







 本文介绍了Python的进程管理,包括启动多进程、自定义进程和进程池的使用。详细讲解了非阻塞的apply_async和map_async方法,以及如何添加回调函数。还探讨了进程间的通信,如Queue和Manager,以及在批量文件下载和文本处理中的应用。
本文介绍了Python的进程管理,包括启动多进程、自定义进程和进程池的使用。详细讲解了非阻塞的apply_async和map_async方法,以及如何添加回调函数。还探讨了进程间的通信,如Queue和Manager,以及在批量文件下载和文本处理中的应用。
进程三种状态
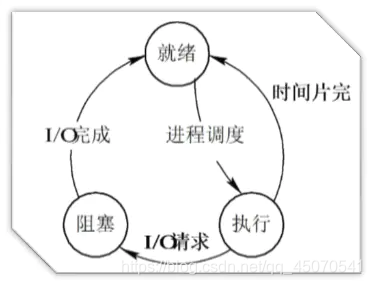
- 就绪:已获得运行所需资源,除了cpu资源。
- 阻塞:等待cpu以外的其他资源
- 执行→阻塞:执行的进程发生等待事件而无法执行变为阻塞状态。例如IO请求,申请资源得不到满足。
- 阻塞→就绪:处于阻塞状态在其等待的事件已经发生,并不马上转入执行状态,先转入就绪状态
- 执行→就绪:时间片用完而被暂停执行。
- 临界区:一次只允许一个进程进入访问的一段代码。临界区保护原则是有空让进,有限等待。
multiprocessing模块提供了一个process类来代表一个进程对象,这个模块表示像线程一样管理进程,这个是multiprocessing的核心,它与threading相似,对多核的CPU的利用率会比threading更好。
对于multiprocessing中的process类的构造方法如下:
_init_(self, group=None, target=None, name=None, args=(), kwargs={})
参数说明:
- group:进程所属组。(一般为缺省)
- target:表示调用对象。
- args:表示调用对象的位置参数元组。
- name:别名
- kwarges:表示调用对象的字典。
启动多进程
from multiprocessing import Process
from time import sleep
import os
def task1():
while True:
sleep(1)
print('这是任务1',os.getpid(),'---',os.getppid())
def task2():
while True:
sleep(1)
print('这是任务2',os.getpid(),'---',os.getppid())
if __name__ == '__main__':
p = Process(target=task1, name='任务1')
p.start()
print(p.name)
p1 = Process(target=task2, name='任务2')
p1.start()
print(p1.name)
print('***************************')
主进程控制字进程启停
from multiprocessing import Process
from time import sleep
import os
def task1(s):
while True:
sleep(s)
print('这是任务1', os.getpid(), '---', os.getppid())
def task2(s):
while True:
sleep(s)
print('这是任务2', os.getpid(), '---', os.getppid())
number = 1
if __name__ == '__main__':
p = Process(target=task1, name='任务1', args=(1,))
p.start()
print(p.name)
p1 = Process(target=task2, name='任务2', args=(2,))
p1.start()
print(p1.name)
print('***************************')
while True:
number += 1
sleep(0.2)
if number == 100:
p.terminate()
