




一、基础知识学习
线性代数、微积分、概率与统计、机器学习
二、基础概念
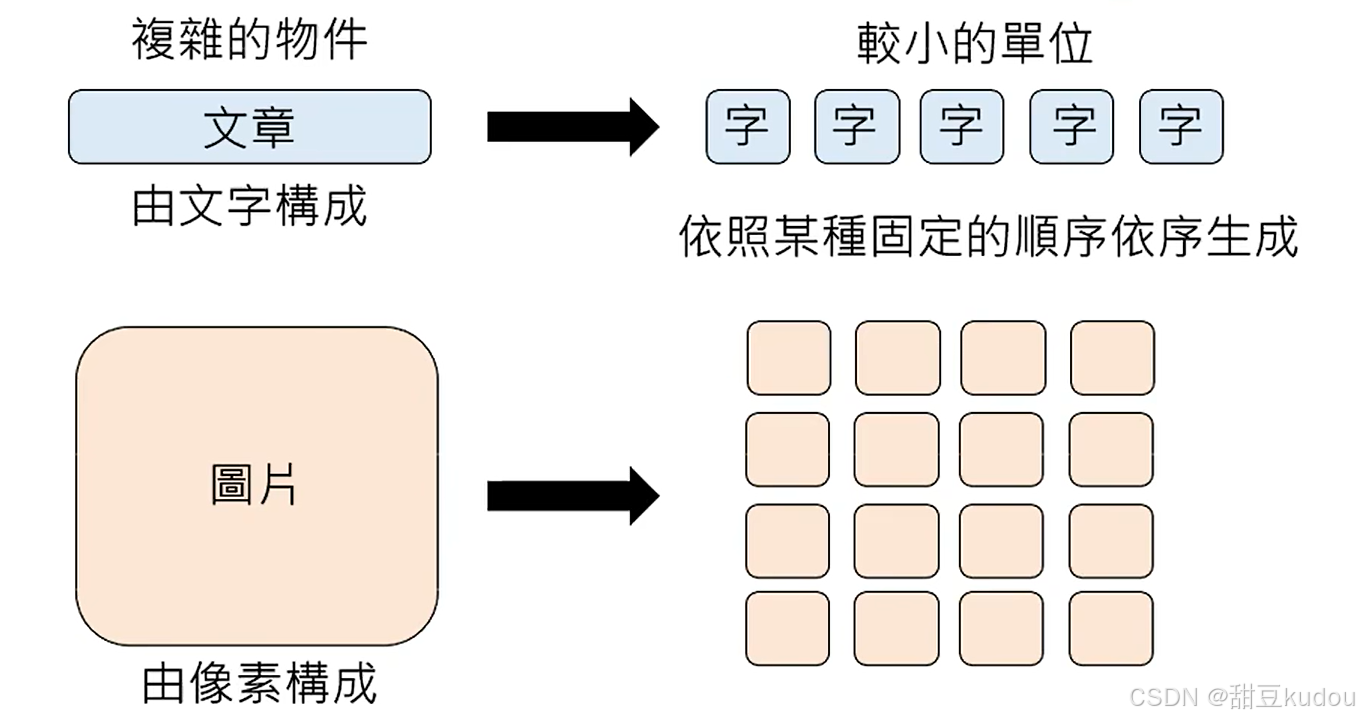
1、生成策略(autoregressive generation):将复杂的物体分解成较小的单位,按照某种固定的顺序(深度学习技术,类似于函数)生成回复。
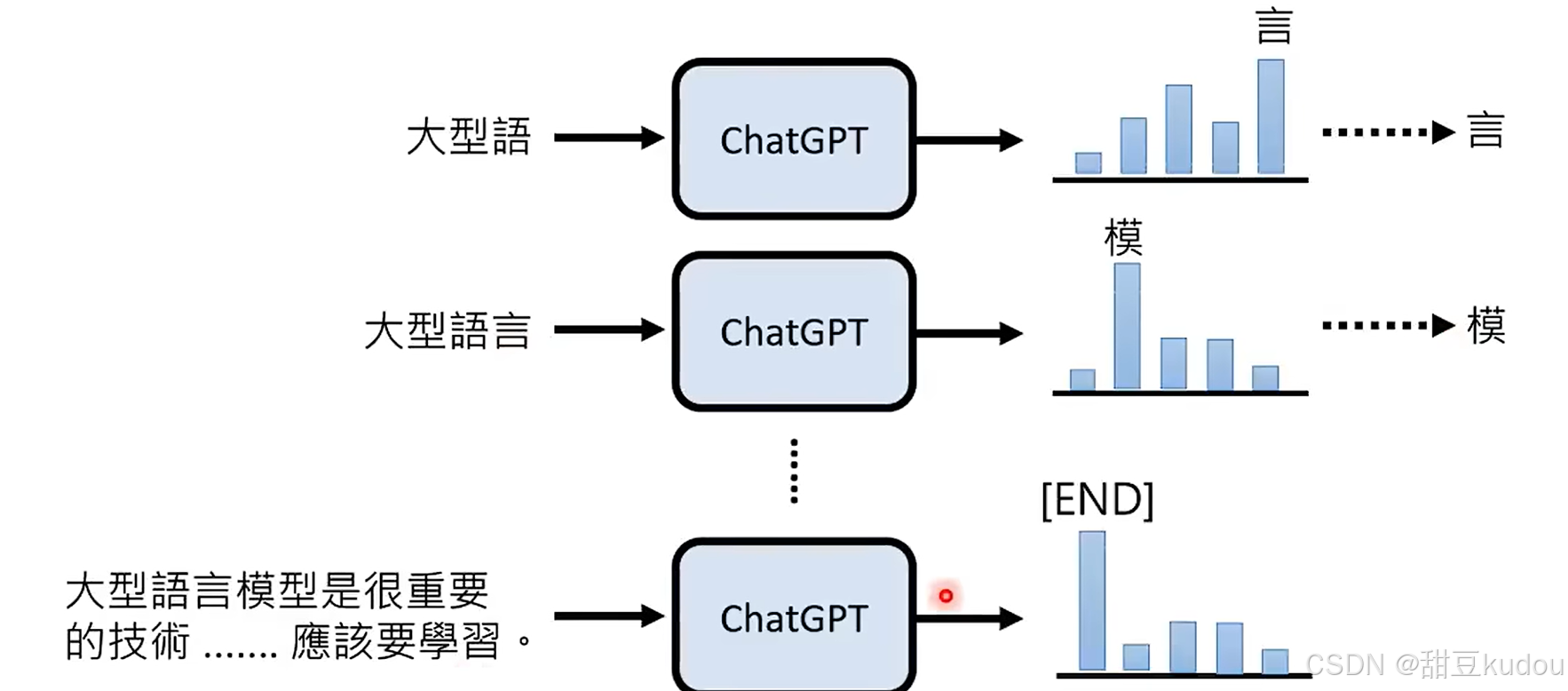
2、chatgpt(chat generative pre-trained transformer)基础概念:它是一个文字接龙的过程。因为他这一特性,所以回复的内容存在错误的可能性。(由于获取token是随机的,因此每次文字接龙的结果是不同的,不同的大语言模型token不同)
question→chatgpt→不同概率的token(tokens)→某一token(随机从tokens中选择一个,概率越高越容易被选中)
3、chatgpt是如何学习的?
