







源代码
# encoding: utf-8
import pandas as pd
import time
import os
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("-in",help="the name of input file",dest = "input",type=str,default="stats.txt")
parser.add_argument("-out",help="the name of output file",dest = "output",type=str,default="analysis.csv")
args = parser.parse_args()
list3,list2 = list(),list()
the_loc = os.getcwd()
ana_path = os.path.join(the_loc,args.output)
print(ana_path)
if os.path.isfile(ana_path):
print('文件存在')
else:
f = open(args.output, "x")
f.close()
for lines in open(args.input):
list1 = lines.strip().split()
try:
list2.append(list1[1])
list3.append(list1[0])
except:
pass
try:
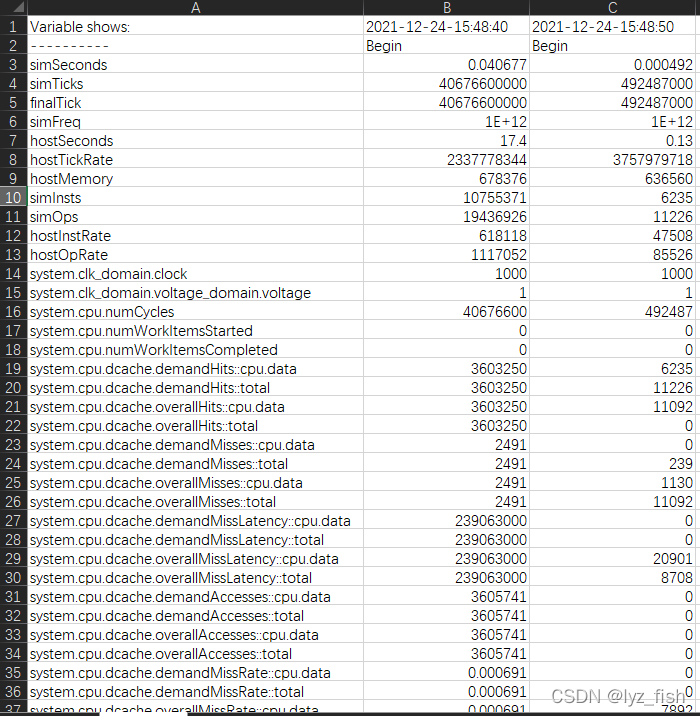
old_v = pd.read_csv(os.path.join(the_loc,args.output))
df = pd.DataFrame({time.strftime("%Y-%m-%d-%H:%M:%S", time.localtime()):list2})
print("df.shape=",df.shape)
print('old_v_shape:',old_v.shape)
new = pd.concat([old_v,df],axis=1)
new.to_csv(args.output,index=False,header=True)
print('从已有文件获取')
except:
print('重新开始:\n')
attribution = pd.DataFrame({"Variable shows:":list3})
first_v = pd.DataFrame({time.strftime("%Y-%m-%d-%H:%M:%S", time.localtime()):list2})
new1 = pd.concat([attribution,first_v],axis=1)
new1.to_csv(args.output, index=False,header=True)
print('done')
将文件存为python文件
保存到/mnt/gem5/m5out下文件的任意名称得python文件。
- 环境:python3
- 依赖的库:pandas => 通过
sudo pip3 install pandas下载
运行
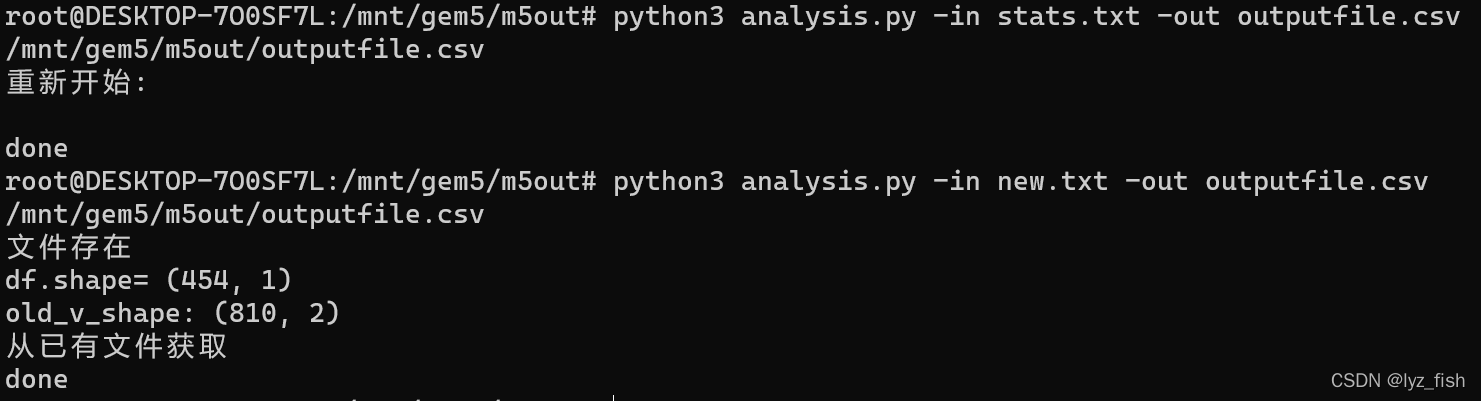
在m5out文件下,运行如下脚本。可以更改-in and -out之后的文件名称。但是-out之后的名称多次运行为输入的位置,因此不要改变,否则会新建对应名称的文件。
python3 analysis.py -in new.txt -out outputfile.csv

















 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









