







论文地址:Knowledge Guided Attention and Graph Convolutional Networks for Chemical-Disease Relation Extraction
代码地址:https://github.com/sunyi123/cdr
1. Introduction
医学文献中化学物质与疾病之间的关系(CDR)为专家提供了关键信息,结合现有信息从文档中自动提取CDR,可以将非结构文本高效、高质量地转换为元组结构化文本,用于临床诊断、医学知识映射和许多其他医学研究。
目前CDR提取方法主要分为 基于特征的方法 和 基于神经网络的方法。
基于特征的方法 是从关系语句实例的上下文中提取包括词汇信息和句法信息的有用信息来构造特征向量,并通过计算特征向量的相似度来训练关系提取模型。但性能不稳定且手动提取特征很麻烦。

基于神经网络的方法 可以自动提取特征并实现端到端的学习,并且省去了人工特征提取的工作。常见的两种模式是 CNN 和 LSTM。
KGAGN:一种新的端到端的CDR提取模型,结合了知识嵌入、语义信息和句法依赖信息。
- 为了充分利用领域知识,我们将化学和疾病的实体表示以及从知识库中提取的它们的关系表示引入到模型中。我们训练实体嵌入作为输入序列的特征表示,关系嵌入通过注意机制进一步捕获加权上下文信息。
- 为了在跨句子CDR提取中充分利用句法依赖信息,我们构造了文档级句法依赖图,并使用GCN对其进行编码。
- 将包含先验知识信息的关系加权特征和长期依赖特征相结合,提取CID关系。
主要贡献:
- 将领域知识库中的实体表示和关系表示引入到CDR抽取中,并证明了其在生物医学领域关系抽取中的强大性能。
- 提出了一种新的端到端的模型(KGAGN),有效地结合了知识和多文本特征表示。
2. Methods
所使用的 CDR 原始语料库是几个包含多个句子的医学文档,并且已经标记了化学品和疾病实体。模型输入是预处理后的实例,输出是 CID 关系标识。
本文所使用的 CDR 提取的方法有四个步骤:
(1)从 CDR 训练集、验证集和测试集构造句子内和句子间的实例;
(2)利用 TransE 模型学习 CTD 知识库中的关系和实体表示;
(3)解析文档,构建文档级依赖结构树;
(4)建立具有知识表示的知识引导注意力和图卷积网络模型;
(5)还提出了一种改进模型,称为 B-KGAGN。
2.1 Relation Instance Construction