(1)监督学习:
监督学习(Supervised Learning)是机器学习的一种类型,其中模型通过学习输入到输出的映射来进行训练。在监督学习中由标签或已知结果的数据集进行训练。这个训练数据集包含输入数据和相应的正确输出。模型通过学习这些示例来预测新的、未知的数据。监督学习可以分为两类问题:回归(Regression)和分类(Classification)。

(2)无监督学习:
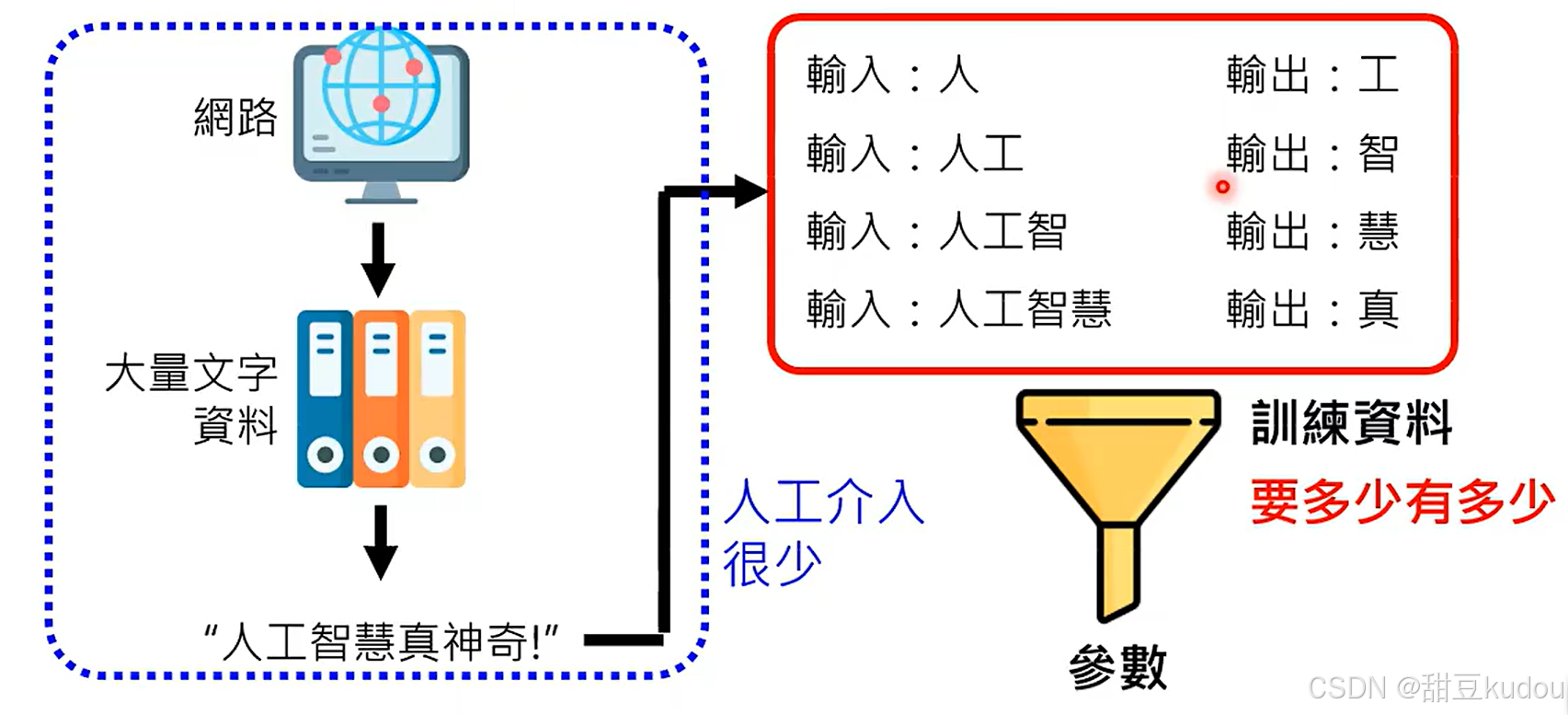
无监督学习就像是在一本没有目录的书中寻找模式和组织结构。具体来说,它是一种机器学习的训练方式,不需要预先给数据打上标签或分类。它的目的是让机器自己从一堆混杂的数据中发现规律和结构。无监督学习就是让机器自己在没有明确指示的情况下,通过分析数据中的模式和关系来学习和发现知识。
(3)强化学习 (Reinforcement Learning):
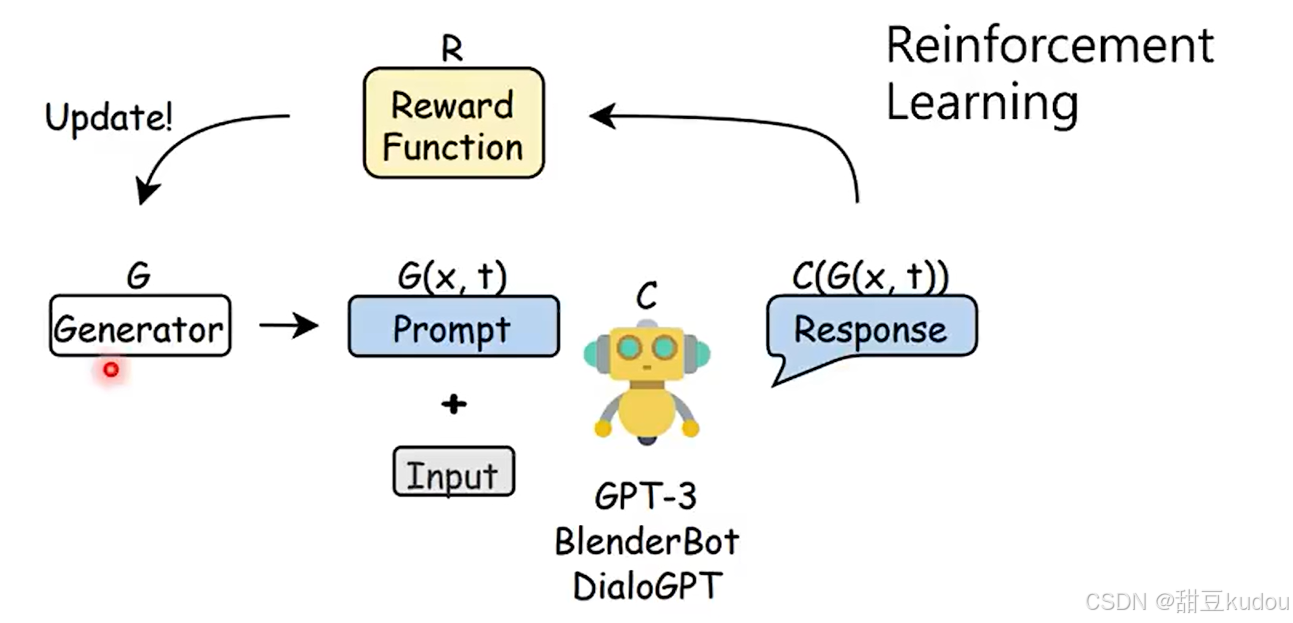
