







强化学习(Reinforcement Learning,简称RL)是机器学习的一个重要分支,前段时间人机大战的主角AlphaGo正是以强化学习为核心技术。在强化学习中,包含两种基本的元素:状态与动作,在某个状态下执行某种动作,这便是一种策略,学习器要做的就是通过不断地探索学习,从而获得一个好的策略。例如:在围棋中,一种落棋的局面就是一种状态,若能知道每种局面下的最优落子动作,那就攻无不克/百战不殆了~
若将状态看作为属性,动作看作为标记,易知:监督学习和强化学习都是在试图寻找一个映射,从已知属性/状态推断出标记/动作,这样强化学习中的策略相当于监督学习中的分类/回归器。但在实际问题中,强化学习并没有监督学习那样的标记信息,通常都是在尝试动作后才能获得结果,因此强化学习是通过反馈的结果信息不断调整之前的策略,从而算法能够学习到:在什么样的状态下选择什么样的动作可以获得最好的结果。
16.1 基本要素
强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境中,每个状态为机器对当前环境的感知;机器只能通过动作来影响环境,当机器执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。综合而言,强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
状态(X):机器对环境的感知,所有可能的状态称为状态空间;
动作(A):机器所采取的动作,所有能采取的动作构成动作空间;
转移概率(P):当执行某个动作后,当前状态会以某种概率转移到另一个状态;
奖赏函数(R):在状态转移的同时,环境给反馈给机器一个奖赏。
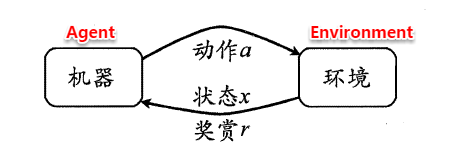
因此,强化学习的主要任务就是通过在环境中不断地尝试,根据尝试获得的反馈信息调整策略,最终生成一个较好的策略π,机器根据这个策略便能知道在什么状态下应该执行什么动作。常见的策略表示方法有以下两种:
确定性策略:π(x)=a,即在状态x下执行a动作;
随机性策略:P=π(x,a),即在状态x下执行a动作的概率。
一个策略的优劣取决于长期执行这一策略后的累积奖赏,换句话说:可以使用累积奖赏来评估策略的好坏,最优策略则表示在初始状态下一直执行该策略后,最后的累积奖赏值最高。长期累积奖赏通常使用下述两种计算方法:

强化学习在某种意义上可看 作具有"延迟标记信息"的监督学习问题.
16.2 K摇摆赌博机
首先我们考虑强化学习最简单的情形:仅考虑一步操作,即在状态x下只需执行一次动作a便能观察到奖赏结果。易知:欲最大化单步奖赏,我们需要知道每个动作带来的期望奖赏值,这样便能选择奖赏值最大的动作来执行。若每个动作的奖赏值为确定值,则只需要将每个动作尝试一遍即可,但大多数情形下,一个动作的奖赏值来源于一个概率分布,因此需要进行多次的尝试。
单步强化学习实质上是K-摇臂赌博机(K-armed bandit)的原型,一般我们尝试动作的次数是有限的,那如何利用有限的次数进行有效地探索呢?这里有两种基本的想法:
仅探索法:将尝试的机会平均分给每一个动作,即轮流执行,最终将每个动作的平均奖赏作为期望奖赏的近似值。
仅利用法:将尝试的机会分给当前平均奖赏值最大的动作,隐含着让一部分人先富起来的思想。
可以看出:上述两种方法是相互矛盾的,仅探索法能较好地估算每个动作的期望奖赏,但是没能根据当前的反馈结果调整尝试策略;仅利用法在每次尝试之后都更新尝试策略,符合强化学习的思(tao)维(lu),但容易找不到最优动作。因此需要在这两者之间进行折中。
16.2.1 ε-贪心
ε-贪心法基于一个概率来对探索和利用进行折中,具体而言:在每次尝试时,以ε的概率进行探索,即以均匀概率随机选择一个动作;以1-ε的概率进行利用,即选择当前最优的动作。ε-贪心法只需记录每个动作的当前平均奖赏值与被选中的次数,便可以增量式更新。