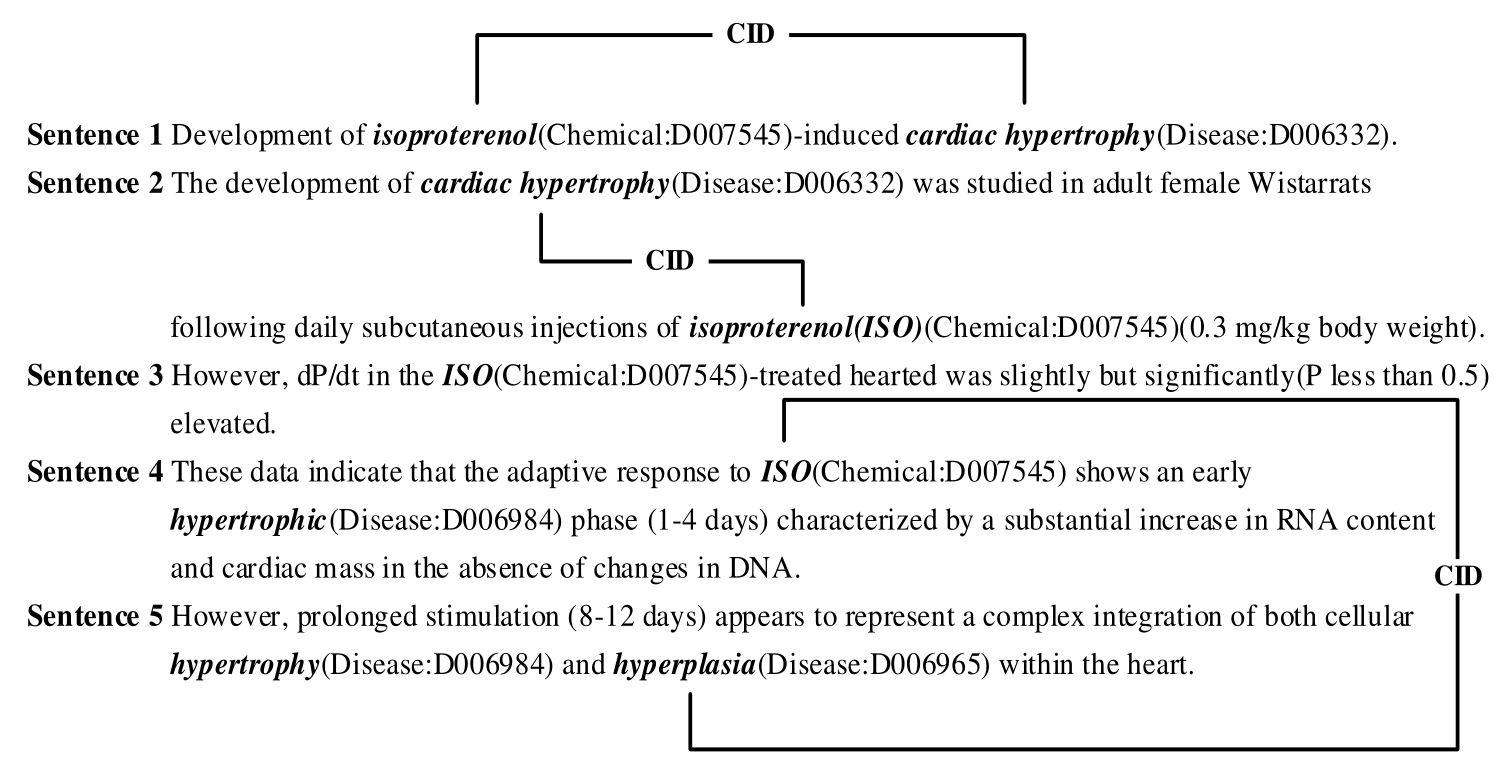
从测试集、验证集和测试集,我们构建了化学疾病关系的所有实例。所有实体对都被分为句内层次和句间层次。前者是指同一个句子中两个实体的关系,后者是指不同句子中两个实体的关系。
这里我们使用启发式规则构造句内和句间实例:
(1)在同一句中提到的每对化学疾病被构造为句内实例。
(2)在同一份文件中,只有不充当任何句内层次的化学疾病对才被构造为句间层次的实例。
(3)若多次提及同一实体,则最近提及的化学品和疾病被构造为实例。
关于其他预处理过程,对于每个实例,我们使用 StandfordCoreNLP 工具标记每个单词的 POS 标记,标记每个单词的绝对位置。
2.2 Knowledge representation learning
(1)三元组提取
从 CTD 知识库和 CDR 数据集提取了化学品-疾病关系三元组
(
e
c
,
r
,
e
d
)
(e_c, r, e_d)
(ec,r,ed)。CTD 涉及三种关系类型:关联推理、治疗和标记,其中只有最后一种类型代表 CID 关联。我们将从 CDR 中提取的实体对与 CTD 进行比较,若它们没有出现在CTD中,我们将添加此实体对的三元组,并将关系标记为空。
(2)使用 TransE 训练知识嵌入
TransE 是一种经典的知识表示学习模型,其基本思想是使头实体向量
h
h
h 和关系实体向量
r
r
r 的和尽可能接近尾实体向量
t
t
t。因此,其得分函数为:
f
r
(
h
,
t
)
=
∣
∣
h
+
r
−
t
∣
∣
L
1
/
L
2
f_r(h, t)= ||h + r - t||_{L_1/L_2}
fr(h,t)=∣∣h+r−t∣∣L1/L2损失函数为:

我们通过随机替换正确三元组的实体或关系来实现负采样,使用 TransE 训练和归一化来获得所有实体的 1024 维向量
e
e
e 和 4 种关系的 1000 维向量
r
r
r。
2.3 Dependency Tree construction
句法分析是 NLP 中的一项关键技术,有助于分析句子的组成结构和单词之间的依赖关系。依赖树是一种句法分析方法,主要表达句子中单词之间的相互依赖关系。这种依赖关系在实体之间的关系抽取起着重要作用。
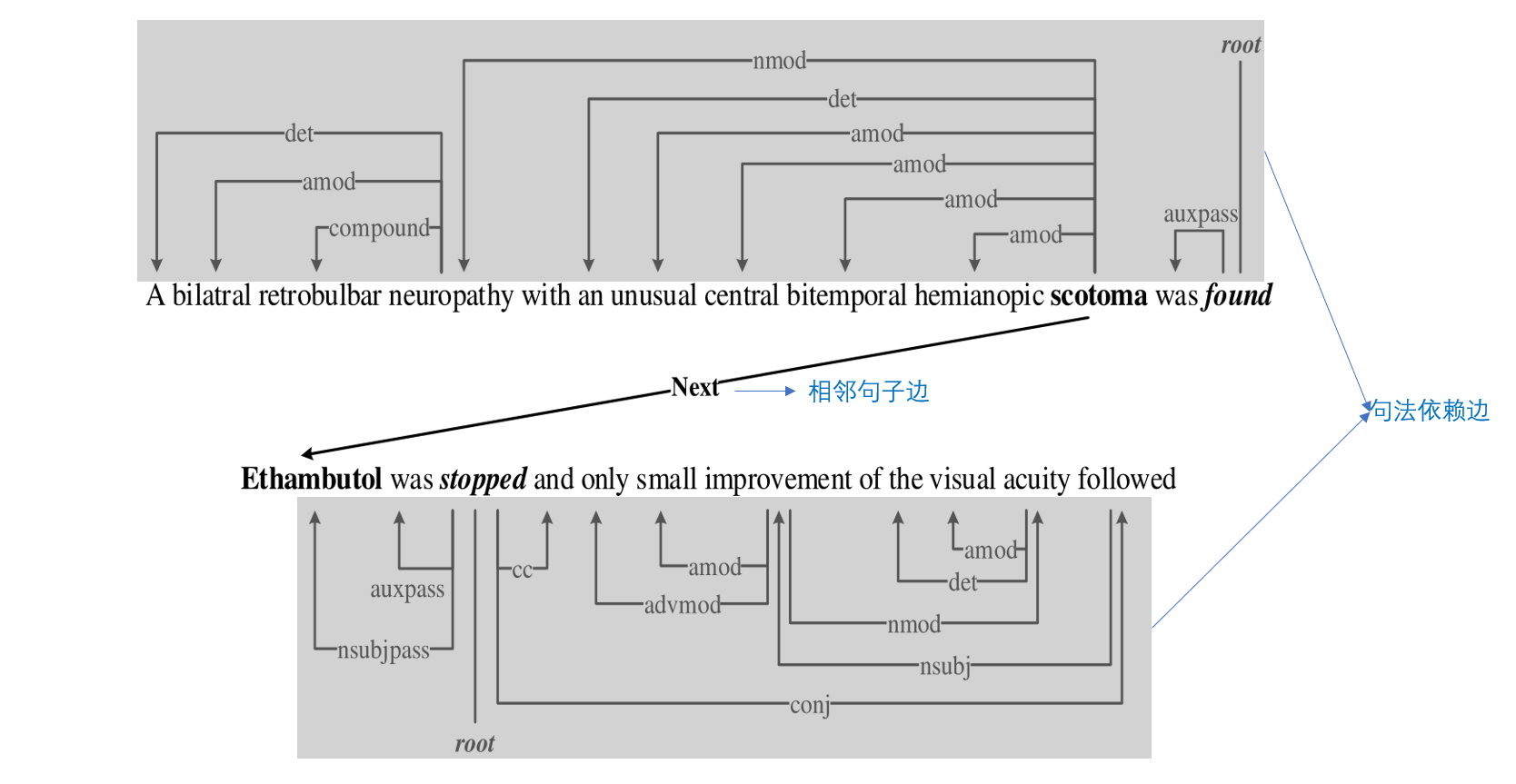
本文中,我们构造的文档级依赖树使用了三种类型的边:
(1)句法依赖边:使用 Standford 语法分析器获得的句法依赖信息来设置连接句子内部的有向边。
(2)相邻句子边:将单词连接为相邻句子的依存根。允许模型学习句间的依赖信息。
(3)自节点边:在每个节点上添加自节点边,允许模型从节点本身学习信息。
2.4 Chemical-disease relation extraction
KGAGN 模型由五个部分组成:Input Respresentation Layer、Bi-LSTM Layer、GCN Layer、Multi-head Attention Layer 和 Output Layer。
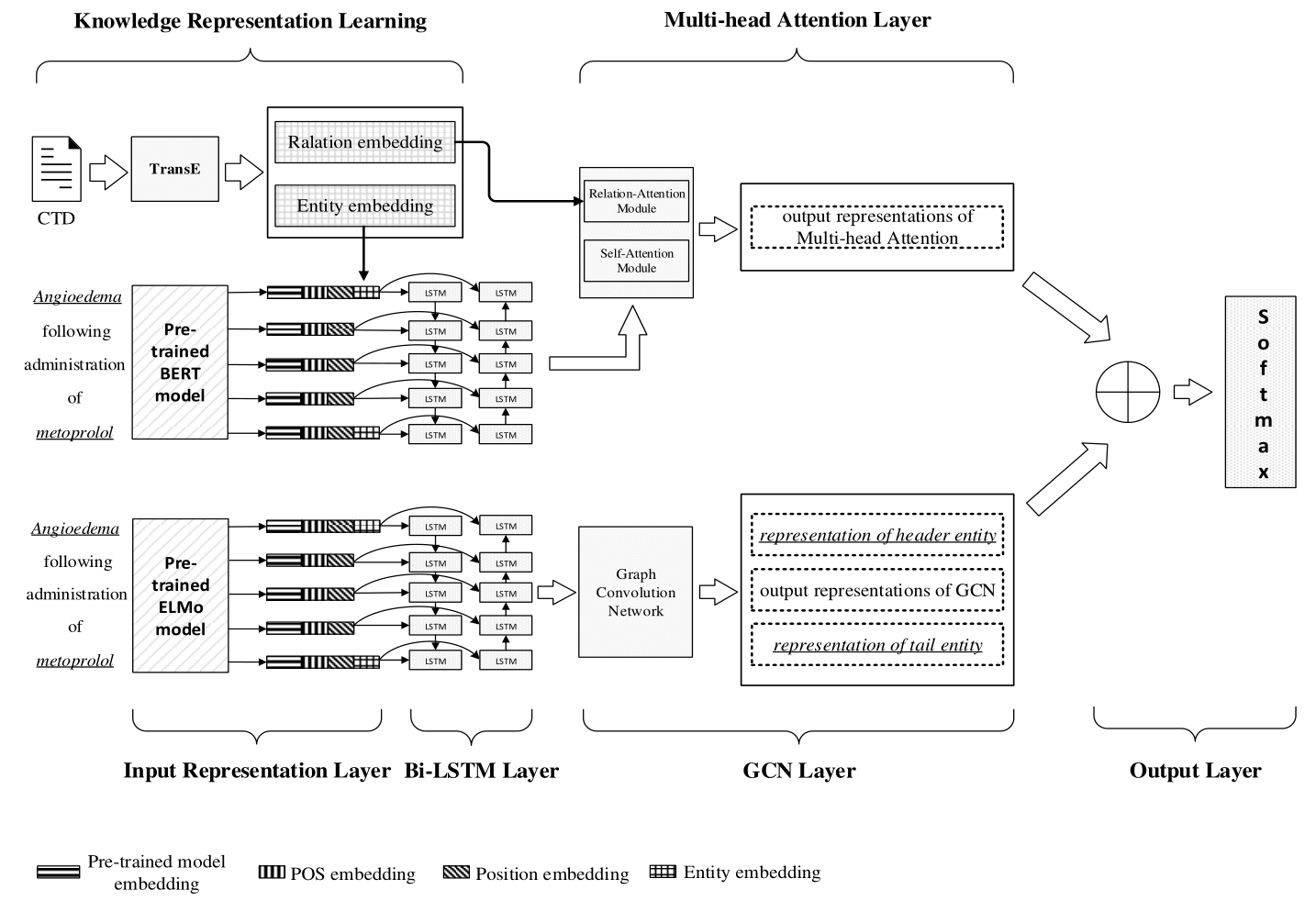
1. Input representation Layer
我们引入 BERT 预训练语言模型作为输入文本在输入表示层的嵌入。这里使用的是由 CDR 语料库微调的 BERT 模型。然而,由于依赖关系树由单词节点组成,而 BERT 的 token 将拆分单词,它不能与依赖树和GCN有效结合,因此选择 ELMo 语言模型作为 GCN 的输入嵌入。此外,我们还提取了其他语义信息的特征。词性标注 可以表示文本中单词的词性信息。位置嵌入 表示实体在文档中的位置信息,可以使模型定位实体对的语义信息,更好地学习实体上下文。然后我们构建一个包含所有实体的字典,以获取从 CTD 知识库中训练的实体向量
e
e
e,然后将实体向量连接到输入嵌入中作为另一个维度的特征。最后,我们的模型的输入表示层被分为两部分:
① 多头自注意力层的词嵌入由 BERT embedding
w
b
e
r
t
w_{bert}
wbert、POS embedding
w
p
w_p
wp、position embedding
w
d
w_d
wd 和 entity embedding
e
e
e 组成。
w
1
=
[
w
b
e
r
t
;
w
p
;
w
d
;
e
]
w_1 = \big[w_{bert};w_p;w_d;e\big]
w1=[wbert;wp;wd;e]② GCN层的词嵌入由 ELMo embedding
w
e
l
m
o
w_{elmo}
welmo、POS embedding
w
p
w_p
wp、position embedding
w
d
w_d
wd 和 entity embedding
e
e
e 组成。
w
2
=
[
w
e
l
m
o
;
w
p
;
w
d
;
e
]
w_2 = \big[w_{elmo};w_p;w_d;e\big]