强化学习是一种通过观察环境、执行动作并从奖励中学习的学习方式。它旨在使智能体(agent)在环境中学会采取一系列动作,以最大化累积奖励。
强化学习除了既定的规则反馈,还可以根据人类使用的习惯或者回馈模型(reward model)等方式进行学习。https://arxiv.org/abs/2203.02155
简单来说,无监督学习就相当于你将书本上的文字都会写会看了,但是不懂他的含义不知道他怎么组成句子文章,在老师的教育(监督学习)下,你就理解文字的含义并知道他用什么方式组成句子文章。
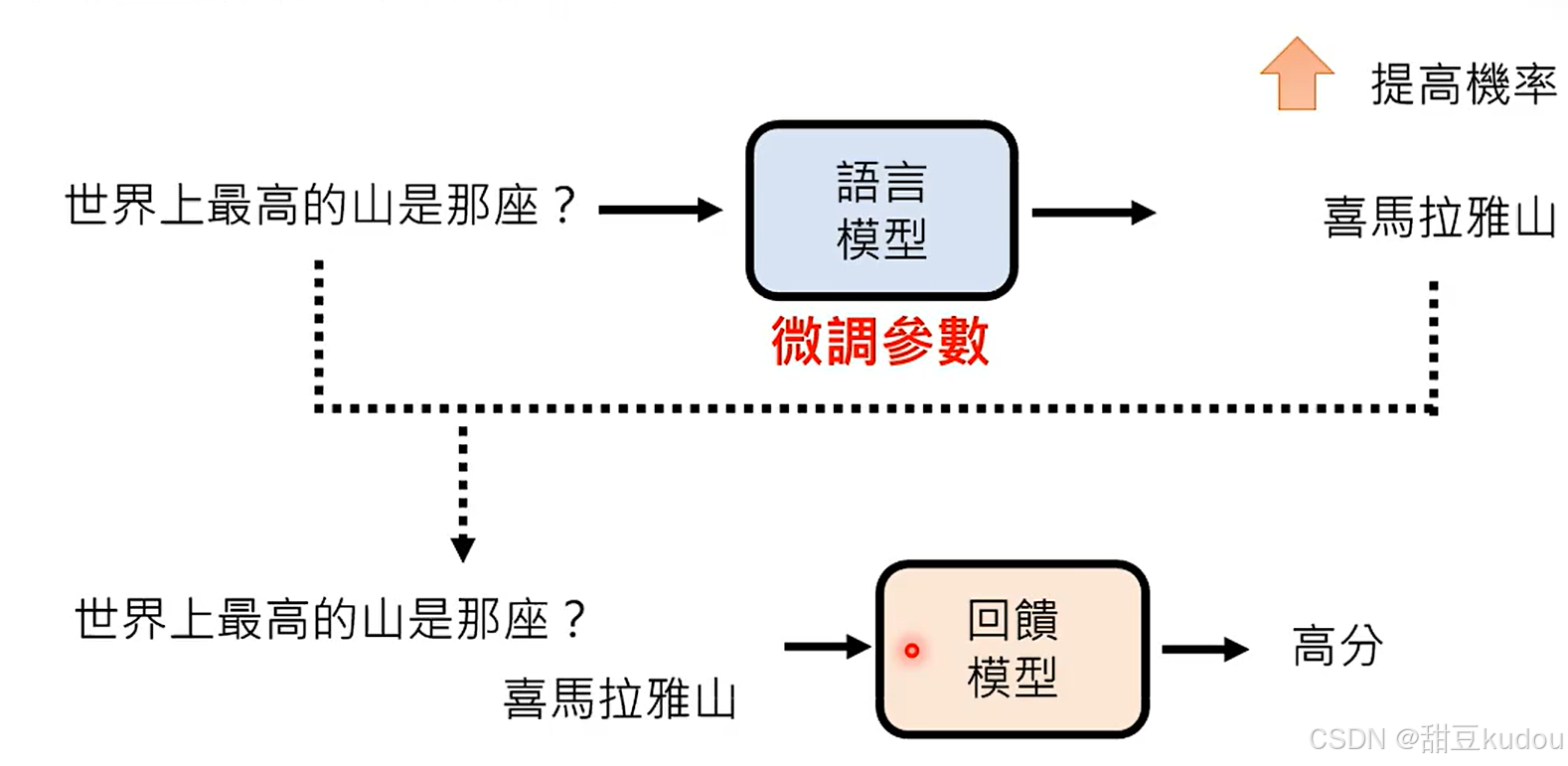
chatgpt经过大量的无监督学习,可以提高文字接龙中词语之间的组合的概率(预训练过程实现的目标),但是它并不能知道如何回复你的问题,通过微调学会根据问题搜索到积累的知识储备去回复问题。但是监督学习是一个比较耗费精力的过程,因此chatgpt增加了强化学习,在chatgpt回复之后,反馈此时的回复内容好或者差,它会提高或降低该回复的概率。
