






 文章介绍了如何使用Python处理多个NetCDF文件,计算每年的月平均值。通过循环遍历文件和月份,避免一次性加载大量数据导致内存问题。代码示例展示了详细的数据处理步骤,包括读取文件、选取特定月份、计算平均值和保存结果到新的NetCDF文件。
文章介绍了如何使用Python处理多个NetCDF文件,计算每年的月平均值。通过循环遍历文件和月份,避免一次性加载大量数据导致内存问题。代码示例展示了详细的数据处理步骤,包括读取文件、选取特定月份、计算平均值和保存结果到新的NetCDF文件。
前言
Hello 大家好,今天和大家讲一讲如何使用Python计算多年份,多文件的月平均值。
数据介绍
本次数据由Fans亲情提供,数据大致状况如下:
每一年一个独立的NC文件,并且每个文件中为十二个月
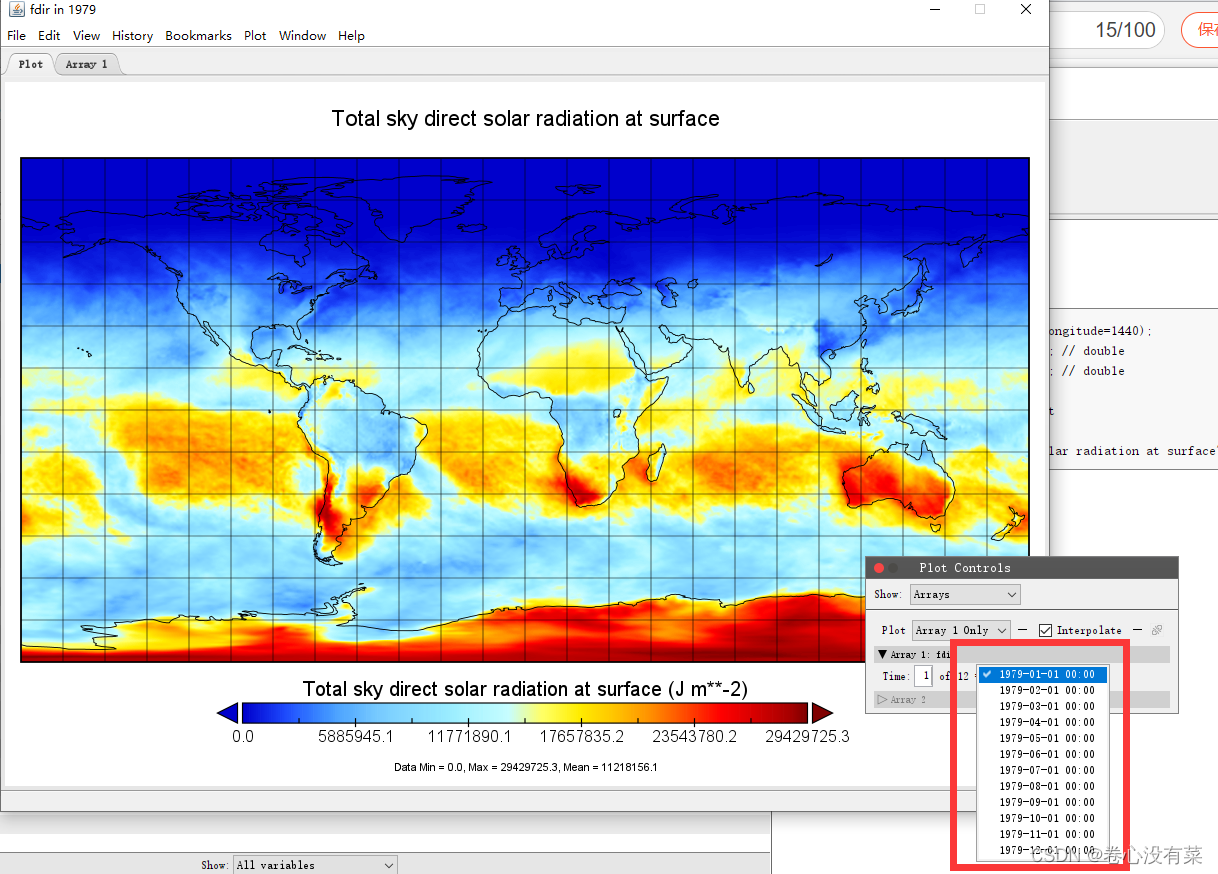
然后,就想要将这些文件批量计算为多年的月平均值。
示例数据下载:
https://wwff.lanzoum.com/b04q17f4d
密码:hi5a
思路&想法
我在这里有两个想法:
- 直接将所有的NC文件进行拼接整合,然后一行代码直接计算多年平均值,但是这样会带来一个直接问题,如果所需要计算的NC文件过大,那么整合起来的NC文件会容量会原地爆炸的,在计算过程中就有可能会炸内存等。
- 第二个就是嵌套两层循环,第一层循环是1-12月循环,第二层循环为文件循环,这样也会有一个问题执行效率偏低,但是胜在不会炸内存,本次我主要将这种方式。
- 不要问我为啥不用第一个,我在自己处理数据的时候经常炸内存!!!!