w2=[welmo;wp;wd;e]
2. Bi-LSTM Layer
LSTM 具有长期和短期记忆能力,因此适合于长文本的语义特征提取。Bi-LSTM 还可以从后向前编码信息,因此它可以更好地捕获双向语义依赖。本文使用 Bi-LSTM 对两种不同的输入表示进行正向和反向编码,我们指定前向 LSTM 的隐藏状态为
h
t
f
h_t^f
htf,反向 LSTM 的隐藏状态为
h
t
b
h_t^b
htb,最后的隐藏状态为
h
t
=
[
h
t
f
;
h
t
b
]
h_t=[h_t^f;h_t^b]
ht=[htf;htb]。
3. GCN Layer
GCN 是卷积神经网络在图域中的自然扩展,它可以学习节点特征信息和图结构信息,是目前处理图形数据的最佳选择。对于给定的一个
n
n
n 个节点的图,可以将其表示为
n
×
n
n\times n
n×n 的邻接矩阵。我们将构造的文档级依赖图(无向图)转换为一个邻接矩阵
A
\text{A}
A,其中
A
i
,
j
=
1
\text{A}_{i, j}=1
Ai,j=1 表示单词
i
i
i 和单词
j
j
j 有一个依赖边,并加入自节点边,即
A
i
,
i
=
1
\text{A}_{i, i}=1
Ai,i=1。此外,还对图卷积中的数值进行了归一化处理,以解决依赖关系图中节点程度变化较大的问题。第
l
l
l 层第
i
i
i 个节点的图卷积运算定义如下:
h
i
(
l
)
=
ρ
(
∑
n
j
=
1
A
i
j
W
(
l
)
h
j
(
l
−
1
)
/
d
i
+
b
(
l
)
)
h_i^{(l)}=\rho\big(\sum_n^{j=1}\text{A}_{ij}W^{(l)}h_j^{(l-1)}/d_i + b^{(l)}\big)
hi(l)=ρ(n∑j=1AijW(l)hj(l−1)/di+b(l)) 其中
d
i
=
∑
j
=
1
n
A
i
j
d_i = \sum_{j=1}^n\text{A}_{ij}
di=∑j=1nAij(归一化操作),
ρ
\rho
ρ 是激活函数。
GCN 模型将 Bi-LSTM 的输出视为输入表征
h
1
(
0
)
,
h
2
(
0
)
,
…
,
h
n
(
0
)
h_1^{(0)}, h_2^{(0)}, \dots, h_n^{(0)}
h1(0),h2(0),…,hn(0),那么 GCN 第
L
L
L 层的输出为
h
1
(
L
