,这启动了个什么玩意,我们再看看官网一个比较有明确意义的任务:GPT2从头开始
gpt2模型大概应该还是了解一些原理吧,不了解也没事,这里我不会讲模型原理,就暂时把它想做一个黑盒子吧,这里给出mindformers官网关于这里的教程的链接,里面是官网交怎么开始gpt2训练任务:GPT2从头开始实现 — mindformers dev 文档,建议边结合官网的边看我这里的讲解。
文档中前三节是关于模型原理,模型使用高级api开发封装的介绍,可以也需要大家先简单了解一下流程或者是在干什么(可以先不要去直接去看那大段的代码或者深入理解),然后直接先分析第四节,脚本启动。
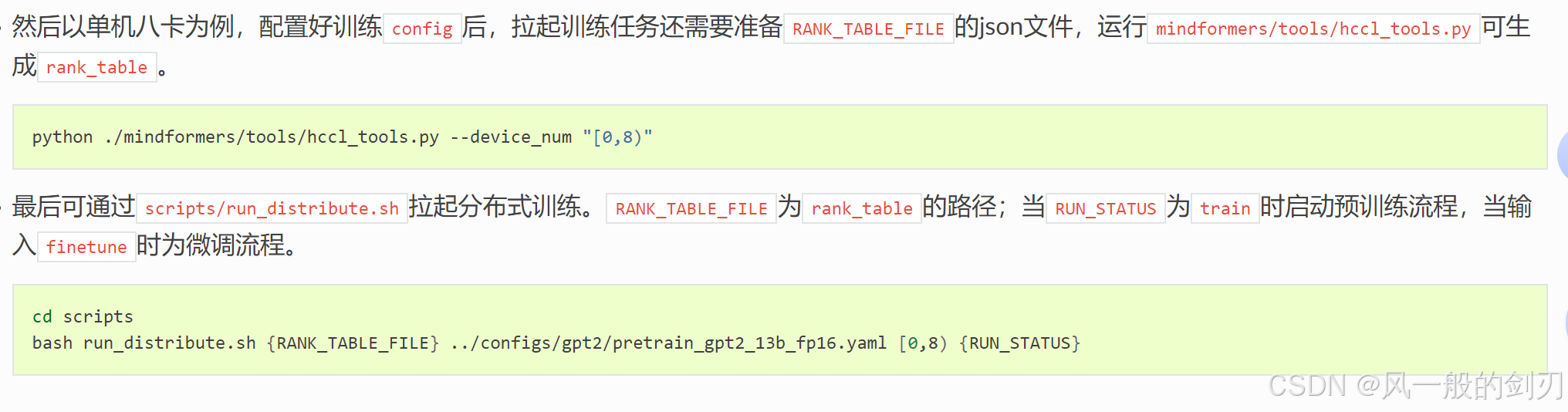
虽然这里是八卡启动,但是,我们可以简单理解或者感受一下大概意思:这里cd进了scripts,然后bash运行了里面一个脚本文件,向脚本传了一些参数,四个参数:里面我们可以看到,配置文件,运行模式等等。按照这里的启动,我们可以进入mindformers相应的路劲查看一下这个启动脚本(cd就是进入文件,bash是一个运行文件,本质都还是在mindformers这个包下面的文件)

