




文章目录
技术在不断演进,曾经的性能利器也可能成为时代的眼泪。MySQL的查询缓存(Query Cache)便是这样一个经典的案例。本文将带您深入探索其原理、兴衰史,以及在高并发时代我们应有的架构思维。
一、何为MySQL查询缓存?—— 昔日的性能加速器
在MySQL 8.0之前的版本中,查询缓存是内置于MySQL服务器中的一个核心特性,其主要目标是提升重复读取操作的性能。
我们可以将其理解为一个位于内存中的“键值对”字典:
- 键(Key):查询语句的文本本身(需逐字节精确匹配)及其它一些信息(如数据库、客户端协议版本)计算出的哈希值。
- 值(Value):该查询语句对应的完整结果集。
当一条SELECT查询到来时,MySQL会首先在这个“字典”中查找。如果找到完全匹配的键,它就可以绕过复杂的解析、优化和执行阶段,直接将缓存的结果返回给客户端。这个过程开销极低,对于重复查询来说,性能提升是数量级的。
设计初衷:在典型的“读多写少”型应用(如早期的博客、CMS内容管理系统)中,相同查询被频繁执行的场景非常普遍。查询缓存的引入,旨在通过空间换时间,大幅降低数据库的CPU和I/O压力。
二、查询缓存如何工作?—— 精密而严格的工作流程
查询缓存的工作机制并非简单的“匹配-返回”,而是一个包含多重检查的精密流程。其核心工作流程,可以通过下图一目了然:
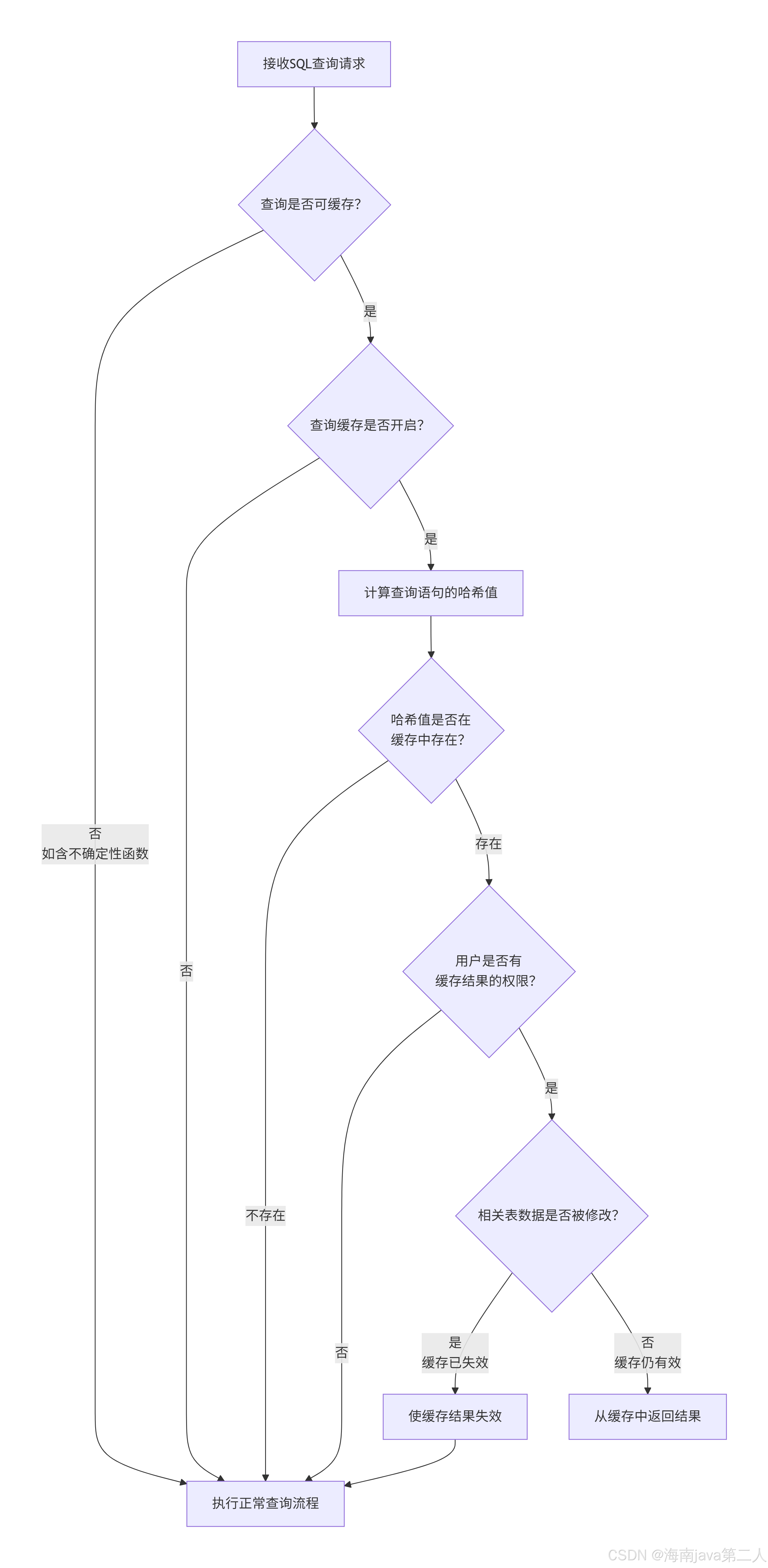
以下是流程中各环节的详细说明:
1. 资格预审:是否可缓存?
