







第三篇 GoogleNet
一、概述性论文介绍
这篇论文提出了一种名为Inception的深度卷积神经网络架构,也被称为GoogLeNet。这一架构在2014年的ImageNet大规模视觉识别挑战赛(ILSVRC2014)中取得了分类和检测任务的最佳性能,成为了当时的新标杆。
背景:在过去几年中,尤其是深度学习和卷积网络的进步,图像识别和目标检测的质量得到了显著提升。这些进步不仅仅得益于更强的硬件、更大的数据集和更大的模型,更重要的是新的想法、算法和改进的网络架构的出现。特别是在ILSVRC比赛中,顶尖的参赛队伍并没有使用额外的数据源,而是通过改进的网络设计来提升性能。
问题:尽管深度网络在图像识别任务中表现出色,但它们通常需要大量的计算资源,这在移动和嵌入式计算日益普及的今天成为了一个挑战。此外,随着网络深度的增加,模型参数的数量也随之增加,这可能导致过拟合,尤其是在标记数据有限的情况下。
解决方案:GoogLeNet通过引入Inception模块,实现了在保持计算预算不变的情况下增加网络的深度和宽度。这种设计基于Hebbian原理和多尺度处理的直觉,通过精心设计的架构,使得网络能够更有效地利用计算资源。Inception模块通过并行的不同尺寸卷积层(1×1、3×3和5×5)以及池化层来捕捉图像的不同尺度特征,并将它们的输出连接起来形成下一个层的输入。此外,为了减少计算负担,网络在适当的地方使用了1×1卷积来进行维度缩减。
关键点:GoogLeNet的设计考虑到了计算效率和实用性,使其不仅在学术上有意义,而且能够在实际应用中,即使是大型数据集上,也能够以合理的成本运行。这种架构的引入,不仅提高了模型的性能,而且通过减少参数数量和计算量,使得模型更加高效,这在当时是一个重要的创新。
二、论文介绍
2.1 论文提出的背景
GoogLeNet架构的提出是在深度学习,尤其是卷积神经网络(CNN)在图像识别和目标检测领域取得显著进展的背景下。这一进展并非仅仅依赖于更强的硬件、更大的数据集或更大的模型,而是新的想法、算法和改进的网络架构的成果。GoogLeNet的提出是为了在保持计算效率的同时,进一步提高模型的性能,特别是在ILSVRC这样的大规模视觉识别挑战赛中。
2.2 论文解决的问题
- 计算资源的高效利用:如何在不显著增加计算负担的情况下,提高网络的深度和宽度,以提升性能。
- 过拟合风险:随着网络深度的增加,如何避免因参数数量增多而导致的过拟合问题。
- 性能与效率的平衡:如何在有限的计算资源下,设计出能够实际部署并广泛应用的高效模型。
2.3 论文的创新性方案
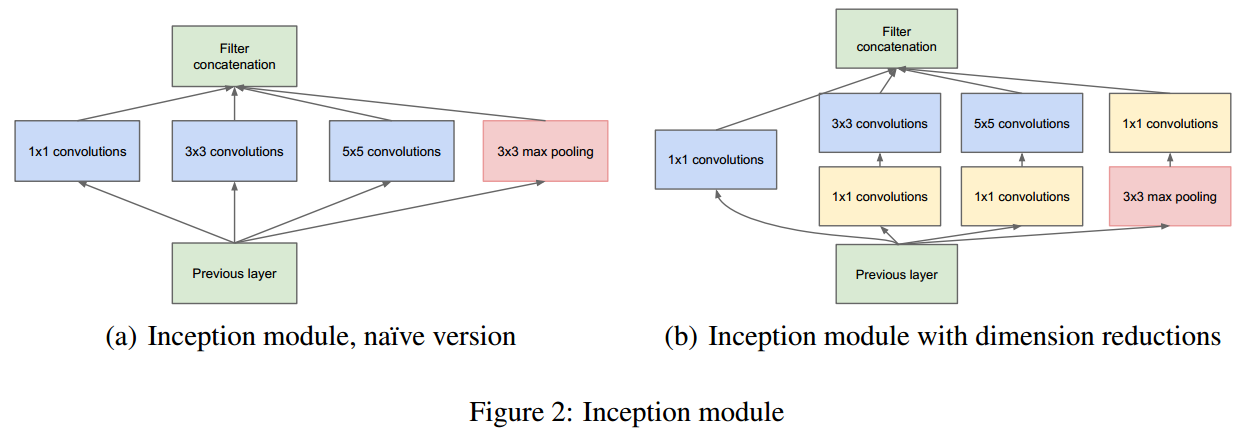
- Inception模块:提出了Inception模块,它通过并行的不同尺寸的卷积层(1×1、3×3、5×5)和池化层来捕捉图像的多尺度特征,并通过1×1卷积进行维度缩减,以优化计算效率。
- 辅助分类器:在网络的中间层引入辅助分类器,以增强低层特征的判别性,并提供额外的正则化,帮助更好地传播梯度。
- 多尺度处理:网络设计基于多尺度处理的直觉,允许同时抽象不同尺度的特征,提高了模型对图像的理解能力。
这些创新性方案使得GoogLeNet在ILSVRC2014中取得了突破性的成绩,同时保持了模型的计算效率,使其不仅在学术上有意义,也具有实际应用价值。
三、数据集介绍
GoogLeNet模型的实验是基于ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) 2014年的数据集进行的。ILSVRC是一个年度竞赛,旨在推动视觉识别领域的研究进展,特别是通过大规模的图像分类和目标检测任务。
数据集特点:
-
大规模:ILSVRC数据集包含约120万张图像,这些图像分布在1000个不同的类别中,每个类别大约有1200张图像。这种规模的数据集为深度学习模型提供了丰富的训练数据,有助于学习到更泛化的特征表示。
-
多样性:数据集中的图像涵盖了从常见的动物、植物、交通工具到各种日常用品等多种类别,这些类别之间存在显著的视觉差异,要求模型能够捕捉到细微的特征以区分不同的类别。
-
高分辨率:图像具有高分辨率,通常为数百到数千像素的边长,这为模型提供了丰富的空间信息,但同时也增加了处理图像的计算负担。
-
标注信息:每张图像都有一个或多个标注的类别标签,这些标签用于训练和评估模型的性能。此外,目标检测任务中还提供了精确的边界框标注,用于定位图像中的对象。
-
训练/验证/测试分割:数据集被分为训练集、验证集和测试集,其中训练集用于模型训练,验证集用于调整超参数和模型选择,测试集用于最终评估模型的性能。
-
挑战性:由于类别之间的视觉差异可能非常微妙,加之图像中对象的姿态、光照、遮挡等因素的多样性,ILSVRC数据集在图像识别任务上具有很高的挑战性。
GoogLeNet模型在ILSVRC2014的分类任务中取得了6.67%的top-5错误率,这是当时的最佳性能,显示了其在处理大规模图像数据集方面的卓越能力。此外,GoogLeNet还在目标检测任务中取得了第一名的成绩,进一步证明了其架构在不同视觉识别任务中的有效性和灵活性。通过在这些具有挑战性的数据集上的成功应用,GoogLeNet不仅推动了深度学习在图像识别领域的研究,也为后续的研究提供了重要的参考和基准。
四、论文模型介绍
4.1 模型整体框架