这里的位置其实就是,mindformers/scripts/run_distribute.sh(虽然,上面是多卡启动,我们为了简单点,就先看看单卡,本质是一样的)
进入里面是不是一堆脚本语言看不懂,小编也看不懂(就因为这里,小编现在正在开始学脚本语言~~),但是我询问了一下大模型,他帮我分析了里面的相关命令,这是我留下来的询问链接:(这里顺便推荐一波国产chatGPT哦!!!)通义tongyi.ai_你的全能AI助手-通义千问
简单的理解呢就是在里面经过了一些列参数检查后:再执行了下面的这种命令

这个命令呢,大概就是创建了一个专门的新目录,复制了三个文件进去(mindformers包(mindformers/mindformers注意不是大的那个哈),configs,所有当前目录的py),然后运行了里面的一个py文件,传入了一些参数。
这个py文件和刚刚单卡启动那里启动的py文件名字一样欸!都是run_mindformer.py(其实就是同一个文件)瞅两眼这个py文件呢:

看不懂,不要紧,大概就是一些参数的配置和启动嘛,这里我们先就不看了(看不下去了,哈哈哈)。其实结合这里,我们看到配置了这么多参数,加上上面构建的时候,将configs目录是传进来了的,最开始那个启动脚本那里还传了个配置文件路径。我们去看看这个配置文件:
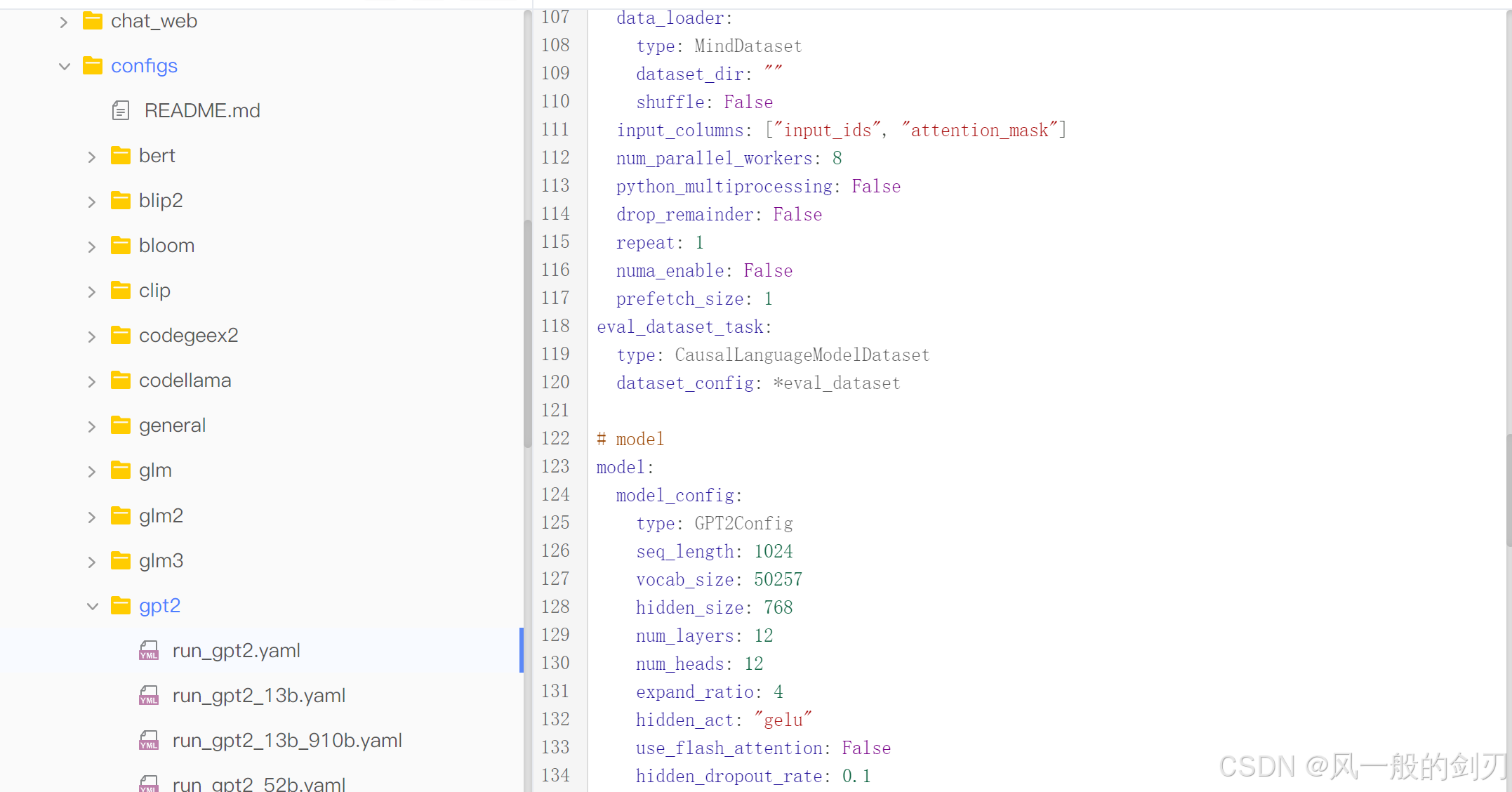
可以看到,这里配置(/mindformers/configs/gpt2/run_gpt2.yaml),其实就是各个模型的一些yaml文件,这整个configs就是一个大的配置文件中心,里面定义了各种参数,比如模型结构,训练设备,训练输出路径,数据预处理相关参数,数据集相关约定等等。这里还有一个伏笔,这里的这些模型代表什么,下面我要说的。
再结合一下官方教程中刚刚让大家看的前几节的代码,其实就是在mindformers/mindformers这个包下面,已经被封装好了的一些训练代码:
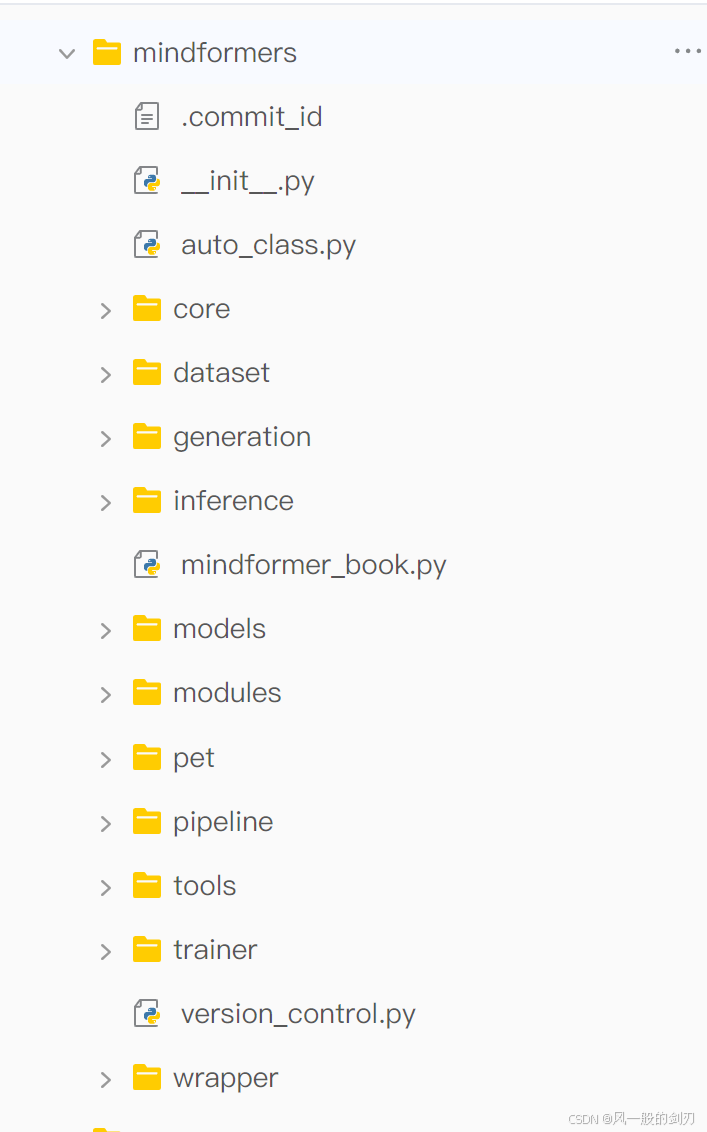