并非所有查询都具备缓存资格。以下情况会被直接剥夺“参赛权”:
- 包含不确定性函数:如
NOW(),RAND(),CURRENT_DATE()。 - 查询位于存储过程或函数中。
- 查询涉及系统表(如
mysql库下的表)。 - 查询未引用任何表(如
SELECT 1)。
2. 哈希寻址:计算唯一身份ID
对于可缓存查询,MySQL会对其原始文本(包括大小写、空格)计算一个唯一的哈希值,作为在缓存中查找的“钥匙”。
3. 权限安检:你是否被允许走此捷径?
这是一个至关重要的安全措施。即使缓存命中,MySQL也会验证当前执行查询的用户是否拥有访问缓存结果中数据的权限。这防止了用户通过缓存绕过表级权限检查。
4. 有效性终审:数据是否依然“新鲜”?
这是保证数据强一致性的核心机制。MySQL会检查该查询所涉及的所有基表。自结果被缓存后,只要有任何对这些表的写操作(INSERT/UPDATE/DELETE/TRUNCATE/ALTER TABLE 等),那么所有依赖于这些表的缓存条目都会被无条件地标记为失效并清除。这确保了应用程序永远不会从缓存中读取到过时的“脏数据”。
只有通过以上所有严苛的检查,缓存的结果才会被返回,并在 Qcache_hits 状态变量中记录一次命中。否则,查询将走完整的执行流程,并且如果它依然可缓存,其新结果会被存入缓存,以备下次之需。
三、为何最终被弃用?—— 成也萧何,败也萧何
尽管设计精巧,但查询缓存在高并发、高写入的现代应用环境中,暴露出了难以克服的致命缺陷,最终导致其在 MySQL 5.7.20版本被标记为弃用,并在MySQL 8.0中彻底移除。
1. 全局锁瓶颈:并发性能的“绞杀者”
查询缓存由一个全局锁(LOCK_query_cache) 保护。所有对缓存的操作(检查、失效、存储)都必须获得这个独占锁。
- 在高并发读场景下:大量线程排队等待检查缓存,反而增加了延迟。
- 在写操作发生后:失效缓存的请求会阻塞所有后续的缓存检查,导致请求堆积。
这使得查询缓存从一个性能加速器,变成了一个严重的单点瓶颈。
2. 失效风暴:高写入负载下的“雪崩”推手
想象一下,一个频繁更新的表(如用户会话表)发生了一次写操作。这次操作会瞬间清除缓存中所有与该表相关的成百上千个缓存条目。紧接着,大量请求这些已失效结果的查询涌入,由于缓存失效,它们会全部涌向数据库执行真正的查询,极易导致数据库CPU和I/O瞬间飙升,引发缓存雪崩,甚至拖垮整个服务。
3. 过于僵化的匹配策略
“逐字节匹配”意味着以下两个查询不会被视为相同:
SELECT * FROM users WHERE id = 1;
select * from users where id = 1; -- 大小写不同
SELECT * FROM users WHERE id = 1; -- 多了空格
这种严格性大大降低了缓存的命中率。
4. 内存管理开销
配置不当时(query_cache_size 和 query_cache_limit),缓存可能被大量小查询或少数几个大结果集占满。当内存不足时,MySQL需要执行清理操作(Qcache_lowmem_prunes),这本身也带来额外开销。
结论:在数据更新频繁的OLTP系统中,查询缓存的维护成本(锁竞争、失效开销) 远远超过了它带来的性能收益。它就像一个好心办坏事的管家,越想帮忙,系统就越乱。
四、后查询缓存时代的架构选择 —— 面向未来的优化之道
既然内置的查询缓存已成历史,我们应如何应对?答案是采用更现代、更专业的架构方案。
1. 应用层缓存(推荐)
这是目前最主流、最有效的解决方案。将缓存逻辑从数据库层剥离,移至应用层。
- 代表技术:Redis、Memcached。
- 核心优势:
- 解耦与弹性:缓存层与数据库层独立,不会对数据库性能产生任何负面影响。
- 极致的灵活性:可以缓存任何数据——SQL结果、计算后的业务对象、会话状态等。
- 丰富的数据结构:支持String, Hash, List, Set等,能应对更复杂的场景。
- 分布式与高可用:原生支持集群模式,扩展性和可用性极强。
2. 数据库内核优化
与其依赖外部缓存,不如从根本上让数据库跑得更快。
- 精细化的索引策略:合理的索引是提升查询性能的第一法宝。
- 查询语句优化:避免
SELECT *,优化慢查询,合理使用JOIN。 - 利用缓冲池(InnoDB Buffer Pool):这是InnoDB引擎的“真香”缓存。它缓存的是数据页和索引页,相比查询缓存,其粒度更细,有效性与数据是否变更无关,能极大加速数据访问。
3. 数据库架构扩展
- 主从复制(Read/Write Splitting):搭建主从集群,将写操作定向到主库,将大量的读请求分散到多个从库上,从根本上解决读写冲突。
总结
MySQL查询缓存的兴衰史,是一部典型的软件架构演进史。它告诉我们:
没有一个解决方案是银弹,技术的选型必须与具体的应用场景和时代背景相结合。
查询缓存因其全局锁和粗粒度的失效机制,无法适应高并发OLTP系统的要求,从而被更优雅、更专业的应用层缓存和数据库内核优化所取代。理解它的原理与缺陷,不仅能帮助我们在维护老系统时游刃有余,更能指引我们设计出面向未来的、更健壮的系统架构。
如需获取更多关于MySQL 高级查询、索引优化、执行计划分析、数据库架构设计等内容,请持续关注本专栏《MySQL 深度探索》系列文章。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