GoogLeNet模型的核心是Inception模块,这些模块构成了网络的主体结构。每个Inception模块都包含多个并行的卷积分支和一个池化分支,这些分支的输出会被合并。模型的输入是224×224像素的RGB图像,经过一系列Inception模块和池化层后,特征图的空间尺寸逐渐减小,而通道数(深度)逐渐增加。在网络的末端,使用全局平均池化层来减少每个特征图的空间尺寸,得到一个固定长度的特征向量。最后,通过一个全连接层和softmax层,模型输出每个类别的概率分布。
4.2 模型关键组成
- Inception模块:这是GoogLeNet的核心组件,它通过并行的不同尺寸的卷积层(1×1、3×3、5×5)和3×3的最大池化层来捕捉图像的不同尺度特征。1×1卷积用于维度缩减,以控制模型的宽度和深度。
- 辅助分类器:在网络的中间阶段引入辅助分类器,这些分类器可以提供额外的梯度信号,帮助训练更深的网络,并作为正则化手段防止过拟合。
- 全局平均池化:在网络的末端使用全局平均池化层来减少特征图的空间尺寸,从而将特征图转换为固定长度的特征向量,便于后续的分类。
4.3 模型的输入输出
- 输入:模型接受224×224像素的RGB图像作为输入,图像在输入网络之前会进行均值化处理。
- 输出:模型的输出是一个概率分布向量,长度为1000(对应ILSVRC的1000个类别),表示每个类别的预测概率。
4.4 损失函数
GoogLeNet模型使用的是softmax交叉熵损失函数,这是多类别分类问题中常用的损失函数。对于一个样本,其真实类别标签表示为one-hot编码的向量( y ),模型预测的概率分布表示为( p ),损失函数定义为:
L ( y , p ) = − ∑ i = 1 M y i log ( p i ) L(y, p) = -\sum_{i=1}^{M} y_i \log(p_i) L(y,p)=−i=1∑Myilog(pi)
其中,( M )是类别的总数。对于ILSVRC的1000个类别,这个损失函数会鼓励模型正确预测类别,并且对于错误的预测给予较大的惩罚。通过最小化这个损失函数,模型能够学习到更准确的分类边界。
4.5 代码实现
import torch
from torch import Tensor
from torch import nn
from collections import namedtuple
from typing import Optional, Tuple, Any
class GoogLeNet(nn.Module):
__constants__ = ["aux_logits", "transform_input"]
def __init__(
self,
num_classes: int = 1000,
aux_logits: bool = True,
transform_input: bool = False,
dropout: float = 0.2,
dropout_aux: float = 0.7,
) -> None:
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.transform_input = transform_input
self.conv1 = BasicConv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
self.maxpool1 = nn.MaxPool2d((3, 3), (2, 2), ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.conv3 = BasicConv2d(64, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.maxpool2 = nn.MaxPool2d((3, 3), (2, 2), ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d((3, 3), (2, 2), ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d((2, 2), (2, 2), ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if aux_logits:
self.aux1 = InceptionAux(512, num_classes, dropout_aux)
self.aux2 = InceptionAux(528, num_classes, dropout_aux)
else:
self.aux1 = None
self.aux2 = None
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(dropout, True)
self.fc = nn.Linear(1024, num_classes)
# Initialize neural network weights
self._initialize_weights()
@torch.jit.unused
def eager_outputs(self, x: Tensor, aux2: Tensor, aux1: Optional[Tensor]) -> GoogLeNetOutputs | Tensor:
if self.training and self.aux_logits:
return GoogLeNetOutputs(x, aux2, aux1)
else:
return x