)
,
h
2
(
L
)
,
…
,
h
n
(
L
)
h_1^{(L)}, h_2^{(L)}, \dots, h_n^{(L)}
h1(L),h2(L),…,hn(L)(蕴含了文本信息和句法信息)。
最后,由于头实体和尾实体的信息对关系抽取十分重要,所以当对 GCN 的输出做最大池化操作时也提取了两个实体的特征。其中化学品实体被表示为
h
c
h_c
hc,疾病实体被表示为
h
d
h_d
hd,那么 GCN 模型的特征表示为
h
G
C
N
=
[
h
s
e
n
t
;
h
c
;
h
d
]
h_{GCN}=[h_{sent};h_c; h_d]
hGCN=[hsent;hc;hd]。
4. Multi-head Attention Layer
Attention 可以快速过滤处文本中的高价值信息,引入注意力机制可以大大提高关系抽取的效率和准确性。在多头自注意力层中的每个头部中集成了一个关系注意模块和一个自注意模块。相关度计算公式为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
Attention(Q, K, V)=softmax\big(\frac{QK^T}{\sqrt{d}}\big)V
Attention(Q,K,V)=softmax(dQKT)V 在关系注意模块中,
Q
Q
Q 是 Bi-LSTM 的输出矩阵,
K
K
K 和
V
V
V 为 基于CTD 知识库训练的关系嵌入。在自注意模块中,
Q
,
K
,
V
Q,K,V
Q,K,V 都是文本的特征。每个头的输出都是这两个模块的结果的和。
h
i
=
h
i
r
e
l
a
t
i
o
n
+
h
i
s
e
l
f
h_i = h_i^{relation} + h_i^{self}
hi=hirelation+hiself
h
=
[
h
1
;
h
2
;
…
;
h
n
]
h = [h_1;h_2;\dots;h_n]
h=[h1;h2;…;hn]
h
a
t
t
=
M
a
x
P
o
o
l
i
n
g
(
h
)
h_{att} = MaxPooling(h)
hatt=MaxPooling(h) 关系注意模块使文本表示更接近相应的关系标签,而远离其他标签。与自我注意模块相结合,可以访问更多的词汇和语义信息。多个头部可以让模型从不同的表示子空间学习相关信息。
5. Output Layer
首先,我们合并 Multi-head Attention Layer 和 GCN Layer 的输出