16.2.2 Softmax
Softmax算法则基于当前每个动作的平均奖赏值来对探索和利用进行折中,Softmax函数将一组值转化为一组概率,值越大对应的概率也越高,因此当前平均奖赏值越高的动作被选中的几率也越大。Softmax函数如下所示:


16.3 有模型学习
若学习任务中的四个要素都已知,即状态空间、动作空间、转移概率以及奖赏函数都已经给出,这样的情形称为“有模型学习”。假设状态空间和动作空间均为有限,即均为离散值,这样我们不用通过尝试便可以对某个策略进行评估。
16.3.1 策略评估
前面提到:在模型已知的前提下,我们可以对任意策略的进行评估(后续会给出演算过程)。一般常使用以下两种值函数来评估某个策略的优劣:
状态值函数(V):V(x),即从状态x出发,使用π策略所带来的累积奖赏;
状态-动作值函数(Q):Q(x,a),即从状态x出发,执行动作a后再使用π策略所带来的累积奖赏。
根据累积奖赏的定义,我们可以引入T步累积奖赏与r折扣累积奖赏:
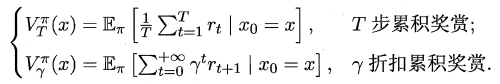
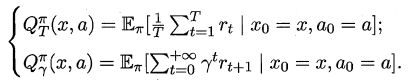
由于MDP具有马尔可夫性,即现在决定未来,将来和过去无关,我们很容易找到值函数的递归关系:

类似地,对于r折扣累积奖赏可以得到:
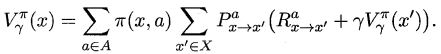
易知:当模型已知时,策略的评估问题转化为一种动态规划问题,即以填表格的形式自底向上,先求解每个状态的单步累积奖赏,再求解每个状态的两步累积奖赏,一直迭代逐步求解出每个状态的T步累积奖赏。算法流程如下所示:

对于状态-动作值函数,只需通过简单的转化便可得到:
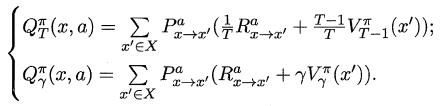
16.3.2 策略改进
对某个策略的累积奖赏进行评估后,若发现它并非最优策略,希望对其进行改进,理想的策略应能最大化累积奖赏:
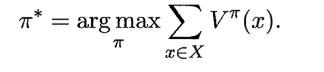
一个强化学习任务可能有多个最优策略,最优策略所对应的值函数 V* 称为最优值函数,即
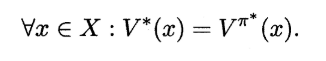
当策略空间无约束时上式 的 V* 才是最优策略对应的值函数,若策略空间有约束,则违背约束的策略是"不合法"的, 即便其值函数所取得的累积奖赏值最大,也不能作为最优值函数。

16.3.3 策略迭代与值迭代
从一个初始策略(通常是随机策略)出发,先进行策略评估,然后改进策略,评估改进的策略,再进一步改进策略,……不断迭代进行策略评估和改进,直到策略收敛、不再改变为止。这样的做法称为"策略迭代"

策略迭代算法在每次改进策略后都需重新进行策略评估,这通常比较耗时。 策略改进与值函数的改进是一致的,因此可将策略改进 视为值函数的改善:
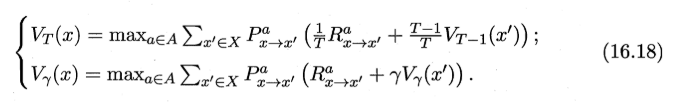
得到值迭代(value iteration)算法:

在模型已知时强化学习任务能归结为基于动态规划的寻优问题。与监督学习不同,这里并未涉及到泛化能力,而是为每一个状态找 到最好的动作。
16.4 免模型学习
16 .4 .1 蒙特卡罗强化学习
在现实的强化学习任务中,环境的转移函数与奖赏函数往往很难得知,因此我们需要考虑在不依赖于环境参数的条件下建立强化学习模型,这便是免模型学习。蒙特卡罗强化学习便是其中的一种经典方法。
由于模型参数未知,状态值函数不能像之前那样进行全概率展开,从而运用动态规划法求解。一种直接的方法便是通过采样来对策略进行评估/估算其值函数,蒙特卡罗强化学习正是基于采样来估计状态-动作值函数:对采样轨迹中的每一对状态-动作,记录其后的奖赏值之和,作为该状态-动作的一次累积奖赏,通过多次采样后,使用累积奖赏的平均作为状态-动作值的估计,并引入ε-贪心策略保证采样的多样性。

在上面的算法流程中,被评估和被改进的都是同一个策略,因此称为同策略蒙特卡罗强化学习算法。引入ε-贪心仅是为了便于采样评估,而在使用策略时并不需要ε-贪心,那能否仅在评估时使用ε-贪心策略,而在改进时使用原始策略呢?这便是异策略蒙特卡罗强化学习算法。

16.4.2 时序差分学习
蒙特卡罗强化学习算法通过考虑采样轨迹,克服了模型未知给策略估计造成的困难,.此类算法需在完成一个采样轨迹后再更新策略的值估计。蒙特卡罗强化学习算法没有充分利用强化学习任务的 MDP 结构,算法的效率很低,时序差分 (Temporal Difference,简称 TD) 学结合了动态规划与蒙特卡罗方法的思想,能做到更高效的免模型学习。

该算法由于每次更新值函数需知道前一步的状态(state)、前一步的动作(action)、奖赏值(reward)、当前状态(state)、将要执行的动作(action),由此得名为 Sarsa 算法。显然是同策略算法,算法中评估(第 6 行)、执行(第 5 行)的均为![]() 贪心策略。
贪心策略。

16.5 值函数近似
现实强化学习任务所面临的状态空间是连续的,有无群多个状态。离散化会遇到状态空间离散化的难题,实际上不妨直接对连续状态空间的值函数进行学习。显然无法用表格值函数来记录状态值,先考虑简单情形,即值函数能表达为状态的线性函数
![]()
由于此时的值函数难以像有限状态那样精确记录每个状态的值,因此这样值函数的求解被称为值函数近似。
基于线性值面数近似来替代 Sarsa 算法中的值函数,即可得到 线性值函数近似 Sarsa 算法.类似地可得到线性值函数近似 Q-学习算法。显然, 可以容易地用其他学习方法来代替上式中的线性学习器,例如通过引入核方法实现非线性值函数近似.

16.6 模仿学习
在强化学习的经典任务设置中,机器所能获得的反馈信息仅有多步决策后的累积奖赏,但在现实任务中,往往能得到人类专家的决策过程范例,例如在种瓜任务上能得到农业专家的种植过程范例.从这样的范例中学习,称为"模仿学习" (imitation "learning).
16.6.1 直接模仿学习
强化学习任务中多步决策的搜索空间巨大,基于累积奖赏来学习很多步之前的合适决策非常困难,而直接模仿人类专家的“状态-动作”可显著缓解这 一困难'我们称其为"直接模仿学习”。
把状态作为特征,动作作为标记;然后,对这个新构造出的数据集合 D 使用分类(对于离散动作)或回归(对于连续动作)算法即可学得策略模型。学得的这 个策略模型可作为机器进行强化学习的初始策略,再通过强化学习方法基于环境反馈进行改进,从而获得更好的策略。
16.6.2 逆强化学习
在很多任务中,设计奖赏函数往往相当困难,从人类专家提供的范例数据中反推出奖赏函数有助于解决该问题,这就是逆强化学习。
一个较好的办法是从随机策略开始,迭代地求解更好的奖赏函数,基于奖赏函数获得更好的策略,直至最终获得最符合范例轨迹数据集的奖赏函数和策略如下图。注意在求解更好的奖赏函数时,需将式(16.39)中对所有策略求最小改为对之前学得的策略求最小.
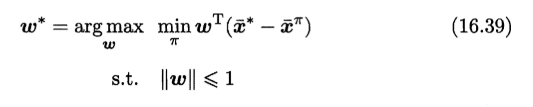





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