可以看到里面一些较为熟悉的类,什么auto_class呀,pipeline,trainer呀等等,这些也就是我们所说的那些高级api所在的地方。
总的回顾下来,我们再来认识一下两种启动模式,就可以得出我们上面所说的结论,脚本启动,他的逻辑还是启动一些封装好了的代码文件,他的底层还是高级接口启动。我在这里手工画了个较为简单的图,(画得很粗糙,大家感受一下就行了)
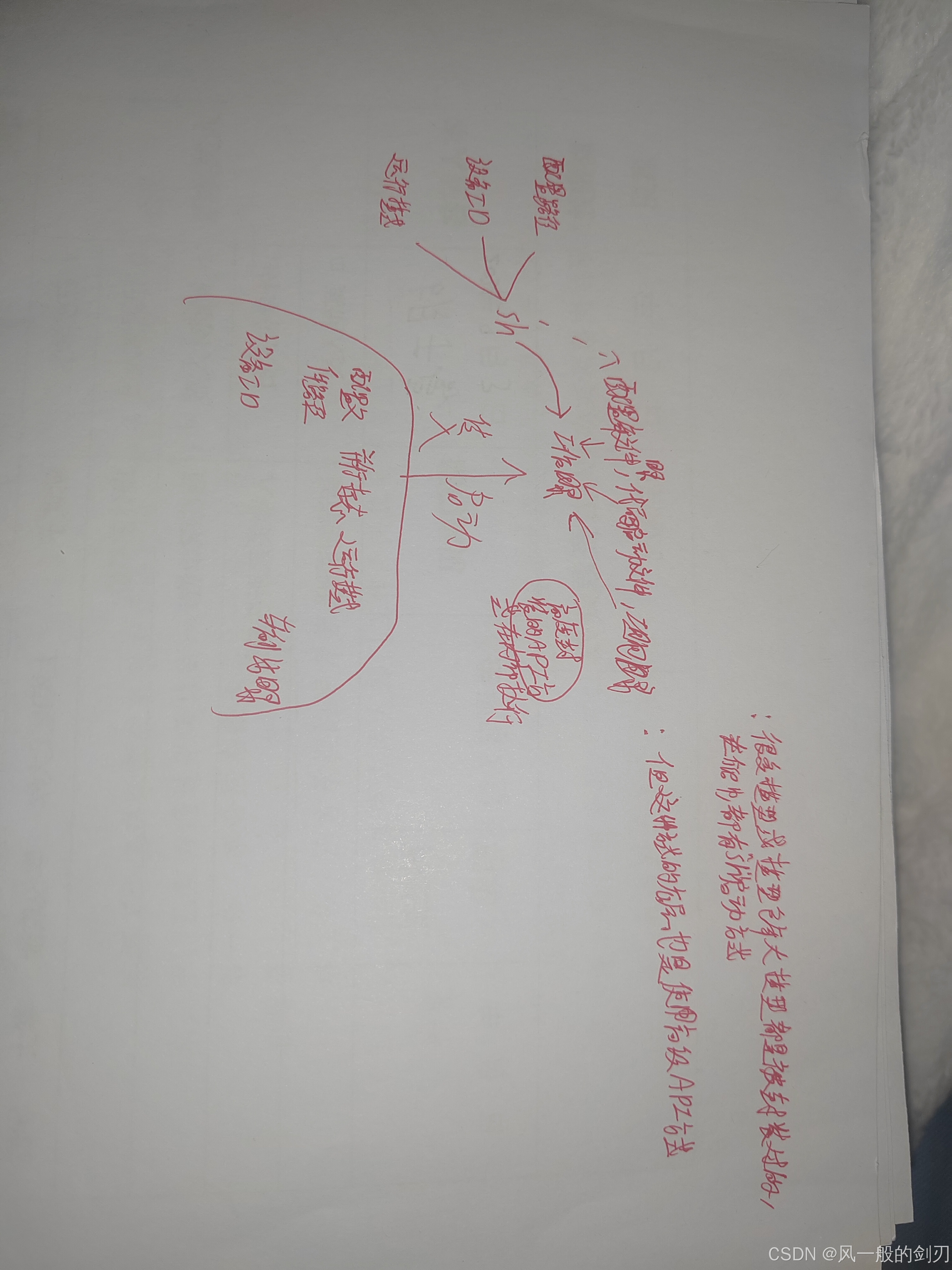
疑问理解
想必虽然大家看了上面的理解后要较为通透点,但还是会有点朦胧,下面跟随着这些疑问,相信大家会对这个理解更为通透
1.这种封装好了的,代码不是很固定吗?怎么实现灵活的微调或者训练任务的?
答:一来,代码虽然结构构建方式比较固定,但是点开配置文件就知道,里面有大量的配置参数,可以很好的适应我们对任务的需求,二来,框架里面封装好了一些支持的任务模式,能够胜任大部分的任务了(这个就要看官网上框架对模型和任务的支持程度了)
2:怎么理解框架支持模型和支持任务这个说法?