h
f
i
n
a
l
=
[
h
G
C
N
;
h
a
t
t
]
h_{final} = [h_{GCN}; h_{att}]
hfinal=[hGCN;hatt],然后,通过两层感知机:
h
1
=
R
e
L
U
(
W
h
1
h
f
i
n
a
l
+
b
h
1
)
h_1 = ReLU\big(W_{h_1}h_{final}+b_{h_1}\big)
h1=ReLU(Wh1hfinal+bh1)
h
2
=
R
e
L
U
(
W
h
2
h
f
i
n
a
l
+
b
h
2
)
h_2 = ReLU\big(W_{h_2}h_{final}+b_{h_2}\big)
h2=ReLU(Wh2hfinal+bh2) 最后,使用
softmax
\text{softmax}
softmax 函数来决定关系种类:
o
=
softmax
(
W
o
h
2
+
b
o
)
o = \text{softmax}\big(W_oh_2+b_o\big)
o=softmax(Woh2+bo)。
我们选择二元交叉熵来作为损失函数:
l
(
x
,
y
)
=
L
=
{
l
1
,
…
,
l
n
}
T
l(x,y) = L = \{l_1, \dots, l_n\}^T
l(x,y)=L={l1,…,ln}T
l
n
=
−
w
n
[
y
n
⋅
log
x
n
+
(
1
−
y
n
)
⋅
log
(
1
−
x
n
)
]
l_n = -w_n\big[y_n·\log{x_n} + (1 - y_n)·\log{(1 - x_n)}\big]
ln=−wn[yn⋅logxn+(1−yn)⋅log(1−xn)]
2.5 B-KGAGN
因为CDR任务属于生物医学领域,而Bio-BERT是由BERT预先在大规模生物医学语料库上训练的领域特定语言表示模型。它在各种生物医学文本挖掘任务上的性能大大超过了BERT。
3. Results and Discussion
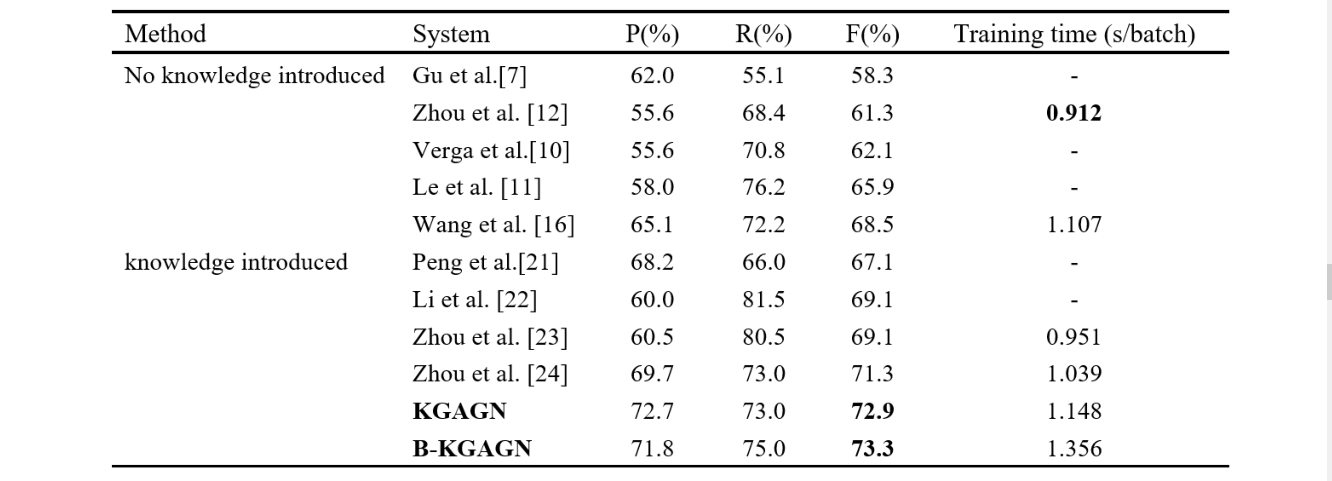
(1)知识嵌入的重要性
我们做了如下三个烧蚀实验:
① w/o实体嵌入:实体嵌入未连接到输入表示的模型,即知识嵌入仅与关系嵌入一起使用。
② w/o关系嵌入:没有将关系嵌入到多头注意层,而只引入了自我注意模块。唯一使用的知识嵌入是实体嵌入。
③ w/o知识嵌入:不使用知识嵌入,即既不引入实体嵌入,也不引入关系嵌入。实体嵌入不会连接到输入表示中,多头部注意层会进行自我注意计算。