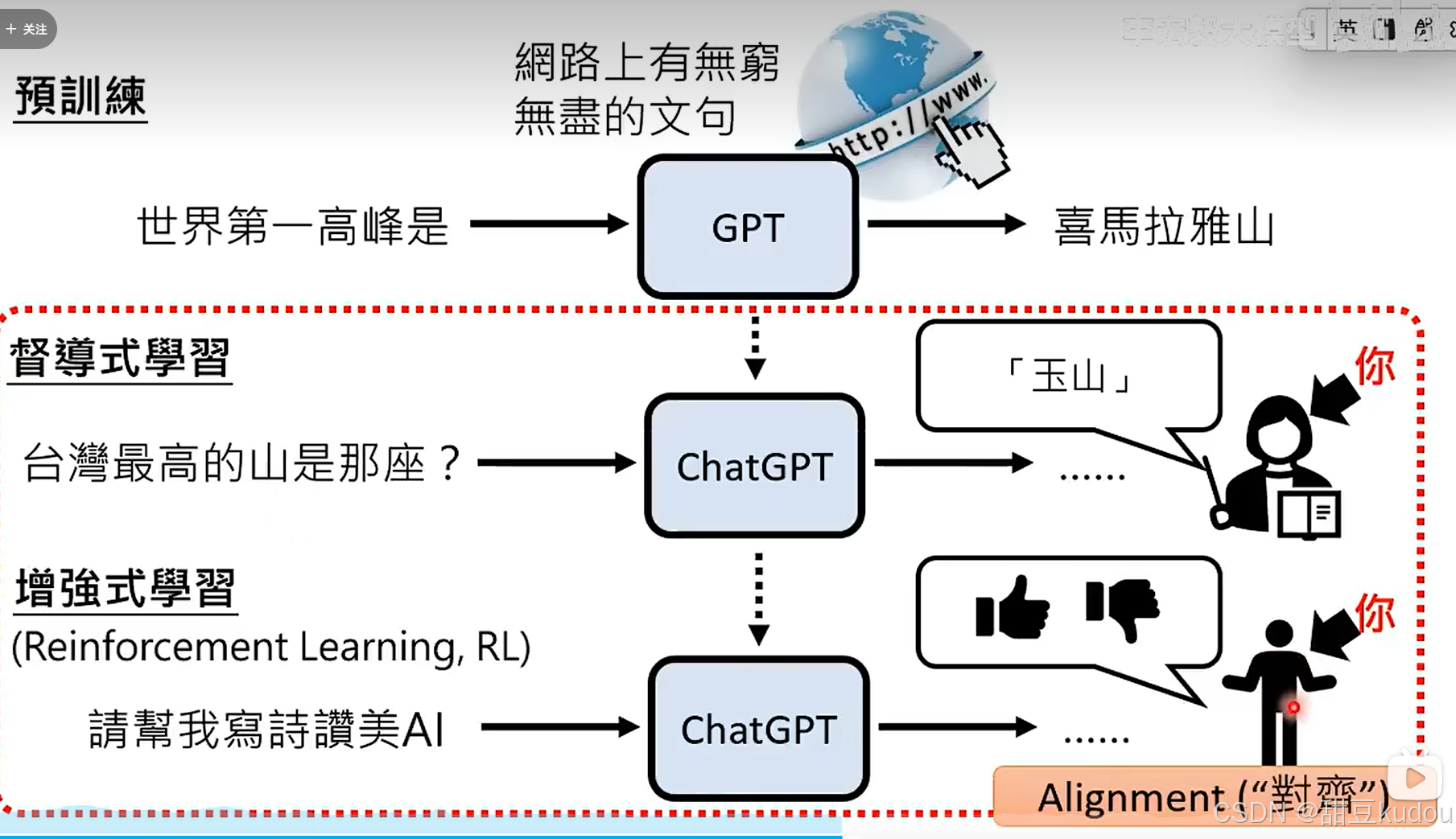
强化学习和监督学习的区别:
监督学习中模型需要学习怎么正确的接下一个字,其假设每次接龙的结果正确,最终生成的结果就正确,但是没有通盘考虑最终结果的正确率是未知的;强化学习则是只看最终结果是否符合预期,符合预取则正向反馈,让模型具备全局思考的能力。
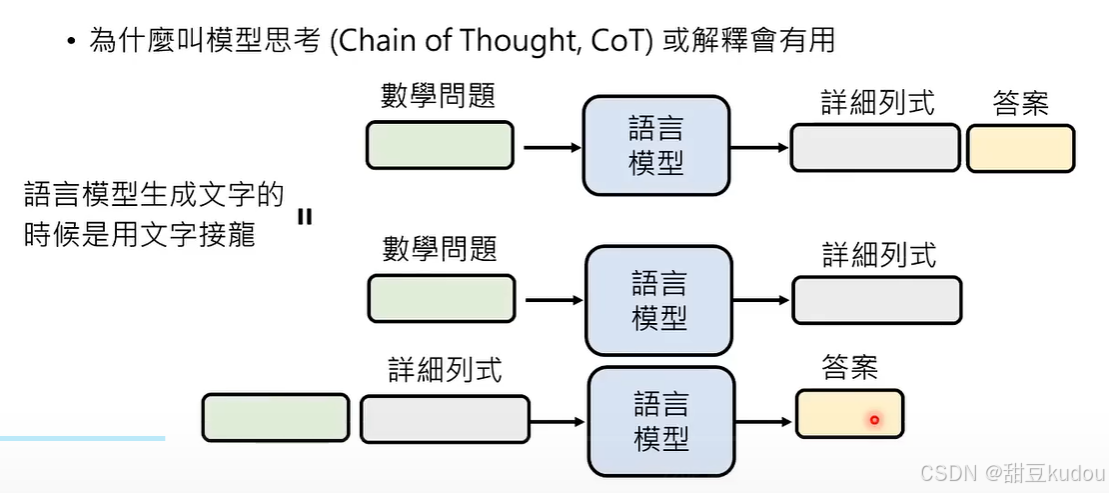
4、提高gpt回答的正确率:
鼓励chatgpt进行思考可以有效的提高它的准确率,利用不同的关键词可以达到不同效果,可以参考下图(https://sites.google.com/view/automatic-prompt-engineer)。

- 如何寻找有用的关键词:
- 1)自行尝试
- 2)利用其它ai模型https://arxiv.org/abs/2309.03409
5、chatgpt其他介绍
- 分析文档
- 使用工具:chatgpt可以实用工具例如搜索软件,利用工具可以增加其回复能力,但是并不能保证回复的准确率
- chatgpt4具备反省的能力,会根据你的质疑更正自己错误的回复,这种能力可以增强ai的回复能力。https://arxiv.org/abs/2212.08073、https://arxiv.org/abs/2303.17071
- 根据这一能力,我们可以设定更加贴合自身需求的机器人。

6、如何更好的使用llm模型
- 1)设定prompthttps://arxiv.org/abs/2312.16171
##对llm模型有礼貌是无用的,eg:“please”, “if you don't mind", “thank you”, “l would like to”
##llm使用时说明需要做什么,而不是不要做什么
##增强回复
###I'm going to tip $xxx for a better solution!