答:其实,我这里并没有对框架的一些封装好了的代码进行挖掘分析,但是其实可以这样理解,比如要微调,肯定是准备模型和数据,模型又分为模型结构与模型权重。我们从那些仓库里面拉去的,往往都是模型的权重,模型的结构一般都是模型自己构建,(其实看了我下一篇文章会说到autoModel构建模型的流程,会对这个过程较为深入研究)通过脚本启动,使用框架自带的配置,虽然也会可以自己定义改些配置,但即使通过模型结构的配置来指导框架自动生成模型结构,也是需要框架知道怎么读取这些配置来构建模型的。
怎么理解上面那句话呢?就是,初始化模型,需要告诉框架加载什么样的模型(是bert还是gpt,他们的大方向构造都是不一样的),还有就是怎么加载这些模型(gpt中,多头注意力机制分几个头,解码器要几层),这两个都是需要在mindformers这个框架,套件中事先准备好的
再回过头看问题,框架支持这些模型,就肯定有这些模型的相关配置文件(可以发现,config那个文件夹下面的yaml,刚好就是mindformers官网说的所支持的那些文件),框架里面有这些模型的相关类(比如这行代码:from mindformers import GPT2Tokenizer, GPT2Processor, GPT2LMHeadModel),套件框架不可能支持所有的想到的大模型,因为这些配置和内置的类是有限的
3:如今大模型飞快发展的时代,仅仅支持几个类别,不够用呀?
答:这其实是事实,但也是一个错觉,事实:mindformers也在发展扩充,在逐步兼容更多的大模型,但其实强如transformers,也是在发展的(最后我会扩散开来讲到普适情况);错觉:其实,很多的我们看到的那些仓库里面的模型,结构上有很多重复的,只是权重有所不同,经常会看到什么比如bert_base_case和bert_base_uncase这种,他们其实大体结构上都是一样的,可能就是权重参数不一样,预训练的数据集不一样,但实际上都还是bert
重新认识
我们之前使用mindformers或者transformers入门的时候,可能更多的是从高级api入手,我们最开始只是把这个工具当作调用与构建大模型的一个api平台,知道怎么拉去模型,怎么构建任务,确实他也是,但另一方面可以认识是,他其实是一个工具或者工具包,我们是使用了工具所提供的api,构建了工具所能支持的型号的模型,另一方面,工具包里面封装了一些快速便捷构建任务的方式(就是脚本启动),是工具包对自己内部的一个集成的使用模式。
还有一个小案例理解(可以去官网了解一下这个模型文件的构造:魔乐社区):
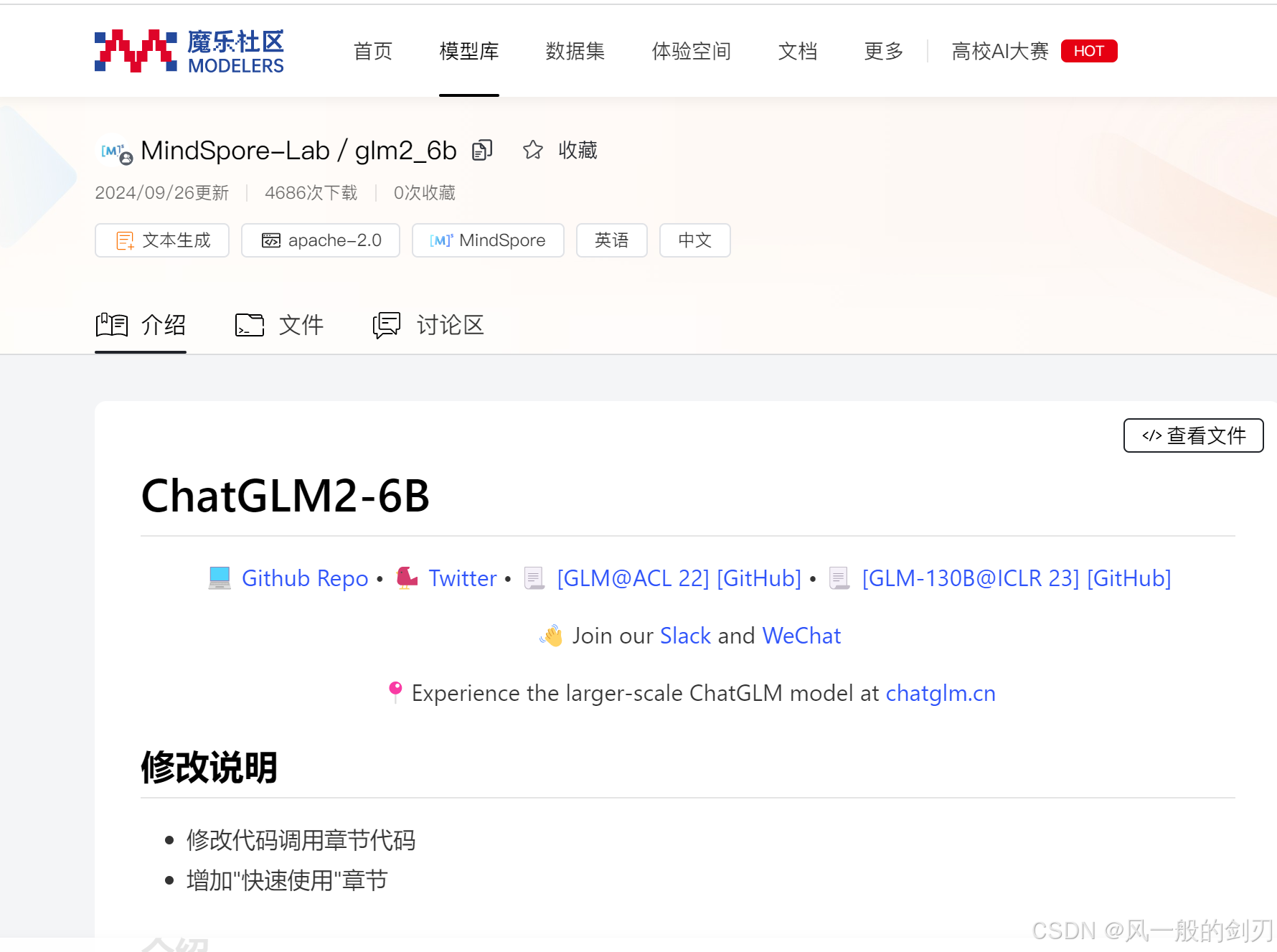