对应的结果如下:
① F1得分下降了1.0%,这表明将根据先验知识训练的实体特征合并到模型的嵌入部分使模型对 CDR 预测更有效。
② 模型的性能显著降低了6.4%。这意味着我们从 CTD 训练的关系嵌入是 CDR 提取任务的直接证据。我们还尝试在模型的其他部分引入关系嵌入,例如在 GCN 层添加关系嵌入,对最终表示进行注意力计算,并在最终输出层嵌入关系。
③ 去除所有知识嵌入的模型表现最差,F1得分仅为 65.3%,表明将先验知识引入 KGAGN 的有效性。
(2)模型架构的重要性

① 去除 Multi-head Attention Layer,模型性能降低9.5%,主要原因是模型失去了关系嵌入的效果。
② 去除 GCN Layer,模型性能降低2.5%,模型到句子间级别的关系提取性能下降了4.3%,这说明依赖树和 GCN 模块可以获取对关系提取有用的长期依赖特征。
(3)Multi-head Attention Layer 的重要性
在多头自注意机制中,如果头数太少,则模型无法学习某些子空间上下文信息,而头数过多则会引入噪声。

3.1 Error analysis
假阳性错误:模型预测阳性病例而非阴性病例的错误。由于语义原因,我们的模型错误地预测了第一句话的实体对的 CID 关系。
假阴性错误:模型不能预测正确的 CID 关系。主要原因是在句间实例的构建阶段,句子间距离大于3的实体被我们忽略了。未来,我们将改进预处理和后处理方法,以实现更好的模型预测。

4. Conclusion
本文提出了一种新的端到端神经网络 KGAGN。通过实体嵌入和关系嵌入,该模型充分集成了领域知识。我们训练实体嵌入作为输入序列的特征表示,并训练关系嵌入以通过注意机制进一步捕获加权上下文信息。然后,为了在句间 CDR 提取中充分利用句法依赖信息,我们构造了一个文档级句法依赖树,并用 GCN 编码,GCN 可以提高句间关系提取的性能。此外,我们使用 BERT 预训练模型使整个模型更好地理解上下文语义信息。我们在 BioCreative-V CDR 数据集上评估了领域知识、多头自注意力机制、GCN、BioBERT的有效性。实验结果表明,这些小部件可以显著提高 CDR 提取的性能。我们的模型取得了 73.3% 的F分数,超过了当前最先进的方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