def forward(self, x: Tensor) -> Tuple[Tensor, Optional[Tensor], Optional[Tensor]]:
out = self._forward_impl(x)
return out
def _transform_input(self, x: Tensor) -> Tensor:
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1)
return x
# Support torch.script function
def _forward_impl(self, x: Tensor) -> GoogLeNetOutputs:
x = self._transform_input(x)
out = self.conv1(x)
out = self.maxpool1(out)
out = self.conv2(out)
out = self.conv3(out)
out = self.maxpool2(out)
out = self.inception3a(out)
out = self.inception3b(out)
out = self.maxpool3(out)
out = self.inception4a(out)
aux1: Optional[Tensor] = None
if self.aux1 is not None:
if self.training:
aux1 = self.aux1(out)
out = self.inception4b(out)
out = self.inception4c(out)
out = self.inception4d(out)
aux2: Optional[Tensor] = None
if self.aux2 is not None:
if self.training:
aux2 = self.aux2(out)
out = self.inception4e(out)
out = self.maxpool4(out)
out = self.inception5a(out)
out = self.inception5b(out)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.dropout(out)
aux3 = self.fc(out)
if torch.jit.is_scripting():
return GoogLeNetOutputs(aux3, aux2, aux1)
else:
return self.eager_outputs(aux3, aux2, aux1)
def _initialize_weights(self) -> None:
for module in self.modules():
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):
torch.nn.init.trunc_normal_(module.weight, mean=0.0, std=0.01, a=-2, b=2)
elif isinstance(module, nn.BatchNorm2d):
nn.init.constant_(module.weight, 1)
nn.init.constant_(module.bias, 0)
class BasicConv2d(nn.Module):
def __init__(self, in_channels: int, out_channels: int, **kwargs: Any) -> None:
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
self.relu = nn.ReLU(True)
def forward(self, x: Tensor) -> Tensor:
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
return out
class Inception(nn.Module):
def __init__(
self,
in_channels: int,
ch1x1: int,
ch3x3red: int,
ch3x3: int,
ch5x5red: int,
ch5x5: int,
pool_proj: int,
) -> None:
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv2d(ch3x3red, ch3x3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
BasicConv2d(ch5x5red, ch5x5, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), ceil_mode=True),
BasicConv2d(in_channels, pool_proj, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0)),
)
def forward(self, x: Tensor) -> Tensor:
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
out = [branch1, branch2, branch3, branch4]