p1.terminate()
break
else:
print('-------number', number)
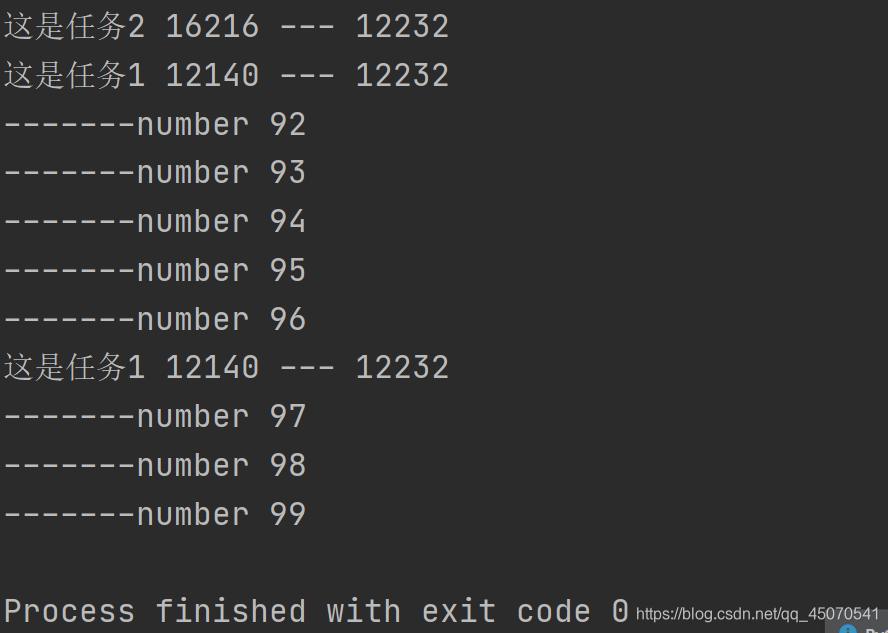
一般情况下不能共享全局变量
进程间的通信应该尽量避免共享数据的方式
进程间的数据是独立的,可以借助队列或管道实现通信,二者都是基于消息传递的。
from multiprocessing import Process
from time import sleep
import os
m = 1 # 共享全局变量
list1 = []
def task1(s):
global m
while True:
sleep(s)
m += 1
list1.append(str(m) + 'task1')
print('这是任务1', m, list1)
def task2(s):
global m
while True:
sleep(s)
m += 1
list1.append(str(m) + 'task2')
print('这是任务2', m, list1)
number = 1
if __name__ == '__main__':
p = Process(target=task1, name='任务1', args=(1,))
p.start()
print(p.name)
p1 = Process(target=task2, name='任务2', args=(2,))
p1.start()
print(p1.name)
while True:
sleep(1)
m += 1
print('------->main:', m)
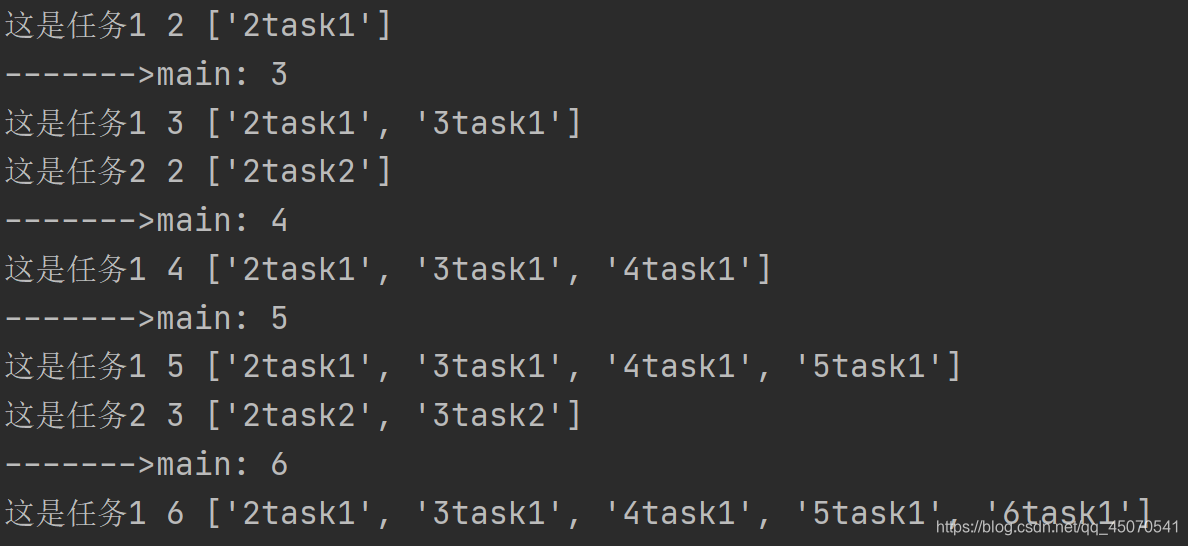
从上图中可以看出,进程1和进程2中全局变量的变化是不一致的,所以进程间的资源是相互独立的

自定义进程
from multiprocessing import Process
class MyProcess(Process):
def __init__(self, name):
super(MyProcess, self).__init__()
self.name = name
def run(self):
n = 1
while True:
print('{}------自定义进程,n={}'.format(n, self.name))
n += 1
if __name__ == '__main__':
p = MyProcess('小明')
p.start()
p1 = MyProcess('小强')
p1.start()
进程池
- 进程池使用来控制进程数目的,
- 我们需要几个就开几个进程。如果不用进程池实现并发的话,会开很多的进程
- 如果你开的进程特别多,那么你的机器就会很卡,所以我们把进程控制好,用几个就开几个,也不会太占用内存
multiprocessing.Pool常用函数解析:
- apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表;
- apply(func[, args[, kwds]]):使用阻塞方式调用func
- close():关闭Pool,使其不再接受新的任务;
- terminate():不管任务是否完成,立即终止;
- join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用
pool类可以提供指定数量的进程供用户调用,当有新的请求提交到pool中时:
- 如果pool还没有满,就会创建一个新的进程来执行请求。
- 如果pool满了,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
apply_async() apply_async(func[, args=()[, kwds={}[, callback=None]]])
与apply用法一致,但它是非阻塞的且支持结果返回后进行回调。map() map(func, iterable[, chunksize=None])
pool类中的map方法,与内置的map函数用法基本一致,会使进程阻塞直到结束返回。
