







 本文介绍了一种使用Python和相关库(如BeautifulSoup4、requests、selenium、openpyxl)从中国空气质量在线监测分析平台爬取北京近三年空气质量历史数据的方法,并将其存储在Excel文件中。
本文介绍了一种使用Python和相关库(如BeautifulSoup4、requests、selenium、openpyxl)从中国空气质量在线监测分析平台爬取北京近三年空气质量历史数据的方法,并将其存储在Excel文件中。
任务: 从中国空气质量在线监测分析平台,按日爬取北京近3年的空气质量历史数据,存储在CSV/Excel数据表格中。
爬取网址:中国空气质量在线监测分析平台
运行环境:Python 3.7.2
第三方库:BeautifulSoup4(解析网页)、requests(获取打开网页)、selenium(模拟浏览器)、time(控制动态访问时间)、openpyxl(保存数据)
浏览器要求:需下载与本机谷歌浏览器版本配套的驱动chromedriver.exe,保存到相应安装目录;网址: http://npm.taobao.org/mirrors/chromedriver/ ;此处可以替换为其他浏览器,如火狐等。
网页分析: 通过分析网页代码可知,天气数据在tbody标签下面的所有tr子标签,其中第一个tr存储标题信息,其他tr存储对应url的每日天气信息,如下图:
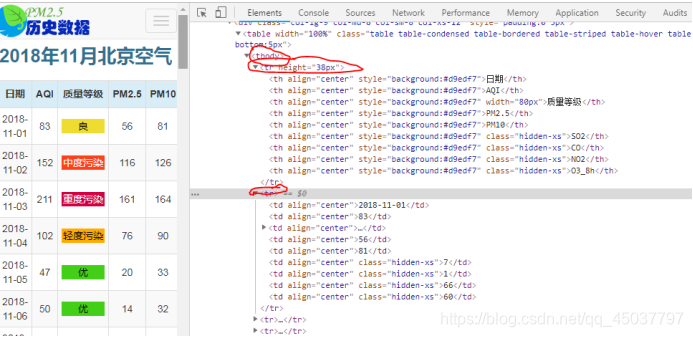
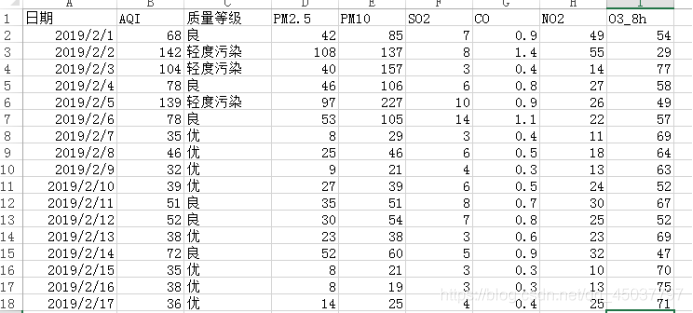
运行结果:
源代码:
import requests
import time
from openpyxl import Workbook,load_workbook
from bs4 import BeautifulSoup
from selenium import webdriver
#循环遍历获取对应天气数据的URL
def url(place):
ls=[]
for i in range(6,10):
if i==9:
for j in range(1,5):
c=(2010+i)*100+j
s="https://www.aqistudy.cn/historydata/daydata.php?city="+str(place)+"&month="+str(c)#观察网址变化部分,将网址看成字符串进行相关格式变化
ls.append(s)
else:
for j in range(1,13):
c=(2010+i)*100+j
s="https://www.aqistudy.cn/historydata/daydata.php?city="+str(place)+"&month="+str(c)
ls.append(s)
return ls #以列表作为返回值
#通过URL动态加载页面
def getText(url):
browser.get(url)
time.sleep(3) #等待模拟浏览器动态加载页面,每个三秒访问一次
text = browser.page_source
return text
#获取特定网页标签下的天气数据
def getData(text,ls1,i):
global ls
ls=ls1
soup=BeautifulSoup(text,"html.parser")
tr1=soup.tbody.tr #定位第一个tr标签
tr2=tr1.find_all("th") #定位tr标签下的th标签
tr3=soup.find("tbody").find_all("tr")
temp=[]
if i==0: #通过条件语句的判断保证表头的唯一性
for th in tr2:
s=th.get_text()
temp.append("".join(s.split()))
ls.append(temp)
#双重循环获取tr标签下所有td标签的内容并添加到列表
for tr in tr3[1:]:
temp=[]
tds=tr.find_all("td")
for td in tds:
b=td.get_text()
temp.append("".join(b.split()))
ls.append(temp)
return ls
#将天气数据写入Excel
def writexlsx(file,ls,name):
index = len(ls)
#打开Excel
wb=load_workbook(file)
#创建工作簿
sheet=wb.create_sheet(name)
#设置格式
sheet.column_dimensions['A'].width=13
#按行加入
for i in range(index):
sheet.append(ls[i])
#保存文件
wb.save(file)
print("天气数据写入成功!")
#主函数:完成加载页面、子函数的调用
if __name__=='__main__':
ls1=[]
place=input("请输入你想要查询的城市(市级以上):")
name=str(place)+"的天气数据"
print("数据正在写入,请耐心等待!")
browser = webdriver.Chrome(executable_path ='C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
for i in range(len(url(place))):
ls=getData(getText(url(place)[i]),ls1,i)
file=r'C:\Users\jl\Desktop\天气.xlsx'
writexlsx(file,ls,name)

















 1667
1667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