代码
库引用
import xarray as xr
import os
import numpy as np
import pandas as pd
文件路径配置
path = r'F:\优快云\2023.6.11\nc_files/' # 文件夹路径,修改成自己的路径,这里面只能有待合成的NC,我没写文件过滤!!
file_list = os.listdir(path)
# 正序排序
file_list.sort()
file_list
计算平均值
file_list = [path + i for i in file_list] # 合成文件路径
out_nc = xr.Dataset() # 创建一个空的Dataset
avg_array = []
avg_month = []
month = '2016-' # 自定义的输出文件时间(年份),修改成自己的时间
for j in range(1,13):
current_month_array = []
for i in range(len(file_list)):
f = xr.open_dataset(file_list[i])
f = f.sel(time = f['time.month'] == j)
lat = f['latitude'].values
lon = f['longitude'].values
fdir = f['fdir'].values
# 第一纬度为1,去掉
# fdir = fdir[0] # 这一句用用来剔除多余纬度的!!,默认是注释掉的,请大家根据实际情况选择
current_month_array.append(fdir)
f.close() # 关闭文件,释放内存
avg_month.append(pd.to_datetime(month + str(j)))
current_month_array = np.array(current_month_array)
avg_array.append(np.mean(current_month_array, axis = 0))
avg_array = np.array(avg_array)
# print(avg_array.shape)
out_nc['fdir'] = (('time','latitude','longitude'), np.array(avg_array)) # 输出文件的变量名,修改成自己的变量名
out_nc['time'] = (('time'), np.array(avg_month))
out_nc['latitude'] = (('latitude'), lat)
out_nc['longitude'] = (('longitude'), lon)
out_nc['fdir'].attrs['units'] = 'J m**-2' # 修改成自己的单位
out_nc['latitude'].attrs['units'] = 'degrees_north' # 配置lat的单位
out_nc['longitude'].attrs['units'] = 'degrees_east' # 配置lon的单位
out_nc.to_netcdf(r'F:\优快云\2023.6.11\avg_fdir.nc') # 输出文件路径,修改成自己的路径
完整代码
import xarray as xr
import os
import numpy as np
import pandas as pd
path = r'F:\优快云\2023.6.11\nc_files/' # 文件夹路径,修改成自己的路径
file_list = os.listdir(path)
# 正序排序
file_list.sort()
file_list
file_list = [path + i for i in file_list]
out_nc = xr.Dataset()
avg_array = []
avg_month = []
month = '2016-' # 自定义的输出文件时间(年份),修改成自己的时间
for j in range(1,13):
current_month_array = []
for i in range(len(file_list)):
f = xr.open_dataset(file_list[i])
f = f.sel(time = f['time.month'] == j)
lat = f['latitude'].values
lon = f['longitude'].values
fdir = f['fdir'].values
# 第一纬度为1,去掉
fdir = fdir[0]
current_month_array.append(fdir)
f.close()
avg_month.append(pd.to_datetime(month + str(j)))
current_month_array = np.array(current_month_array)
avg_array.append(np.mean(current_month_array, axis = 0))
avg_array = np.array(avg_array)
# print(avg_array.shape)
out_nc['fdir'] = (('time','latitude','longitude'), np.array(avg_array)) # 输出文件的变量名,修改成自己的变量名
out_nc['time'] = (('time'), np.array(avg_month))
out_nc['latitude'] = (('latitude'), lat)
out_nc['longitude'] = (('longitude'), lon)
out_nc['fdir'].attrs['units'] = 'J m**-2' # 修改成自己的单位
out_nc['latitude'].attrs['units'] = 'degrees_north'
out_nc['longitude'].attrs['units'] = 'degrees_east'
out_nc.to_netcdf(r'F:\优快云\2023.6.11\avg_fdir.nc') # 输出文件路径,修改成自己的路径


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











