






文章目录
前言: 拉开差距的不是上班的8小时,而是下班后的16小时,同志们,加油,卷起!!!
什么是 xpath
XPath 是一门在 XML 文档中查找信息的语言(路径语言)。XML 文档包括 HTML/XHTML、XML 和 XML Namespaces。你可以将 XPath 理解为在 XML/HTML 文档中检索和匹配元素节点的工具
python主要是通过 lxml 包来实现
安装scrapy
在pCharm终端中,输入以下命令进行包的安装
pip install lxml
pip install scrapy
xpath 使用
语法
| 表达式 | 说明 |
|---|---|
| / | 从根节点开始 |
| // | 从任意节点开始 |
| . | 选取当前的节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符, 表示任意节点或任意属性 |
常用函数
| 函数 | 说明 |
|---|---|
| contains () | //div[contains(@id,‘yrx’)] ,表示选择id中包含有’yrx’的div节点 |
| text() | 节点的文本 |
| starts-with() | //div[starts-with(@id,‘yrx’)] ,表示选择以’yrx’开头的id属性的div节点 |
| ends-with() | //div[ends-with(@id, ‘yrx’)], 选取 id 属性以 yrx结尾的 div 元素 |
| not(), and() | //div[@name=‘yrx’ and not(contains(@class,‘a’))], 表示匹配出name为yrx并且class的值中不包含a的div节点 |
| string() | 元素节点内部所有节点元素的文本内容 |
| position() | 选取位置 |
xpath demo实战
html结构
text = """
<html>
<table class='tab'>
<tr class = 'yrx'>
<td class = 'yrx1'>yrx1</td>
<td class = 'yrx2'>yrx2</td>
<td class = 'yrx3'>yrx3</td>
<td class = 'yrx4'>yrx4</td>
<td class = 'yrx5'>刘欢</td>
<td class = 'yrx6'>yrx6</td>
</tr>
</table>
<a>这是table外的标签</a>
</html>
"""
demo01
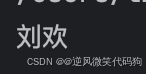
:查找出
class = 'yrx5'的文本,也就是获取刘欢两个字
from scrapy.selector import Selector
html = etree.fromstring(text)
result = html.xpath("//td[@class='yrx5']/text()").get()
print(result)
输出结果
demo02
查找class = 'yrx'的父级
from scrapy.selector import Selector
html = Selector(text=text)
result = html.xpath("/tr[@class='yrx']/..")
print(result)
输出结果

demo03
只要第tr下第3个标签以后的td
from scrapy.selector import Selector
html = Selector(text=text)
result = html.xpath("//tr[@class='yrx']/td[position() > 3]").getall()
print(result)

demo04
查询tr下的所有标签
from scrapy.selector import Selector
html = Selector(text=text)
result = html.xpath("//tr[@class='yrx']/child::*").getall()
print(result)

demo05
选取文档中class='yrx3'节点的结束标签之后的所有节点.
from scrapy.selector import Selector
html = Selector(text=text)
result = html.xpath("//tr[@class='yrx3']/following::*").getall()
print(result)

demo07
选取文档中class='yrx3'节点的结束标签之前的所有节点.
from scrapy.selector import Selector
html = Selector(text=text)
result = html.xpath("//tr[@class='yrx3']/preceding::*").getall()
print(result)

demo08
查找出td包含yrx的标签
from scrapy.selector import Selector
html = Selector(text=text)
result = html.xpath("//td[contains(@class, 'yrx')]").getall()
print(result)

demo09
查找出td包含class='yrx4'的标签的兄弟节点
from scrapy.selector import Selector
html = Selector(text=text)
result = html.xpath("//td[@class='yrx3']/following-sibling::*").getall()
print(result)

demo10
正则表达式:匹配yrx开头的类名
from scrapy.selector import Selector
html = Selector(text=text)
result = html.xpath("//td[re:match(@class, 'yrx\d+')]").getall()
print(result)

demo11
不要td标签里是刘欢的
from scrapy.selector import Selector
html = Selector(text=text)
result = html.xpath("//td[contains(@class, 'yrx') and not(contains(text(), '平哥')) ]").getall()
print(result)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