out = torch.cat(out, 1)
return out
class InceptionAux(nn.Module):
def __init__(
self,
in_channels: int,
num_classes: int,
dropout: float = 0.7,
) -> None:
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d((4, 4))
self.conv = BasicConv2d(in_channels, 128, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0))
self.relu = nn.ReLU(True)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(dropout, True)
def forward(self, x: Tensor) -> Tensor:
out = self.avgpool(x)
out = self.conv(out)
out = torch.flatten(out, 1)
out = self.fc1(out)
out = self.relu(out)
out = self.dropout(out)
out = self.fc2(out)
return out
实验介绍
5.1 实验配置
在训练和验证GoogLeNet模型时,采用了以下实验配置:
- 数据集:使用了ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) 2014的数据集,这是一个包含约120万张图像的大型数据集,分为1000个类别。
- 输入尺寸:图像被调整为224×224像素,并进行均值化处理。
- 优化算法:使用异步随机梯度下降(SGD)与动量,初始学习率设置为0.01,并在每8个epoch后降低学习率。
- 正则化:应用了权重衰减(L2正则化)和dropout作为正则化手段,以及使用了辅助分类器来增强网络的泛化能力。
- 批量大小:批量大小设置为32。
- 训练迭代:模型在训练集上进行了多个epoch的训练,直到性能不再提升。
5.2 实验效果
GoogLeNet模型在ILSVRC 2014的实验中取得了显著的成效:
- 分类任务:在分类任务中,GoogLeNet达到了6.67%的top-5错误率,这是当时的最佳性能,相比前一年的最佳模型性能提升了近40%。
- 目标检测任务:在目标检测任务中,GoogLeNet也取得了第一名的成绩,展示了其在多尺度特征提取方面的优势。
- 计算效率:尽管模型非常深(22层),但它的计算效率仍然很高,这得益于Inception模块的设计,使得网络能够在有限的计算资源下运行。
然而,模型也存在一些问题:
- 训练时间:由于模型的深度,训练GoogLeNet需要较长的时间,尤其是在没有高性能计算资源的情况下。
- 内存消耗:模型在训练和推理时消耗的内存相对较大,这可能限制了其在内存受限的设备上的应用。
总体来说,GoogLeNet在ILSVRC 2014上的表现证明了其在图像识别领域的有效性和创新性,尽管存在一些挑战,但其在深度学习模型设计方面的贡献是显著的。
六、评价
6.1 创新点
GoogLeNet模型的主要创新点包括:
-
Inception模块:这是模型的核心组件,它通过并行的不同尺寸的卷积层和池化层来捕捉图像的多尺度特征。这种设计提高了网络的性能,同时保持了计算效率。
-
辅助分类器:在网络的中间层引入辅助分类器,这不仅提供了额外的训练信号,有助于防止过拟合,还增强了梯度的传播,使得更深的网络训练成为可能。
-
深度和宽度的平衡:GoogLeNet通过Inception模块的设计,在增加网络深度的同时控制了参数数量,使得模型能够在有限的计算资源下运行。
这些创新点在现在的深度学习中占有重要地位,Inception模块的概念被广泛应用于后续的网络设计中,如Inception v3、v4等,并且辅助分类器的概念也被用于其他深度学习模型中,以提高训练效果。
6.2 关键技术点评
GoogLeNet的关键技术对深度学习领域产生了深远的影响:
-
多尺度特征学习:Inception模块的引入使得网络能够同时学习到不同尺度的特征,这对于理解图像中的复杂结构至关重要。
-
正则化和梯度传播:辅助分类器的使用不仅提高了模型的泛化能力,还改善了深度网络的训练过程,特别是在训练非常深的网络时。
-
计算效率:GoogLeNet展示了如何在不牺牲性能的情况下设计计算效率高的深度模型,这对于将深度学习应用于实际问题具有重要意义。
6.3 存在问题
尽管GoogLeNet在多个方面取得了突破,但仍存在一些问题和挑战:
-
模型复杂性:尽管Inception模块提高了计算效率,但GoogLeNet的总体结构仍然相对复杂,这可能使得模型难以理解和调试。
-
训练资源需求:虽然GoogLeNet在设计上考虑了计算效率,但训练一个深度的网络仍然需要大量的计算资源。
-
内存消耗:模型在训练和推理时的内存消耗较大,这限制了其在资源受限的设备上的应用。
后续的研究中,新的网络架构如MobileNets和EfficientNets等,通过引入新的设计理念和技术,如深度可分离卷积和复合缩放,进一步优化了模型的效率和性能,使得深度学习模型能够在更广泛的应用场景中使用。
七、关键提问
Q1: GoogLeNet模型中的Inception模块具体是如何工作的?
