







Papers Notes_2_ VGG--Very Deep Convolutional Networks for Lage-scale Image Recognition
Architecture
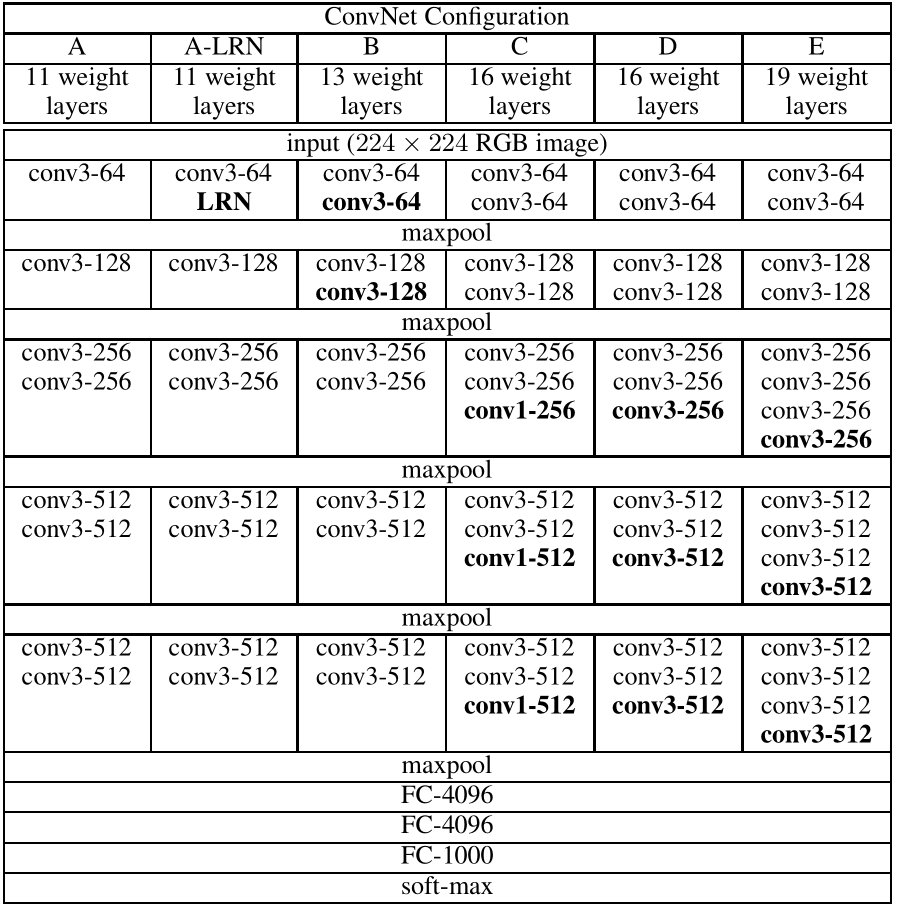
input-224×224 RGB image
preprocess-subtract the mean RGB value,computed on the training set,from each pixel
stride-fixed to 1 pixel
padding-the spartial resolution is preserved after convolution, i.e. the padding is 1 pixel for 3×3 conv.
Max-pooling-performed over a 2×2 pixel window, with stride 2
All hidden layers are equipped with the rectification none-linearity(ReLU).
None contain Local Response Normalization(LRN)→do not improve the performance
- 3×3 conv.
a stack of two 3×3 conv. layers has an effective receptive field of 5×5
three such layers have a 7×7 effective receptive field
why a stack of three 3×3 conv. layers instead of a single 7×7 layer?
① incorporate three non-linear rectification layers instead of a single one→make the decision function more discriminative
② decrease the number of parameters
three-layer 3×3 conv. stack with C channels, parameters→ 3 ( 3 2 C 2 ) = 27 C 2 3(3^2C^2)=27C^2 3(32C2)=27C2
a single 7×7 conv. layer, parameters→ 7 2 C 2 = 49 C 2 7^2C^2=49C^2 72C2=49C2 - 1×1 conv.
increase the non-linearity of decision function without affecting the receptive fields of the conv. layers→an additional non-linearity is introduced by rectification function
Training
- details
batch size-256
momentum-0.9
weight decay-0.0005
dropout ratio-0.5, for the first two fully-connected layers
learning rate-0.01, decreased by a factor of 10 when the validation set accuracy stopped improving. decreased 3 times, learning stopped after 370K iterations(74 epochs) - initialization
began with training A, shallow enough to be trained with random initialization
training deeper, initialised first four conv. layers and the last three fully-connected layers with the layers of net A
random initialization→sample the weights from a normal distribution with the zero mean and 0.01 variance. biases initialised with 0 - augment
① randomly crop from rescaled training images(one crop per image per SGD iteration)
② random horizontal flipping
③ random RGB colour shift(same with AlexNet) - rescale
S: smallest side of an isotropically-rescaled training image
two approaches for setting S
① fix S(256 or 384)→single-scale training
② randomly sample S from a certain range [ S m i n , S m a x ] [S_{min},S_{max}] [Smin,Smax] (use [256,384])→multi-scale training
Testing
- rescale
Q: smallest side of an isotropically-rescaled image, not necessarily equal to the training scale S
input image size different→FC covert to conv.