ps:虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。map_async() map_async(func, iterable[, chunksize[, callback]])
同上,区别为它是非阻塞的。close() 关闭进程池,使其不再接受新的任务。
terminal() 结束工作进程,不再处理未处理的任务。
join() 主进程阻塞等待子进程的推出,join方法要在close或terminate之后使用。
非阻塞之apply_async
- 每调用一次apply_result方法,实际上就向_taskqueue中添加了一条任务,注意这里采用了非阻塞(异步)的调用方式,即apply_async方法中新建的任务只是被添加到任务队列中,还并未执行,不需要等待,直接返回创建的ApplyResult对象,注意在创建ApplyResult对象时,将它放入进程池的缓存_cache中。
- 务队列中有了新创建的任务,那么根据上节分析的处理流程,进程池的_task_handler线程,将任务从taskqueue中获取出来,放入_inqueue中,触发worker进程根据args和kwds调用func,运行结束后,将结果放入_outqueue,再由进程池中的_handle_results线程,将运行结果从_outqueue中取出,并找到_cache缓存中的ApplyResult对象,_set其运行结果,等待调用端获取。
apply_async方法既然是异步的,那么它如何知道任务结束,并获取结果呢?这里需要了解ApplyResult类中的两个主要方法
#以下只是其中一段代码
def get(self, timeout=None):
self.wait(timeout)
if not self._ready:
raise TimeoutError
if self._success:
return self._value
else:
raise self._value
def _set(self, i, obj):
self._success, self._value = obj
if self._callback and self._success:
self._callback(self._value)
self._cond.acquire()
try:
self._ready = True
self._cond.notify()
finally:
self._cond.release()
del self._cache[self._job]
- 从这两个方法名可以看出,get方法是提供给客户端获取worker进程运行结果的,而运行的结果是通过_handle_result线程调用_set方法,存放在ApplyResult对象中。
- _set方法将运行结果保存在ApplyResult._value中,唤醒阻塞在条件变量上的get方法。客户端通过调用get方法,返回运行结果。
from multiprocessing import Pool
import time
from random import random
import os
def task(task_name):
print('开始做任务', task_name)
start = time.time()
time.sleep(random() * 2)
end = time.time()
return1='完成任务{},用时{},进程id:{}'.format(task_name, (end - start), os.getpid())
print(return1)
if __name__ == '__main__':
pool = Pool(5) #1
tasks = ['听音乐', '打游戏', '看电影', '编代码', '做饭', '跑步']
for task1 in tasks:
pool.apply_async(task, args=(task1,)) #2
pool.close() # 添加结束任务
pool.join() # 防止主进程结束
print('over!!!')