这是魔乐社区上的一个模型的文件,这种就是,它不只是权重参数,它是提供了整个模型参数,模型结构构造,并且在此之上,进一步进行了封装,使其能够适合于自己模型的一些特点。可以看到,在这种进一步封装的情况下,原始基础框架,基础封装,就像是他的封装所需要使用到的一个工具。但最终无论怎样,他的底层也是一些高级api的调用,就是说模式其实和上面讲的两种模式基本上没有差别。可以简单的理解总结为:他就是依靠于对底层api或者底层封装的修改,提供了独属于自己模型或者任务的脚本启动方式。
去看了这里的这个案例的介绍,会发现,他的案例里面是用的from openmind import AutoTokenizer, AutoModelForCausalLM,而不是mindformers的autoClass类(当然这个模型的底层api是mindformers提供的那些哈,随便点几个.py文件就能看到),这个下一篇文章会谈到怎么去看待这个问题
发散一下
其实,基于上面这个逻辑,我们能很好感受到,不仅mindformers,比如transformers也应该是这样的模式,也应该是类似这样的构造组成,至少是:需要加载权重,就需要有限的配置,框架内部自己也定义了很多模型的配置。框架本身的那些命令调用启动,底层都是高级api
另外,不要认为hugging face中的模型就一定可以用transformers库拉去调用哈,他们两个其实不能完全混为一谈,hugging face传入的模型可以是任意的,但是transformers库支持的模型是有限的,当然,一般为了自己的模型的简便,广泛使用,还是建议按照transformers支持的格式来构造模型
这里我稍微提一下,网上很多大模型教程,都是用脚本方式的,上面也说过用脚本方式的优势,另外,在这种背后工具原理都大差不差的情况下,用脚本比学一种新的高级api往往来得更快
总结
这篇文章,主要是讲了对mindformers(transformers)这样的套件或者框架的一个大致构造体系的认识,属于一种认知教程,更多的需要靠码友们自己去感受,很多细节方面没有深究,比如脚本启动那里的任务,当然后面文章会有介绍的(后头等小编学会了一定的脚本基础,会再带大家分析一下脚本启动的!),更多的是为了帮助码友们认识一下大模型工具的背后原理,由于小编技术有限加上刚开始写博客不久,对上面文章内容有问题的或者有疑惑的码友们,欢迎评论区留言哦!
mindformers官网文档:https://mindformers.readthedocs.io/zh-cn/latest/docs
mindspore文档中心:文档中心 | 昇思MindSpore社区官网

















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









