







 JDK1.8对HashMap进行了优化,引入了红黑树以提升在高冲突率时的查找性能。当链表节点超过8个且数组长度大于等于64时,链表转为红黑树。反之,当节点数减少到6个,且节点为红黑树时,会转回链表。这种改进降低了搜索时间复杂度,提高了数据结构的效率。
JDK1.8对HashMap进行了优化,引入了红黑树以提升在高冲突率时的查找性能。当链表节点超过8个且数组长度大于等于64时,链表转为红黑树。反之,当节点数减少到6个,且节点为红黑树时,会转回链表。这种改进降低了搜索时间复杂度,提高了数据结构的效率。
我们现在用的都是 JDK 1.8,底层是由“数组+链表+红黑树”组成,如下图,而在 JDK 1.8 之前是由“数组+链表”组成。
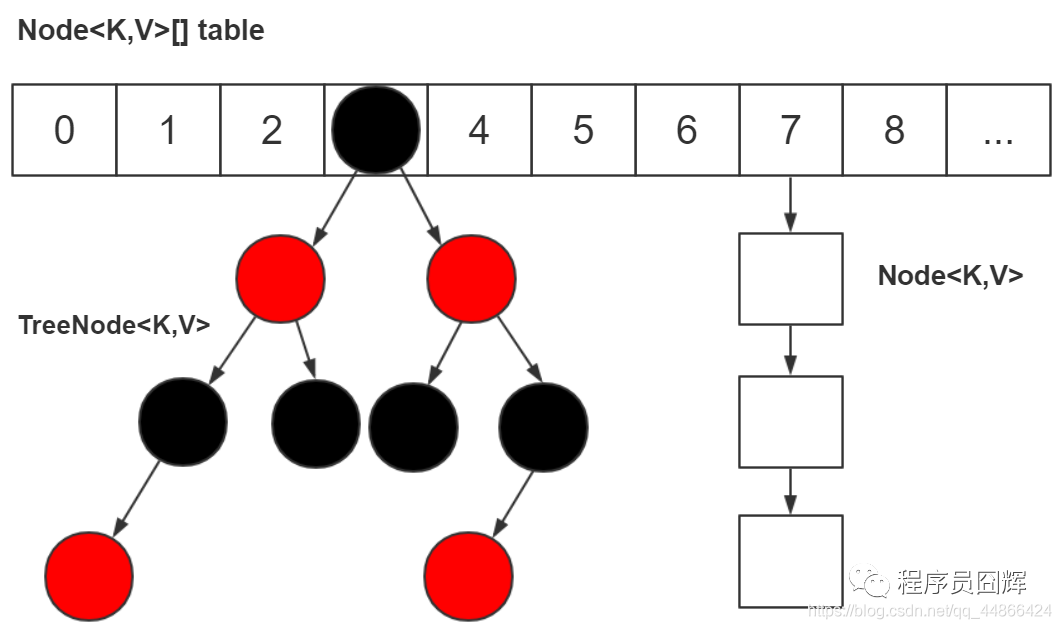
为什么要改成“数组+链表+红黑树”?
主要是为了提升在 hash 冲突严重时(链表过长)的查找性能,使用链表的查找性能是 O(n),而使用红黑树是 O(logn)。
那在什么时候用链表?什么时候用红黑树?
对于插入,默认情况下是使用链表节点。当同一个索引位置的节点在新增后超过8个(阈值8):如果此时数组长度大于等于 64,则会触发链表节点转红黑树节点(treeifyBin);而如果数组长度小于64,则不会触发链表转红黑树,而是会进行扩容,因为此时的数据量还比较小。
对于移除,当同一个索引位置的节点在移除后达到 6 个,并且该索引位置的节点为红黑树节点,会触发红黑树节点转链表节点(untreeify)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