first FC layer→7×7 conv. layer
the last two FC layers→1×1 conv. layers
why 7×7?
padding makes sure that the spartial resolution is preserved after conv. layer
then resolution reduces only because of maxpool, specifically, reduces half
i.e. structure A has 5 maxpool layers→224/2^5=7, so the output of conv. stack is 7×7×512
for the first FC layer, one channel corresponds to 49 weights→convert to conv. layer, use the same parameters, so the kernel size needs to be 7×7
no FC layer→input image size does not need to be 224×224→apply to the whole(uncropped) image
result→a class map, the number of channels equals to the number of classes, a variable spatial resolution dependent on the input image size
spatially average(sum-pooled)→obtain a fixed-size vector of class scores for the image - augment
rescale+horizontal flipping, average→the final scores
Conclusion
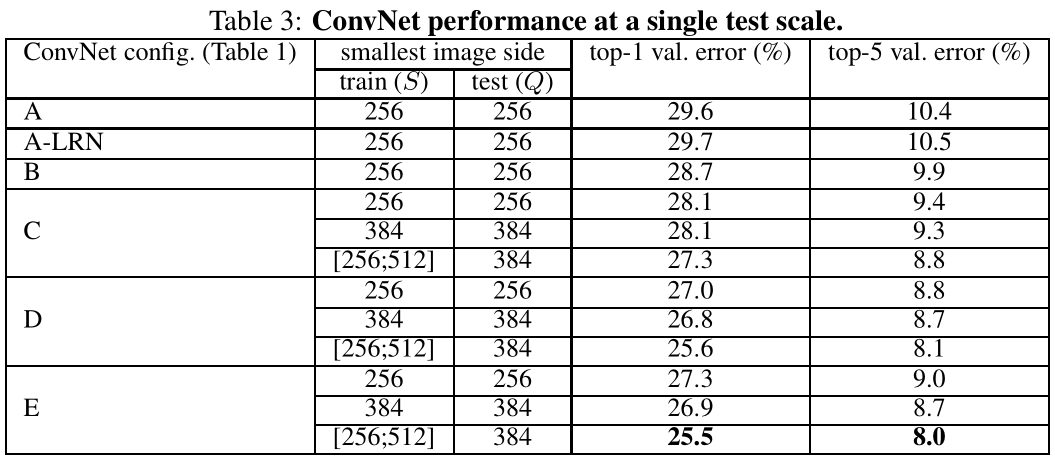
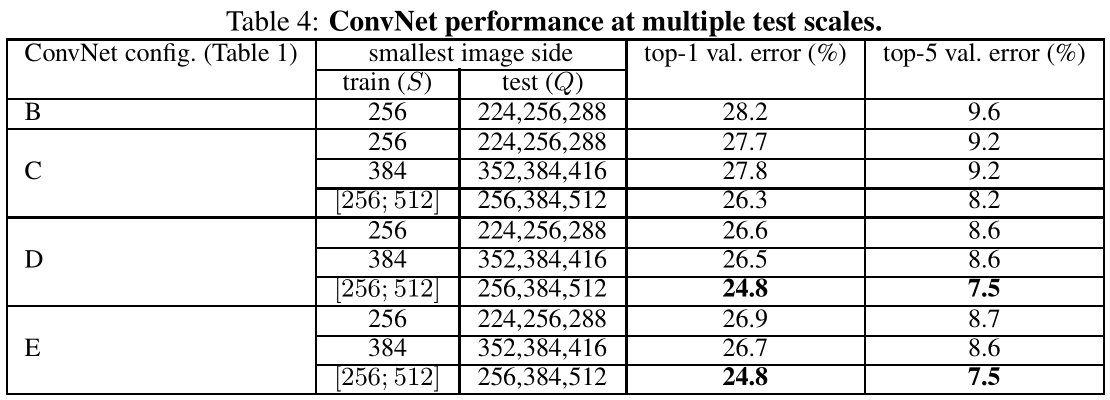
confirm the importance of depth in visual representations
References
Very Deep Convolutional Networks for Lage-scale Image Recognition


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