- 设置进程池的容量是5,即当进程池中的进程数量达到5时,其他进程就处于阻塞态,只有池中的一个进程执行完成后,才会允许下一个进程加入到进程池中
- 传入任务函数名和该任务所需参数
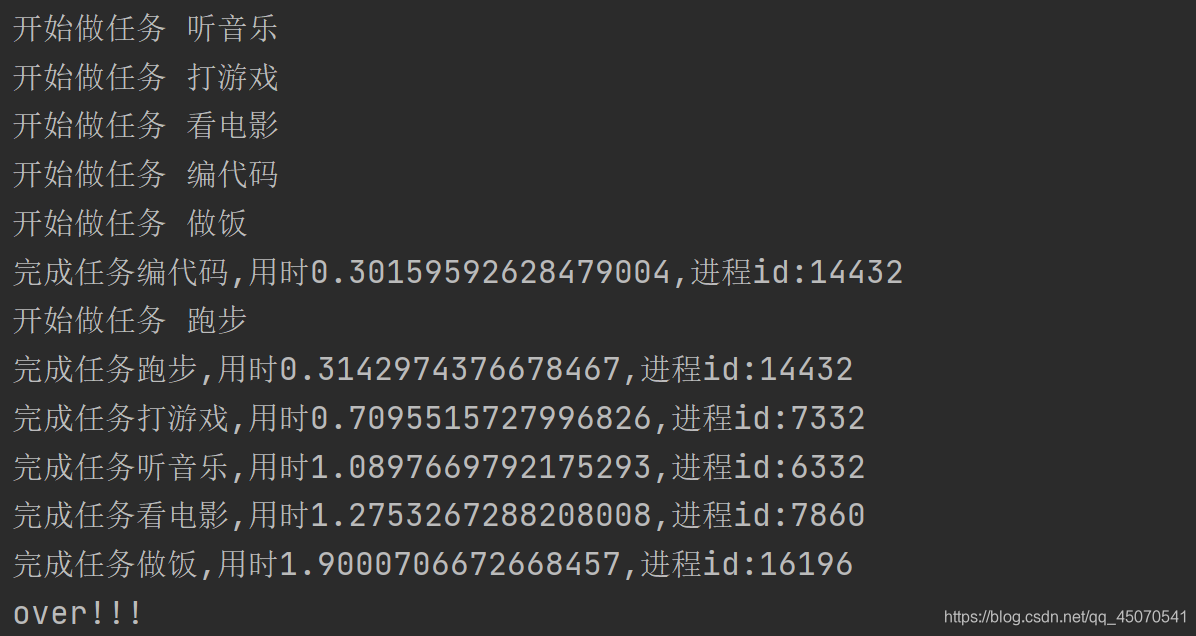
从上图可以看出,在编代码任务完成后才开始执行跑步任务
也可以将函数名翻入列表中,并循环执行,代码如下
import multiprocessing
import os, time, random
def Lee():
print "\nRun task Lee-%s" %(os.getpid()) #os.getpid()获取当前的进程的ID
start = time.time()
time.sleep(random.random() * 10) #random.random()随机生成0-1之间的小数
end = time.time()
print 'Task Lee, runs %0.2f seconds.' %(end - start)
def Marlon():
print "\nRun task Marlon-%s" %(os.getpid())
start = time.time()
time.sleep(random.random() * 40)
end=time.time()
print 'Task Marlon runs %0.2f seconds.' %(end - start)
def Allen():
print "\nRun task Allen-%s" %(os.getpid())
start = time.time()
time.sleep(random.random() * 30)
end = time.time()
print 'Task Allen runs %0.2f seconds.' %(end - start)
def Frank():
print "\nRun task Frank-%s" %(os.getpid())
start = time.time()
time.sleep(random.random() * 20)
end = time.time()
print 'Task Frank runs %0.2f seconds.' %(end - start)
if __name__=='__main__':
function_list= [Lee, Marlon, Allen, Frank]
print "parent process %s" %(os.getpid())
pool=multiprocessing.Pool(4)
for func in function_list:
pool.apply_async(func) #Pool执行函数,apply执行函数,当有一个进程执行完毕后,会添加一个新的进程到pool中
print 'Waiting for all subprocesses done...'
pool.close()
pool.join() #调用join之前,一定要先调用close() 函数,否则会出错, close()执行后不会有新的进程加入到pool,join函数等待素有子进程结束
print 'All subprocesses done.'