GoogLeNet模型中的Inception模块是一种精心设计的网络结构,旨在同时提供多种尺度的卷积操作,以便捕捉图像的不同尺度特征。具体来说,Inception模块的工作原理如下:
-
并行卷积分支:Inception模块包含几个并行的卷积分支,每个分支由不同尺寸的卷积层组成。这些分支通常包括:
- 一个1×1卷积层,用于减少维度,即通道数,同时学习特征的局部组合。
- 一个3×3卷积层,用于捕捉局部特征。
- 一个5×5卷积层,用于捕捉更大范围的上下文信息。
- 每个卷积层后通常会跟随一个非线性激活函数,如ReLU。
-
池化分支:除了卷积分支,Inception模块还包含一个池化分支,通常是3×3的最大池化层,后跟1×1卷积层。这个分支的目的是在降低特征图空间尺寸的同时,保留重要的信息。
-
输出合并:所有并行分支的输出(卷积和池化)会被合并(或拼接)成一个单一的特征图,这个特征图将包含来自不同尺度和不同卷积核的特征信息。
-
维度调整:为了使所有分支的输出能够在通道数上匹配并能够合并,可能会使用1×1卷积层来调整某些分支的输出维度。
Inception模块的关键优势在于它能够以较低的计算成本捕捉丰富的多尺度信息。通过这种方式,网络可以在不同层次上学习到从局部细节到全局上下文的多种特征,这对于图像识别和分类任务至关重要。此外,Inception模块的设计允许网络在保持计算效率的同时增加深度,因为它通过1×1卷积来有效地管理通道数,从而避免了计算量的指数级增长。
Q2: 具体的说明一下模型中的辅助分类器是怎么修改网络结构产生的?它具备什么样的功能?
在GoogLeNet模型中,辅助分类器的引入是为了增强网络的训练过程,特别是在网络深度增加时。辅助分类器通过在网络的中间层添加额外的输出分支来实现,这些分支被称为辅助分支。以下是辅助分类器如何修改网络结构以及它们所具备的功能:
辅助分类器对网络结构的修改:
-
辅助分支的添加:在GoogLeNet的Inception模块中,除了标准的卷积和池化层之外,还添加了一个或多个辅助分支。这些分支从Inception模块的输出中提取特征。
-
特征提取:辅助分支通常开始于一个1×1的卷积层,用于减少特征图的深度,即通道数。这一步骤有助于提取更加紧凑的特征表示。
-
全局平均池化:随后,特征图通过全局平均池化层,这一层将特征图的空间维度压缩为一个单一的全局特征向量。
-
分类层:最后,全局特征向量通过一个或多个全连接层,最终到达一个softmax分类层,该层输出每个类别的概率。
辅助分类器的功能:
-
正则化:辅助分类器为网络提供了额外的训练目标,这有助于防止过拟合。通过在网络的多个层次上施加监督,辅助分类器鼓励网络学习更泛化的特征表示。
-
梯度强化:在训练过程中,辅助分类器的损失会与主分类器的损失相结合。这有助于在网络的更深层次中产生更强烈的梯度信号,从而改善梯度的传播和参数的更新。
-
多尺度学习:辅助分类器使得网络能够在不同的尺度上学习特征,因为它们从不同层次的特征图中提取信息。这有助于网络捕捉到不同大小和复杂度的视觉模式。
-
训练策略优化:辅助分类器的引入允许网络在训练过程中更加灵活地调整其结构,以适应数据的特性。这种策略可以被视为一种动态的网络结构调整,有助于提高模型的最终性能。
总的来说,辅助分类器通过在网络的中间层引入额外的分类任务,增强了网络的训练过程,提高了模型的泛化能力和最终的分类性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