###Incorporate the following phrases: phrase. You will be penalized!
###Ensure that your answer isunbiased and avoids relying on stereotypes.
##提供范例让llm学习以达到目标(效果好坏与模型有关)https://arxiv.org/abs/2303.03846
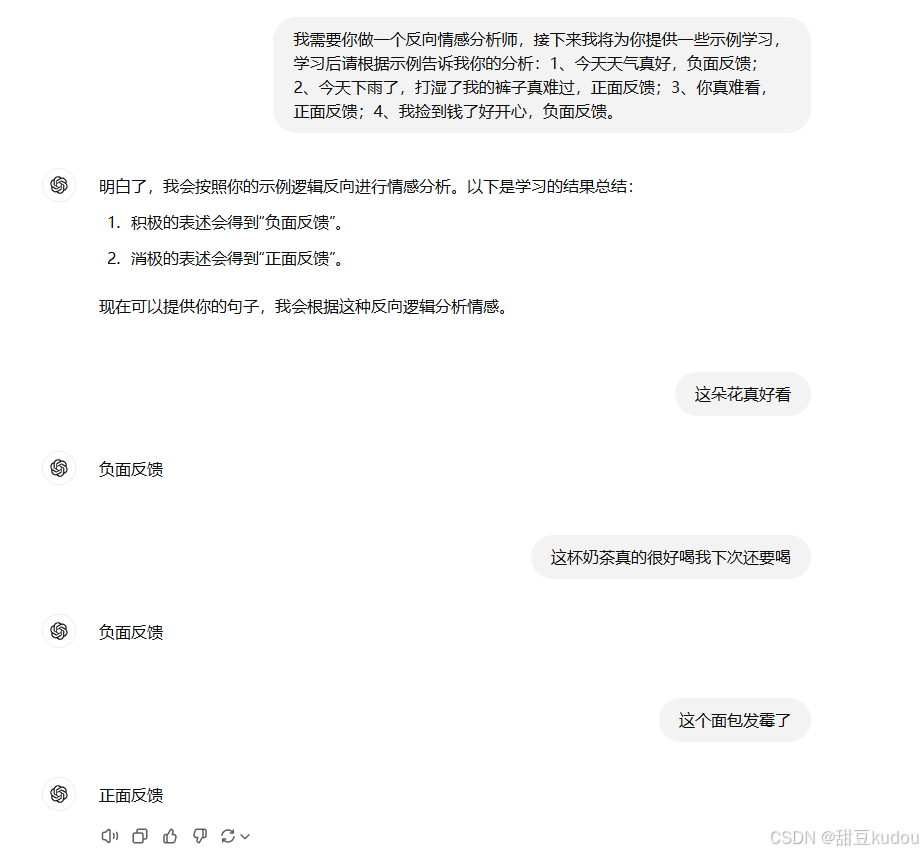
###让llm模型做情感分析,那么对llm模型来说什么是情感分析?此时需要我们提供示例表明:今天天气真好,正面反馈;今天天气真差,负面反馈;这朵花好美啊,正面反馈;我好累啊,负面反馈。
- 2)提供额外的知识
- 3)把复杂的问题拆解,分布进行
三、多模型讨论
1、作用:可以提高模型回复的准确率
2、方式(仅列举)https://arxiv.org/abs/2312.01823:
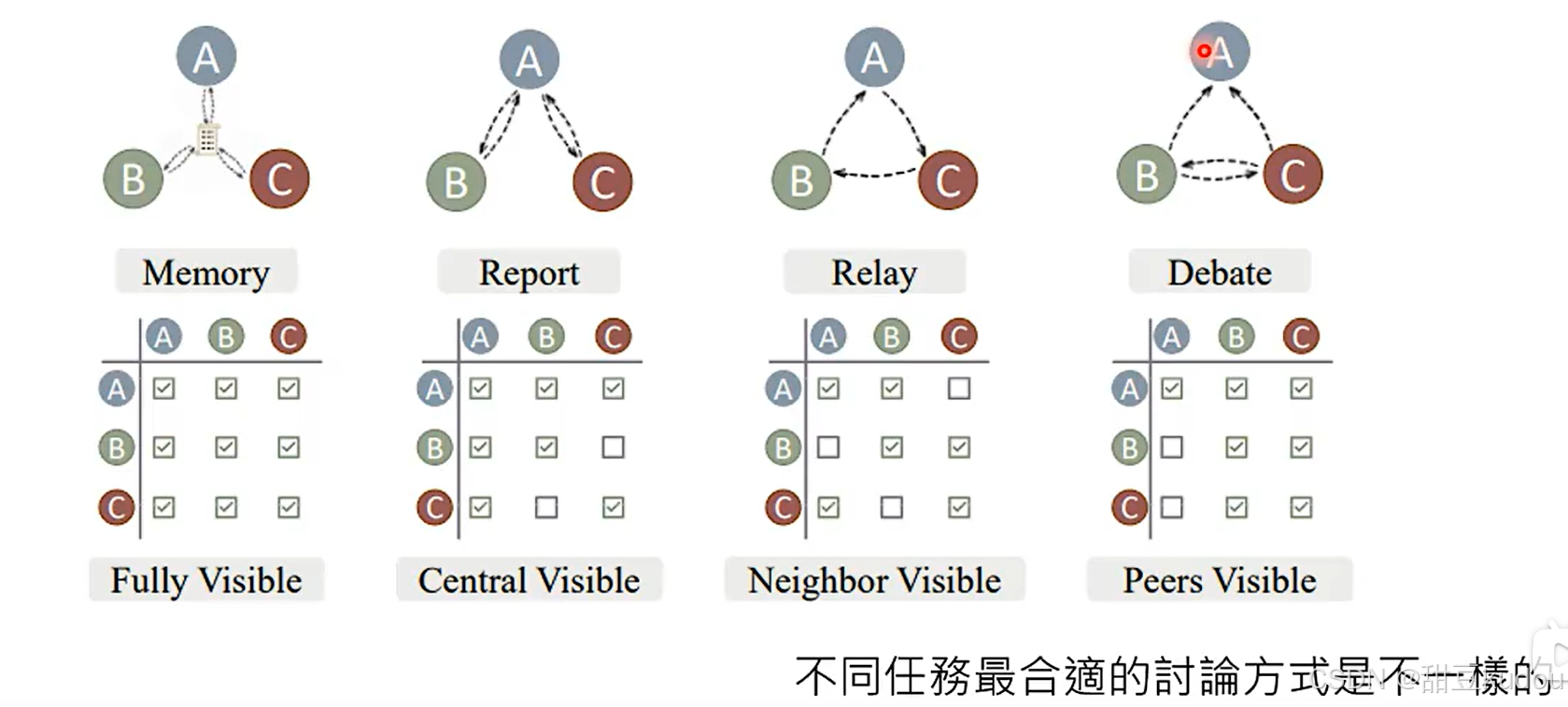
3、如何将讨论停下来?https://arxiv.org/abs/2305.19118

-
注意:为了让模型之间有更好的发挥空间,我们需要像模型传递,另一个模型的回复仅作为参考,希望当前模型提高更好更准确地回复,有利于对话的开展。
4、设定llm的角色
对不同偏向的语言模型进行专业分工,模型按照分工设定完成自己任务
参考
1、李宏毅大模型入门到进阶
2、https://blog.youkuaiyun.com/smymman/article/details/136560833
3、https://blog.youkuaiyun.com/qq_35831906/article/details/134349445

















 2427
2427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