非阻塞之map_async
以上的apply/apply_async方法,每次只能向进程池分配一个任务,那如果想一次分配多个任务到进程池中,可以使用map/map_async方法
def map_async(self, func, iterable, chunksize=None, callback=None):
assert self._state == RUN
if not hasattr(iterable, '__len__'):
iterable = list(iterable)
if chunksize is None:
chunksize, extra = divmod(len(iterable), len(self._pool) * 4)
if extra:
chunksize += 1
if len(iterable) == 0:
chunksize = 0
task_batches = Pool._get_tasks(func, iterable, chunksize)
result = MapResult(self._cache, chunksize, len(iterable), callback)
self._taskqueue.put((((result._job, i, mapstar, (x,), {})
for i, x in enumerate(task_batches)), None))
return result
- func表示执行此任务的方法
- iterable表示任务参数序列
- chunksize表示将iterable序列按每组chunksize的大小进行分割,每个分割后的序列提交给进程池中的一个任务进行处理
- callback表示一个单参数的方法,当有结果返回时,callback方法会被调用,参数即为任务执行后的结果
- 从源码可以看出,map_async要比apply_async复杂,首先它会根据chunksize对任务参数序列进行分组,
- chunksize表示每组中的任务个数,当默认chunksize=None时,根据任务参数序列和进程池中进程数计算分组数:chunk, extra = divmod(len(iterable), len(self._pool) * 4)。
- 假设进程池中进程数为len(self._pool)=4,任务参数序列iterable=range(123),那么chunk=7, extra=11,向下执行,得出chunksize=8,表示将任务参数序列分为8组。
参考链接 python进程池剖析(二)
增加回调函数
-
需要回调函数的场景:进程池中任何一个任务一旦处理完了,就立即告知主进程:我好了额,你可以处理我的结果了。主进程则调用一个函数去处理该结果,该函数即回调函数
-
我们可以把耗时间(阻塞)的任务放到进程池中,然后指定回调函数(主进程负责执行),这样主进程在执行回调函数时就省去了I/O的过- 程,直接拿到的是任务的结果。
-
如果在主进程中等待进程池中所有任务都执行完毕后,再统一处理结果,则无需回调函数
from multiprocessing import Pool
import time
from random import random
import os
def task(task_name):
print('开始做任务', task_name)
start = time.time()
time.sleep(random() * 2)
end = time.time()
return1='完成任务{},用时{},进程id:{}'.format(task_name, (end - start), os.getpid())
return return1
任务函数返回的内容会被当做参数传给回调函数,即参数n
containter = []
def callback_func(n):
containter.append(n)
if __name__ == '__main__':
pool = Pool(5)
tasks = ['听音乐', '打游戏', '看电影', '编代码', '做饭', '跑步']
for task1 in tasks:
pool.apply_async(task, args=(task1,), callback=callback_func)
pool.close() # 添加结束任务
pool.join() # 防止主进程结束
for c in containter:
print(c)
print('over!!!')
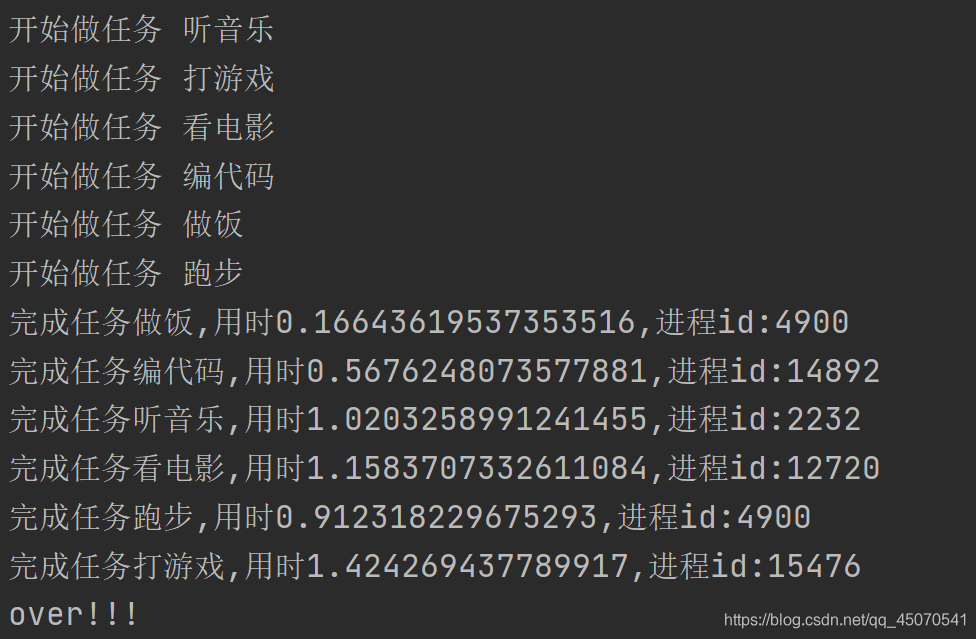
从上图可以看出,在所有进程执行完成后,一起输出任务函数返回的结果,这就是回调函数的作用
阻塞式
from multiprocessing import Pool
import time
from random import random
import os
def task(task_name):
print('开始做任务', task_name)
start = time.time()
time.sleep(random() * 2)
end = time.time()
return1='完成任务{},用时{},进程id:{}'.format(task_name, (end - start), os.getpid())
print(return1)
# return return1
containter = []
def callback_func(n):
containter.append(n)
if __name__ == '__main__':
pool = Pool(5)
tasks = ['听音乐', '打游戏', '看电影', '编代码', '做饭', '跑步']
for task1 in tasks:
pool.apply(task, args=(task1,))
pool.close() # 添加结束任务
pool.join() # 防止主进程结束
for c in containter:
print(c)
print('over!!!')
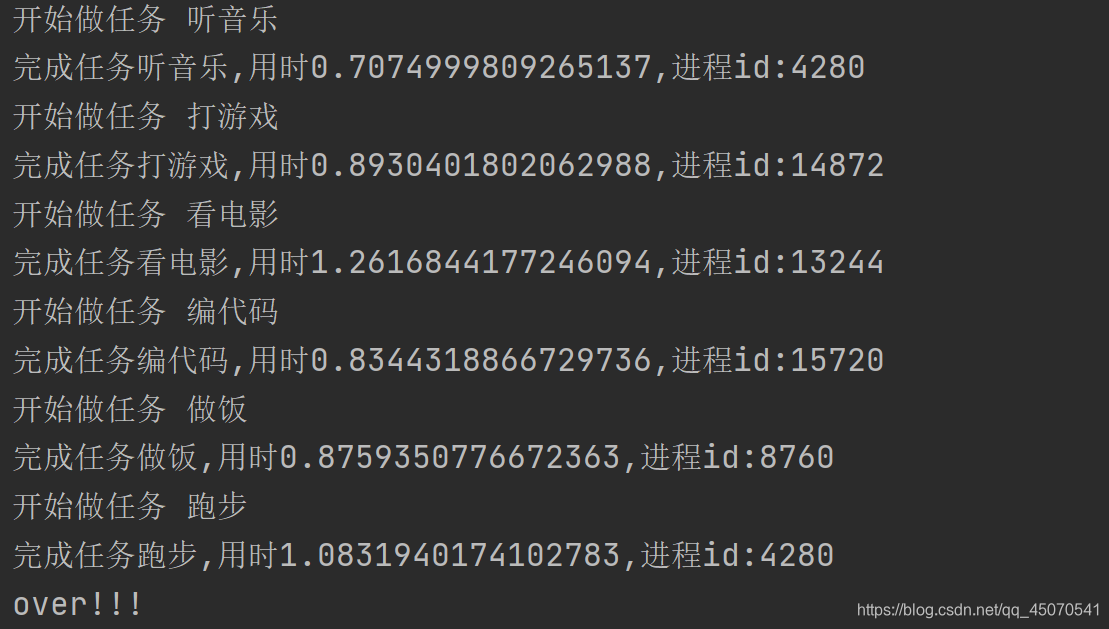
进程间通信
Queue
from multiprocessing import Queue
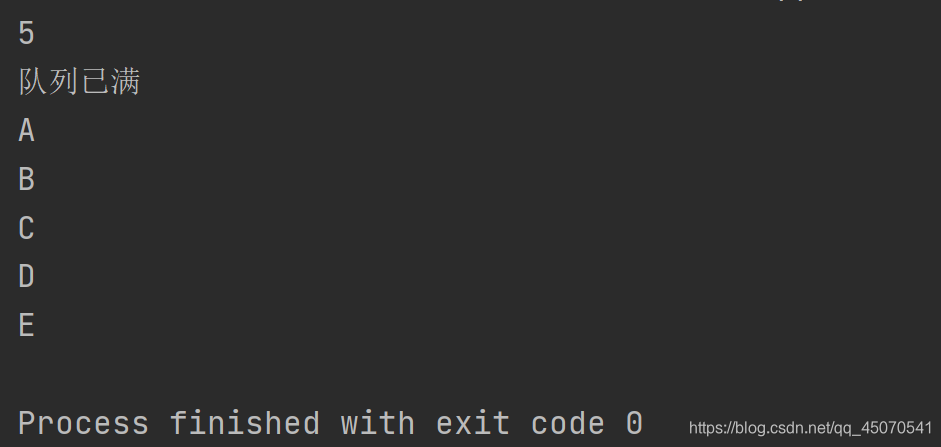
q=Queue(5)
q.put('A')
q.put('B')
q.put('C')
q.put('D')
q.put('E')
print(q.qsize())
if not q.full():
q.put('F',timeout=3)
else:
print('队列已满')
print(q.get(timeout=2))
print(q.get(timeout=2))
print(q.get(timeout=2))
print(q.get(timeout=2))
print(q.get(timeout=2))
from multiprocessing import Process
from multiprocessing import Queue
import time
def download(q):
images = ['girl.jpg', 'boy.jpg', 'man.jpg']
for image in images:
print('正在下载。。。。。', image)
time.sleep(0.5)
q.put(image)
def getfile(q):
while True:
try:
file = q.get(timeout=5) #如果不加超时,则就会一直阻塞在这里
print('{}保存成功'.format(file))
except:
print('全部保存完毕')
break
if __name__ == '__main__':
q = Queue(5)
p1 = Process(target=download, args=(q,))
p2 = Process(target=getfile, args=(q,))
p1.start()
p1.join()
p2.start()
p2.join()

Manager
from multiprocessing import Manager,Process,Lock
def work(dic,mutex):
with mutex:
dic['count'] -= 1
if __name__ == '__main__':
mutex = Lock()
m = Manager() #实现共享,由于字典是共享的字典,所以得加个锁
share_dic = m.dict({'count':100})
p_l = []
for i in range(100):
p = Process(target=work,args=(share_dic,mutex))
p_l.append(p) #先添加进去
p.start()
for i in p_l:
i.join()
print(share_dic)
共享就意味着会有竞争
实战
批量文件下载
#!/usr/local/python27/bin/python2.7
from multiprocessing import Process,Pool
import os,time,random,sys
import urllib
# 文件下载函数
def filedown(url,file):
urllib.urlretrieve(url,file)
if __name__ == '__main__':
p = Pool(100)
count = 0
# 打开存有url的文件
f = open('11.csv','r')
while True:
count += 1
# 按行读取
url1 = f.readline()
# 当文件读取完毕时,跳出循环
if url1 == '':
break;
url = url1.strip()
file = ('/root/tuchao/d2/work/strfile/'+url.split('/')[4])
print(count)
# 使用异步多进程的方式,启动子进程,并将功能函数和参数传入.
# 注意: 这里的 args 必须传参数列表,就算是一个参数,也得写逗号结尾。
p.apply_async(filedown, args=(url,file,))
p.close()
p.join()
批量文本处理
import re
import sys
import os
import pymongo
from multiprocessing import Process,Pool
import time
# Mongodb 连接,验证身份
conn = pymongo.MongoClient('localhost',27017)
conn.words.authenticate('words_user','woiu32k32x01')
db = conn.words
# 单词处理函数
def wordsevent(filename,mongo_insert):
with open(filename) as f:
wordsall=[]
for line in f:
# 把当前行转为小写后,判断里面是否包含小写字母。 有,表示这行是英文行,则做单词提取。 没有,表示当前行是数字或者是中文,不做处理,continue 进入下一次循环。
if line.lower().islower():
# 单词提取 re.findall 多重匹配。(r'(\w|\')+)' 表示匹配字母或者单引号出现一次或多次。这样会出现一个问题,提取出来的单词都会拆分成一个一个字母,因为正则会安装括号里面的规则去提取,\w 按字母匹配的,所以会提取字母。
# 所以才要这样写 (r'((?:\w|\')+)' 这里 ?: 写在括号的里面,表示此括号的规则只做匹配,而不提取内容。 外面还有一层括号,所以正则将会提取外面这层括号匹配的内容。 那就是一个个的单词了。
# 在正则中一对括号表示一组。
wordslist = re.findall(r'((?:\w|\')+)',line)
# 列表合并,把多个list合并到一个。
wordsall.extend(wordslist)
else:
continue
# 把list转成集合去重,因为集合中的元素是 确定性、无序性、互异性
s1=set(wordsall)
if len(s1) == 0:
pass
else:
mongo_insert(s1)
def mongo_insert(x):
db.test2.insert_many([{"word":i} for i in x])
if __name__ == '__main__':
fileall=os.listdir('strfile')
p = Pool(10)
count = 0
for i in fileall:
count += 1
filename = ('/root/tuchao/d2/work/strfile/%s' % i)
print(count,filename)
# 启动异步多进程
p.apply_async(wordsevent,args=(filename,mongo_insert,))
p.close()
p.join()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









